 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Catalog of Basque Dialectal Resources: Online Collections and Standard-to-Dialectal Adaptations
Mar 26, 2026Recent research on dialectal NLP has identified data scarcity as a primary limitation. To address this limitation, this paper presents a catalog of contemporary Basque dialectal data and resources, offering a systematic and comprehensive compilation of the dialectal data currently available in Basque. Two types of data sources have been distinguished: online data originally written in some dialect, and standard-to-dialect adapted data. The former includes all dialectal data that can be found online, such as news and radio sites, informal tweets, as well as online resources such as dictionaries, atlases, grammar rules, or videos. The latter consists of data that has been adapted from the standard variety to dialectal varieties, either manually or automatically. Regarding the manual adaptation, the test split of the XNLI Natural Language Inference dataset was manually adapted into three Basque dialects: Western, Central, and Navarrese-Lapurdian, yielding a high-quality parallel gold standard evaluation dataset. With respect to the automatic dialectal adaptation, the automatically adapted physical commonsense dataset (BasPhyCowest) underwent additional manual evaluation by native speakers to assess its quality and determine whether it could serve as a viable substitute for full manual adaptation (i.e., silver data creation).
Physical Commonsense Reasoning for Lower-Resourced Languages and Dialects: a Study on Basque
Feb 16, 2026Physical commonsense reasoning represents a fundamental capability of human intelligence, enabling individuals to understand their environment, predict future events, and navigate physical spaces. Recent years have witnessed growing interest in reasoning tasks within Natural Language Processing (NLP). However, no prior research has examined the performance of Large Language Models (LLMs) on non-question-answering (non-QA) physical commonsense reasoning tasks in low-resource languages such as Basque. Taking the Italian GITA as a starting point, this paper addresses this gap by presenting BasPhyCo, the first non-QA physical commonsense reasoning dataset for Basque, available in both standard and dialectal variants. We evaluate model performance across three hierarchical levels of commonsense understanding: (1) distinguishing between plausible and implausible narratives (accuracy), (2) identifying the conflicting element that renders a narrative implausible (consistency), and (3) determining the specific physical state that creates the implausibility (verifiability). These tasks were assessed using multiple multilingual LLMs as well as models pretrained specifically for Italian and Basque. Results indicate that, in terms of verifiability, LLMs exhibit limited physical commonsense capabilities in low-resource languages such as Basque, especially when processing dialectal variants.
Lost in Variation? Evaluating NLI Performance in Basque and Spanish Geographical Variants
Jun 18, 2025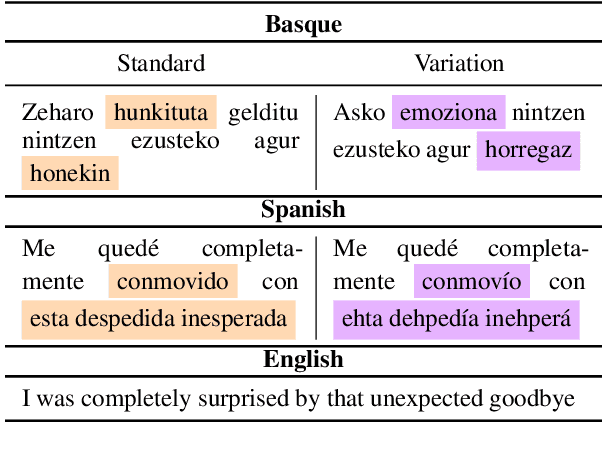
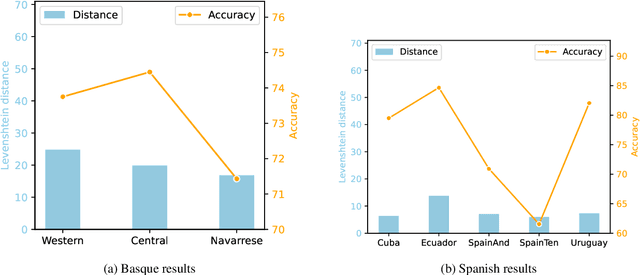

