 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesising Electronic Health Records: Cystic Fibrosis Patient Group
Paper and Code
Jan 14, 2022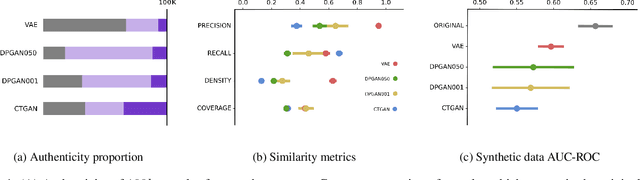
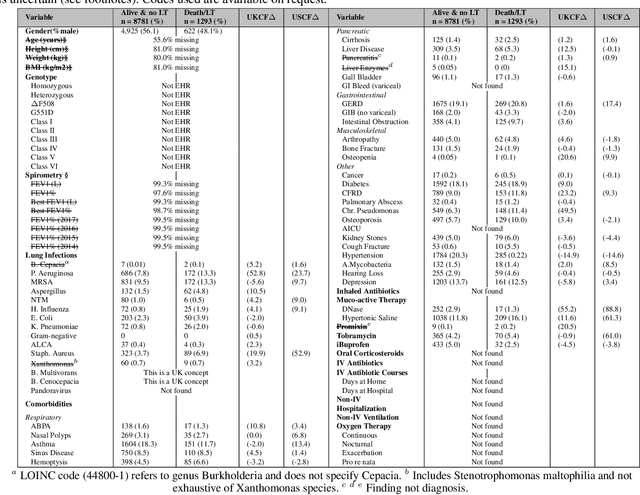
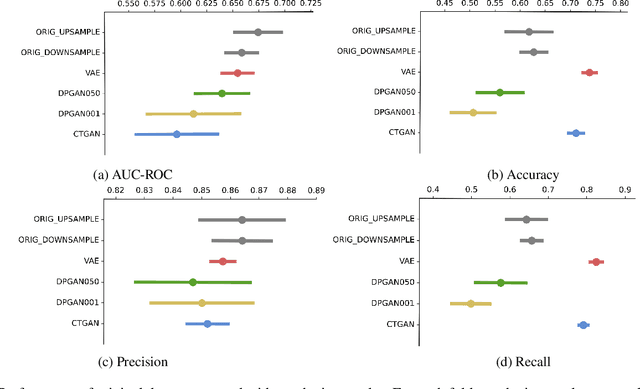

Class imbalance can often degrade predictive performance of supervised learning algorithms. Balanced classes can be obtained by oversampling exact copies, with noise, or interpolation between nearest neighbours (as in traditional SMOTE methods). Oversampling tabular data using augmentation, as is typical in computer vision tasks, can be achieved with deep generative models. Deep generative models are effective data synthesisers due to their ability to capture complex underlying distributions. Synthetic data in healthcare can enhance interoperability between healthcare providers by ensuring patient privacy. Equipped with large synthetic datasets which do well to represent small patient groups, machine learning in healthcare can address the current challenges of bias and generalisability. This paper evaluates synthetic data generators ability to synthesise patient electronic health records. We test the utility of synthetic data for patient outcome classification, observing increased predictive performance when augmenting imbalanced datasets with synthetic data.