 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow should the advent of large language models affect the practice of science?
Dec 05, 2023Large language models (LLMs) are being increasingly incorporated into scientific workflows. However, we have yet to fully grasp the implications of this integration. How should the advent of large language models affect the practice of science? For this opinion piece, we have invited four diverse groups of scientists to reflect on this query, sharing their perspectives and engaging in debate. Schulz et al. make the argument that working with LLMs is not fundamentally different from working with human collaborators, while Bender et al. argue that LLMs are often misused and over-hyped, and that their limitations warrant a focus on more specialized, easily interpretable tools. Marelli et al. emphasize the importance of transparent attribution and responsible use of LLMs. Finally, Botvinick and Gershman advocate that humans should retain responsibility for determining the scientific roadmap. To facilitate the discussion, the four perspectives are complemented with a response from each group. By putting these different perspectives in conversation, we aim to bring attention to important considerations within the academic community regarding the adoption of LLMs and their impact on both current and future scientific practices.
AI and the Everything in the Whole Wide World Benchmark
Nov 26, 2021
There is a tendency across different subfields in AI to valorize a small collection of influential benchmarks. These benchmarks operate as stand-ins for a range of anointed common problems that are frequently framed as foundational milestones on the path towards flexible and generalizable AI systems. State-of-the-art performance on these benchmarks is widely understood as indicative of progress towards these long-term goals. In this position paper, we explore the limits of such benchmarks in order to reveal the construct validity issues in their framing as the functionally "general" broad measures of progress they are set up to be.
Data and its contents: A survey of dataset development and use in machine learning research
Dec 09, 2020Datasets have played a foundational role in the advancement of machine learning research. They form the basis for the models we design and deploy, as well as our primary medium for benchmarking and evaluation. Furthermore, the ways in which we collect, construct and share these datasets inform the kinds of problems the field pursues and the methods explored in algorithm development. However, recent work from a breadth of perspectives has revealed the limitations of predominant practices in dataset collection and use. In this paper, we survey the many concerns raised about the way we collect and use data in machine learning and advocate that a more cautious and thorough understanding of data is necessary to address several of the practical and ethical issues of the field.
Neural Text Generation from Rich Semantic Representations
Apr 25, 2019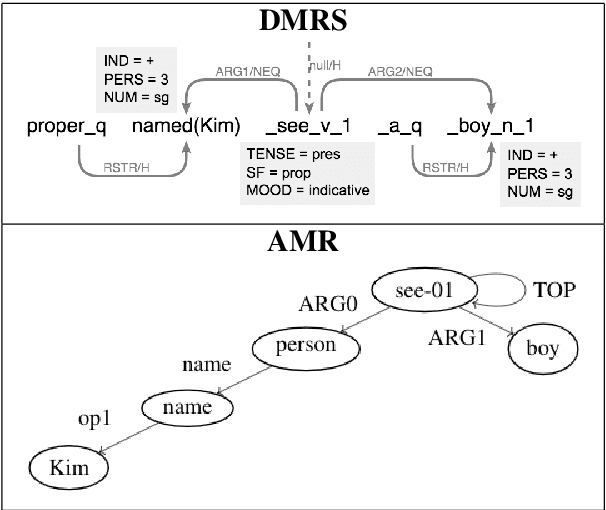
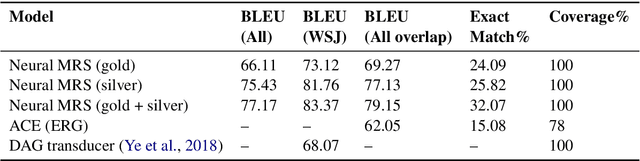

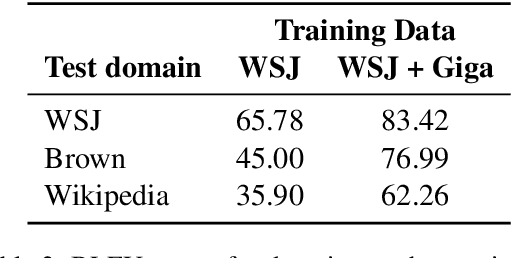
We propose neural models to generate high-quality text from structured representations based on Minimal Recursion Semantics (MRS). MRS is a rich semantic representation that encodes more precise semantic detail than other representations such as Abstract Meaning Representation (AMR). We show that a sequence-to-sequence model that maps a linearization of Dependency MRS, a graph-based representation of MRS, to English text can achieve a BLEU score of 66.11 when trained on gold data. The performance can be improved further using a high-precision, broad coverage grammar-based parser to generate a large silver training corpus, achieving a final BLEU score of 77.17 on the full test set, and 83.37 on the subset of test data most closely matching the silver data domain. Our results suggest that MRS-based representations are a good choice for applications that need both structured semantics and the ability to produce natural language text as output.
Towards Linguistically Generalizable NLP Systems: A Workshop and Shared Task
Nov 04, 2017
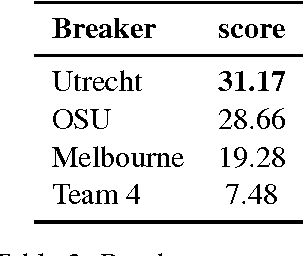

This paper presents a summary of the first Workshop on Building Linguistically Generalizable Natural Language Processing Systems, and the associated Build It Break It, The Language Edition shared task. The goal of this workshop was to bring together researchers in NLP and linguistics with a shared task aimed at testing the generalizability of NLP systems beyond the distributions of their training data. We describe the motivation, setup, and participation of the shared task, provide discussion of some highlighted results, and discuss lessons learned.
Efficient Deep Processing of Japanese
Jul 03, 2002We present a broad coverage Japanese grammar written in the HPSG formalism with MRS semantics. The grammar is created for use in real world applications, such that robustness and performance issues play an important role. It is connected to a POS tagging and word segmentation tool. This grammar is being developed in a multilingual context, requiring MRS structures that are easily comparable across languages.