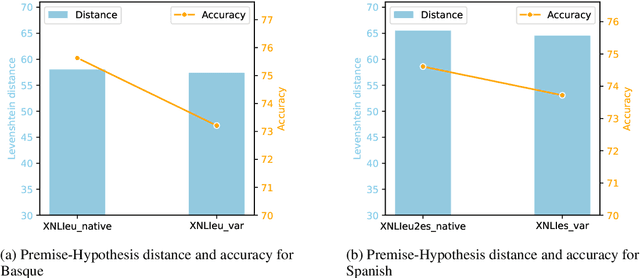
In this paper, we evaluate the capacity of current language technologies to understand Basque and Spanish language varieties. We use Natural Language Inference (NLI) as a pivot task and introduce a novel, manually-curated parallel dataset in Basque and Spanish, along with their respective variants. Our empirical analysis of crosslingual and in-context learning experiments using encoder-only and decoder-based Large Language Models (LLMs) shows a performance drop when handling linguistic variation, especially in Basque. Error analysis suggests that this decline is not due to lexical overlap, but rather to the linguistic variation itself. Further ablation experiments indicate that encoder-only models particularly struggle with Western Basque, which aligns with linguistic theory that identifies peripheral dialects (e.g., Western) as more distant from the standard. All data and code are publicly available.
LengClaro2023: A Dataset of Administrative Texts in Spanish with Plain Language adaptations
Jun 06, 2025In this work, we present LengClaro2023, a dataset of legal-administrative texts in Spanish. Based on the most frequently used procedures from the Spanish Social Security website, we have created for each text two simplified equivalents. The first version follows the recommendations provided by arText claro. The second version incorporates additional recommendations from plain language guidelines to explore further potential improvements in the system. The linguistic resource created in this work can be used for evaluating automatic text simplification (ATS) systems in Spanish.
A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models
May 17, 2024In this work, we explore idiomatic language processing with Large Language Models (LLMs). We introduce the Idiomatic language Test Suite IdioTS, a new dataset of difficult examples specifically designed by language experts to assess the capabilities of LLMs to process figurative language at sentence level. We propose a comprehensive evaluation methodology based on an idiom detection task, where LLMs are prompted with detecting an idiomatic expression in a given English sentence. We present a thorough automatic and manual evaluation of the results and an extensive error analysis.
This is not a Dataset: A Large Negation Benchmark to Challenge Large Language Models
Oct 24, 2023Although large language models (LLMs) have apparently acquired a certain level of grammatical knowledge and the ability to make generalizations, they fail to interpret negation, a crucial step in Natural Language Processing. We try to clarify the reasons for the sub-optimal performance of LLMs understanding negation. We introduce a large semi-automatically generated dataset of circa 400,000 descriptive sentences about commonsense knowledge that can be true or false in which negation is present in about 2/3 of the corpus in different forms. We have used our dataset with the largest available open LLMs in a zero-shot approach to grasp their generalization and inference capability and we have also fine-tuned some of the models to assess whether the understanding of negation can be trained. Our findings show that, while LLMs are proficient at classifying affirmative sentences, they struggle with negative sentences and lack a deep understanding of negation, often relying on superficial cues. Although fine-tuning the models on negative sentences improves their performance, the lack of generalization in handling negation is persistent, highlighting the ongoing challenges of LLMs regarding negation understanding and generalization. The dataset and code are publicly available.
Easy-to-Read in Germany: A Survey on its Current State and Available Resources
Jun 05, 2023Easy-to-Read Language (E2R) is a controlled language variant that makes any written text more accessible through the use of clear, direct and simple language. It is mainly aimed at people with cognitive or intellectual disabilities, among other target users. Plain Language (PL), on the other hand, is a variant of a given language, which aims to promote the use of simple language to communicate information. German counts with Leichte Sprache (LS), its version of E2R, and Einfache Sprache (ES), its version of PL. In recent years, important developments have been conducted in the field of LS. This paper offers an updated overview of the existing Natural Language Processing (NLP) tools and resources for LS. Besides, it also aims to set out the situation with regard to LS and ES in Germany.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023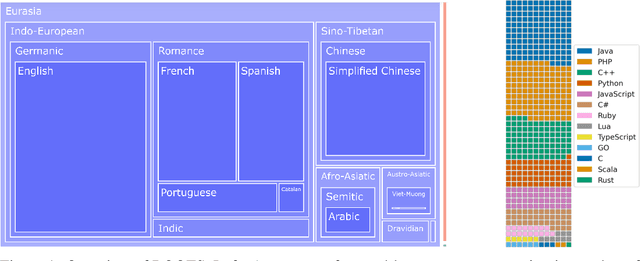

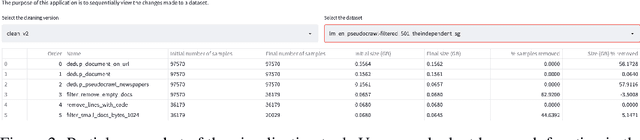

As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Noisy Channel for Automatic Text Simplification
Nov 06, 2022In this paper we present a simple re-ranking method for Automatic Sentence Simplification based on the noisy channel scheme. Instead of directly computing the best simplification given a complex text, the re-ranking method also considers the probability of the simple sentence to produce the complex counterpart, as well as the probability of the simple text itself, according to a language model. Our experiments show that combining these scores outperform the original system in three different English datasets, yielding the best known result in one of them. Adopting the noisy channel scheme opens new ways to infuse additional information into ATS systems, and thus to control important aspects of them, a known limitation of end-to-end neural seq2seq generative models.