 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy-to-Read in Germany: A Survey on its Current State and Available Resources
Jun 05, 2023Easy-to-Read Language (E2R) is a controlled language variant that makes any written text more accessible through the use of clear, direct and simple language. It is mainly aimed at people with cognitive or intellectual disabilities, among other target users. Plain Language (PL), on the other hand, is a variant of a given language, which aims to promote the use of simple language to communicate information. German counts with Leichte Sprache (LS), its version of E2R, and Einfache Sprache (ES), its version of PL. In recent years, important developments have been conducted in the field of LS. This paper offers an updated overview of the existing Natural Language Processing (NLP) tools and resources for LS. Besides, it also aims to set out the situation with regard to LS and ES in Germany.
Challenges of the Creation of a Dataset for Vision Based Human Hand Action Recognition in Industrial Assembly
Mar 07, 2023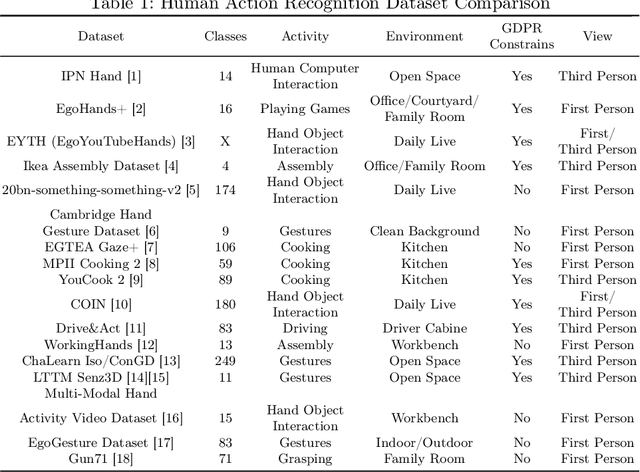

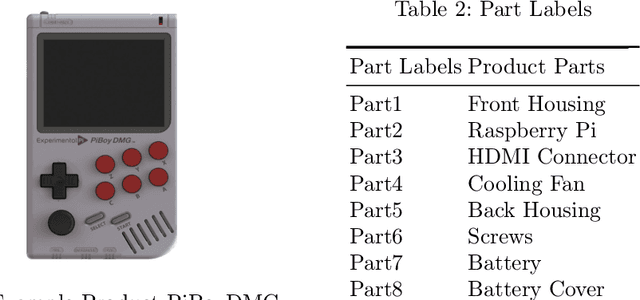

This work presents the Industrial Hand Action Dataset V1, an industrial assembly dataset consisting of 12 classes with 459,180 images in the basic version and 2,295,900 images after spatial augmentation. Compared to other freely available datasets tested, it has an above-average duration and, in addition, meets the technical and legal requirements for industrial assembly lines. Furthermore, the dataset contains occlusions, hand-object interaction, and various fine-grained human hand actions for industrial assembly tasks that were not found in combination in examined datasets. The recorded ground truth assembly classes were selected after extensive observation of real-world use cases. A Gated Transformer Network, a state-of-the-art model from the transformer domain was adapted, and proved with a test accuracy of 86.25% before hyperparameter tuning by 18,269,959 trainable parameters, that it is possible to train sequential deep learning models with this dataset.
Efficient Deep Processing of Japanese
Jul 03, 2002We present a broad coverage Japanese grammar written in the HPSG formalism with MRS semantics. The grammar is created for use in real world applications, such that robustness and performance issues play an important role. It is connected to a POS tagging and word segmentation tool. This grammar is being developed in a multilingual context, requiring MRS structures that are easily comparable across languages.
The syntactic processing of particles in Japanese spoken language
Jun 02, 1999
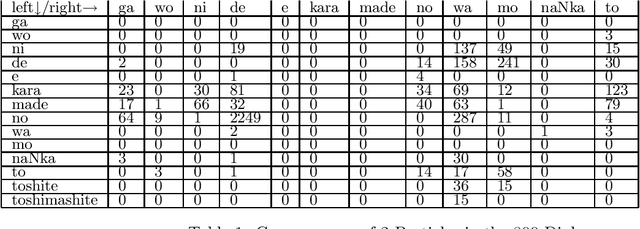
Particles fullfill several distinct central roles in the Japanese language. They can mark arguments as well as adjuncts, can be functional or have semantic funtions. There is, however, no straightforward matching from particles to functions, as, e.g., GA can mark the subject, the object or an adjunct of a sentence. Particles can cooccur. Verbal arguments that could be identified by particles can be eliminated in the Japanese sentence. And finally, in spoken language particles are often omitted. A proper treatment of particles is thus necessary to make an analysis of Japanese sentences possible. Our treatment is based on an empirical investigation of 800 dialogues. We set up a type hierarchy of particles motivated by their subcategorizational and modificational behaviour. This type hierarchy is part of the Japanese syntax in VERBMOBIL.
* 8 pages