 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoUnD Framework: Analyzing (So)cial Representation in (Un)structured (D)ata
Dec 01, 2023The unstructured nature of data used in foundation model development is a challenge to systematic analyses for making data use and documentation decisions. From a Responsible AI perspective, these decisions often rely upon understanding how people are represented in data. We propose a framework designed to guide analysis of human representation in unstructured data and identify downstream risks. We apply the framework in two toy examples using the Common Crawl web text corpus (C4) and LAION-400M. We also propose a set of hypothetical action steps in service of dataset use, development, and documentation.
AI's Regimes of Representation: A Community-centered Study of Text-to-Image Models in South Asia
May 19, 2023



This paper presents a community-centered study of cultural limitations of text-to-image (T2I) models in the South Asian context. We theorize these failures using scholarship on dominant media regimes of representations and locate them within participants' reporting of their existing social marginalizations. We thus show how generative AI can reproduce an outsiders gaze for viewing South Asian cultures, shaped by global and regional power inequities. By centering communities as experts and soliciting their perspectives on T2I limitations, our study adds rich nuance into existing evaluative frameworks and deepens our understanding of the culturally-specific ways AI technologies can fail in non-Western and Global South settings. We distill lessons for responsible development of T2I models, recommending concrete pathways forward that can allow for recognition of structural inequalities.
City-Wide Perceptions of Neighbourhood Quality using Street View Images
Nov 24, 2022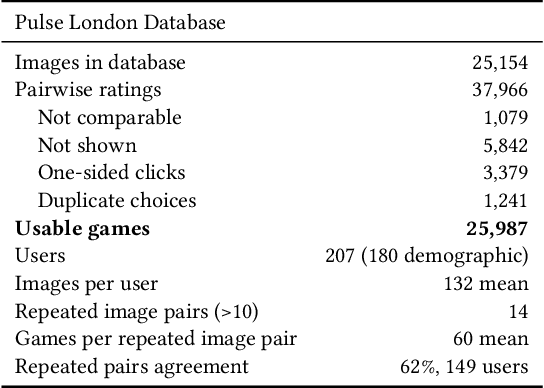

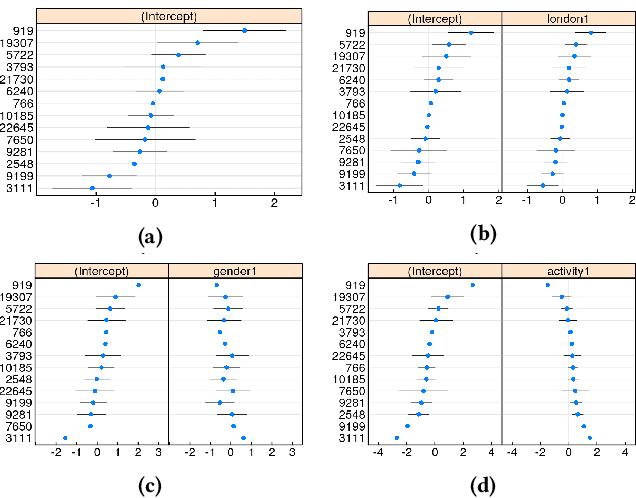

The interactions of individuals with city neighbourhoods is determined, in part, by the perceived quality of urban environments. Perceived neighbourhood quality is a core component of urban vitality, influencing social cohesion, sense of community, safety, activity and mental health of residents. Large-scale assessment of perceptions of neighbourhood quality was pioneered by the Place Pulse projects. Researchers demonstrated the efficacy of crowd-sourcing perception ratings of image pairs across 56 cities and training a model to predict perceptions from street-view images. Variation across cities may limit Place Pulse's usefulness for assessing within-city perceptions. In this paper, we set forth a protocol for city-specific dataset collection for the perception: 'On which street would you prefer to walk?'. This paper describes our methodology, based in London, including collection of images and ratings, web development, model training and mapping. Assessment of within-city perceptions of neighbourhoods can identify inequities, inform planning priorities, and identify temporal dynamics. Code available: https://emilymuller1991.github.io/urban-perceptions/.
