 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCity-Wide Perceptions of Neighbourhood Quality using Street View Images
Nov 24, 2022

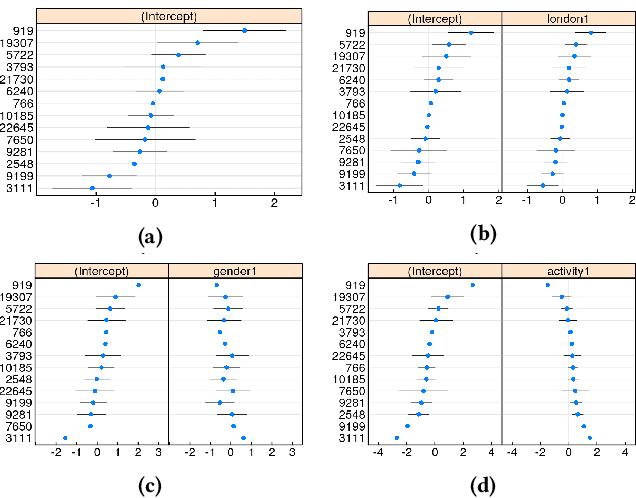

The interactions of individuals with city neighbourhoods is determined, in part, by the perceived quality of urban environments. Perceived neighbourhood quality is a core component of urban vitality, influencing social cohesion, sense of community, safety, activity and mental health of residents. Large-scale assessment of perceptions of neighbourhood quality was pioneered by the Place Pulse projects. Researchers demonstrated the efficacy of crowd-sourcing perception ratings of image pairs across 56 cities and training a model to predict perceptions from street-view images. Variation across cities may limit Place Pulse's usefulness for assessing within-city perceptions. In this paper, we set forth a protocol for city-specific dataset collection for the perception: 'On which street would you prefer to walk?'. This paper describes our methodology, based in London, including collection of images and ratings, web development, model training and mapping. Assessment of within-city perceptions of neighbourhoods can identify inequities, inform planning priorities, and identify temporal dynamics. Code available: https://emilymuller1991.github.io/urban-perceptions/.
Evaluation of the Synthetic Electronic Health Records
Oct 16, 2022
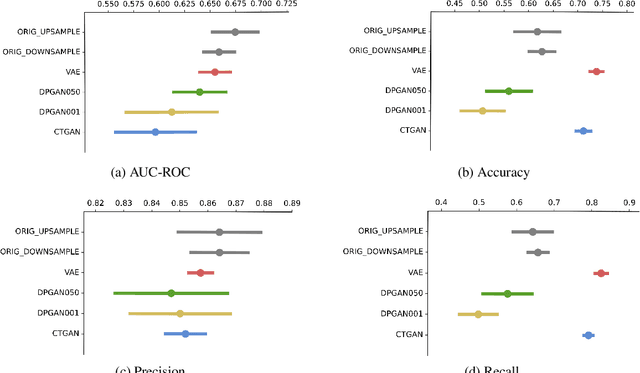
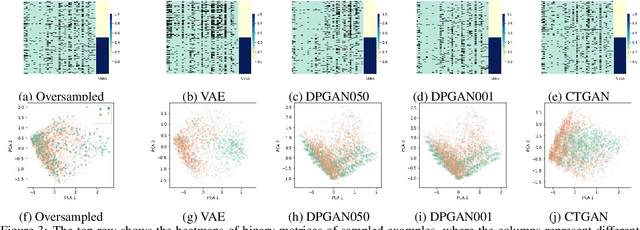
Generative models have been found effective for data synthesis due to their ability to capture complex underlying data distributions. The quality of generated data from these models is commonly evaluated by visual inspection for image datasets or downstream analytical tasks for tabular datasets. These evaluation methods neither measure the implicit data distribution nor consider the data privacy issues, and it remains an open question of how to compare and rank different generative models. Medical data can be sensitive, so it is of great importance to draw privacy concerns of patients while maintaining the data utility of the synthetic dataset. Beyond the utility evaluation, this work outlines two metrics called Similarity and Uniqueness for sample-wise assessment of synthetic datasets. We demonstrate the proposed notions with several state-of-the-art generative models to synthesise Cystic Fibrosis (CF) patients' electronic health records (EHRs), observing that the proposed metrics are suitable for synthetic data evaluation and generative model comparison.
Synthesising Electronic Health Records: Cystic Fibrosis Patient Group
Jan 14, 2022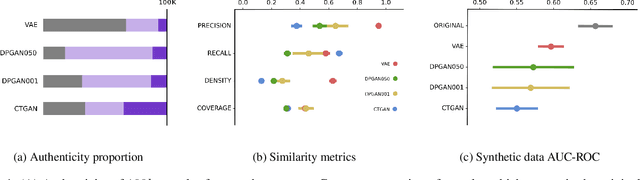
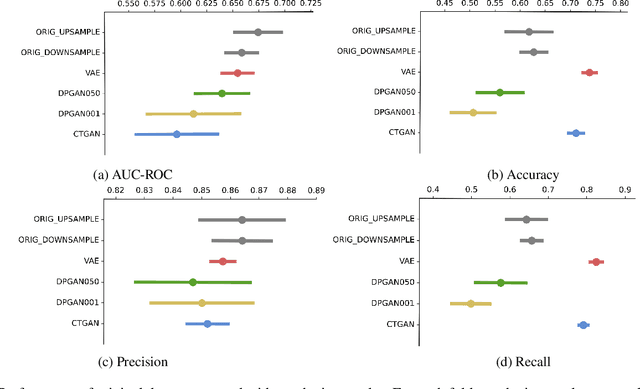

Class imbalance can often degrade predictive performance of supervised learning algorithms. Balanced classes can be obtained by oversampling exact copies, with noise, or interpolation between nearest neighbours (as in traditional SMOTE methods). Oversampling tabular data using augmentation, as is typical in computer vision tasks, can be achieved with deep generative models. Deep generative models are effective data synthesisers due to their ability to capture complex underlying distributions. Synthetic data in healthcare can enhance interoperability between healthcare providers by ensuring patient privacy. Equipped with large synthetic datasets which do well to represent small patient groups, machine learning in healthcare can address the current challenges of bias and generalisability. This paper evaluates synthetic data generators ability to synthesise patient electronic health records. We test the utility of synthetic data for patient outcome classification, observing increased predictive performance when augmenting imbalanced datasets with synthetic data.