CrowdWorkSheets: Accounting for Individual and Collective Identities Underlying Crowdsourced Dataset Annotation
Jun 09, 2022Human annotated data plays a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into dataset annotation have not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms, and what that relationship affords them. Finally, we introduce a novel framework, CrowdWorkSheets, for dataset developers to facilitate transparent documentation of key decisions points at various stages of the data annotation pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset release and maintenance.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

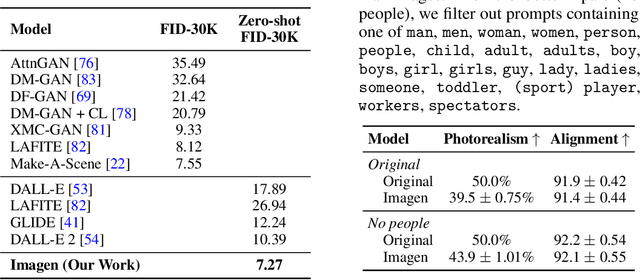
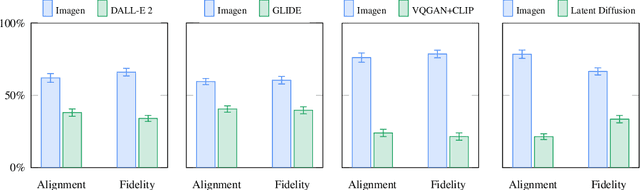
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Whose Ground Truth? Accounting for Individual and Collective Identities Underlying Dataset Annotation
Dec 08, 2021Human annotations play a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into building ML datasets has not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms and what that relationship affords them. Finally, we put forth a concrete set of recommendations and considerations for dataset developers at various stages of the ML data pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset documentation and release.
Ethics and Creativity in Computer Vision
Dec 06, 2021This paper offers a retrospective of what we learnt from organizing the workshop *Ethical Considerations in Creative applications of Computer Vision* at CVPR 2021 conference and, prior to that, a series of workshops on *Computer Vision for Fashion, Art and Design* at ECCV 2018, ICCV 2019, and CVPR 2020. We hope this reflection will bring artists and machine learning researchers into conversation around the ethical and social dimensions of creative applications of computer vision.
* Neural Information Processing System 2021 workshop on Machine Learning for Creativity and Design
Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research
Dec 03, 2021
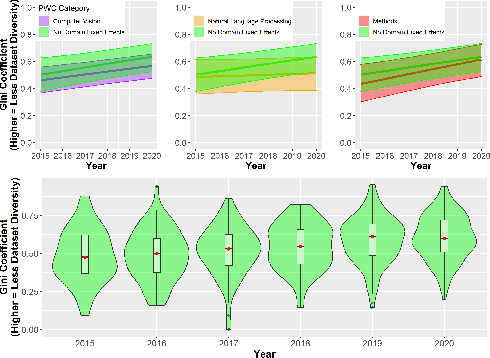
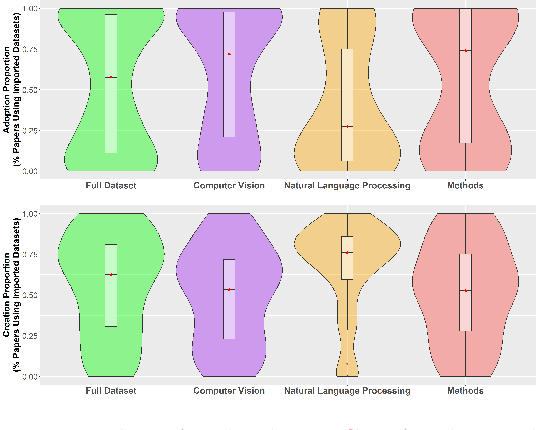
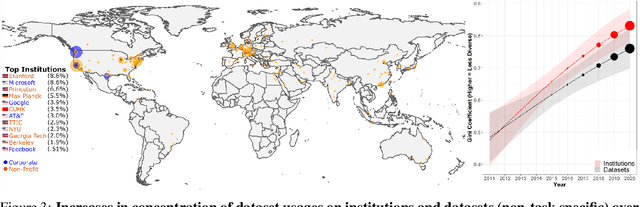
Benchmark datasets play a central role in the organization of machine learning research. They coordinate researchers around shared research problems and serve as a measure of progress towards shared goals. Despite the foundational role of benchmarking practices in this field, relatively little attention has been paid to the dynamics of benchmark dataset use and reuse, within or across machine learning subcommunities. In this paper, we dig into these dynamics. We study how dataset usage patterns differ across machine learning subcommunities and across time from 2015-2020. We find increasing concentration on fewer and fewer datasets within task communities, significant adoption of datasets from other tasks, and concentration across the field on datasets that have been introduced by researchers situated within a small number of elite institutions. Our results have implications for scientific evaluation, AI ethics, and equity/access within the field.
AI and the Everything in the Whole Wide World Benchmark
Nov 26, 2021
There is a tendency across different subfields in AI to valorize a small collection of influential benchmarks. These benchmarks operate as stand-ins for a range of anointed common problems that are frequently framed as foundational milestones on the path towards flexible and generalizable AI systems. State-of-the-art performance on these benchmarks is widely understood as indicative of progress towards these long-term goals. In this position paper, we explore the limits of such benchmarks in order to reveal the construct validity issues in their framing as the functionally "general" broad measures of progress they are set up to be.
Do Datasets Have Politics? Disciplinary Values in Computer Vision Dataset Development
Aug 09, 2021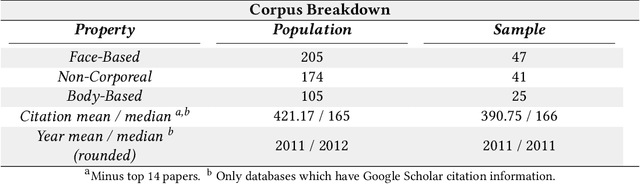
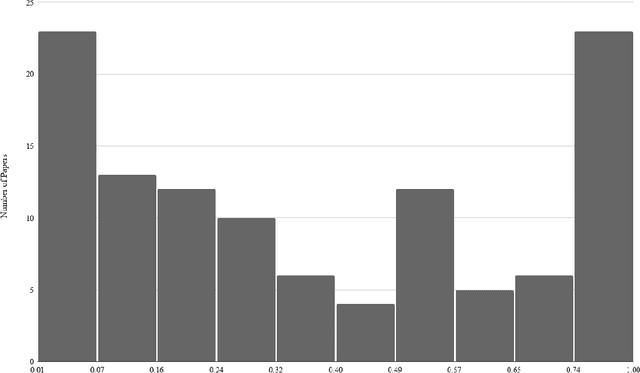
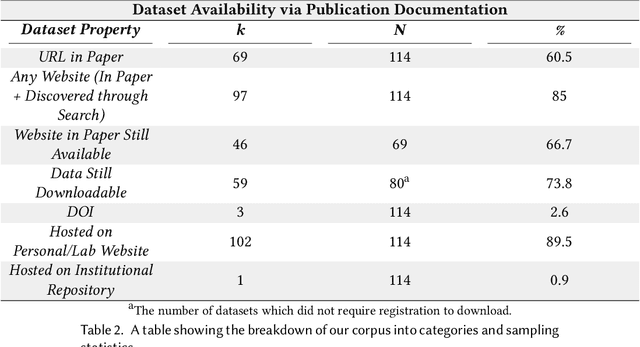
Data is a crucial component of machine learning. The field is reliant on data to train, validate, and test models. With increased technical capabilities, machine learning research has boomed in both academic and industry settings, and one major focus has been on computer vision. Computer vision is a popular domain of machine learning increasingly pertinent to real-world applications, from facial recognition in policing to object detection for autonomous vehicles. Given computer vision's propensity to shape machine learning research and impact human life, we seek to understand disciplinary practices around dataset documentation - how data is collected, curated, annotated, and packaged into datasets for computer vision researchers and practitioners to use for model tuning and development. Specifically, we examine what dataset documentation communicates about the underlying values of vision data and the larger practices and goals of computer vision as a field. To conduct this study, we collected a corpus of about 500 computer vision datasets, from which we sampled 114 dataset publications across different vision tasks. Through both a structured and thematic content analysis, we document a number of values around accepted data practices, what makes desirable data, and the treatment of humans in the dataset construction process. We discuss how computer vision datasets authors value efficiency at the expense of care; universality at the expense of contextuality; impartiality at the expense of positionality; and model work at the expense of data work. Many of the silenced values we identify sit in opposition with social computing practices. We conclude with suggestions on how to better incorporate silenced values into the dataset creation and curation process.
* CSCW 2021; 37 pages