 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdWorkSheets: Accounting for Individual and Collective Identities Underlying Crowdsourced Dataset Annotation
Jun 09, 2022Human annotated data plays a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into dataset annotation have not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms, and what that relationship affords them. Finally, we introduce a novel framework, CrowdWorkSheets, for dataset developers to facilitate transparent documentation of key decisions points at various stages of the data annotation pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset release and maintenance.
Is Your Toxicity My Toxicity? Exploring the Impact of Rater Identity on Toxicity Annotation
May 01, 2022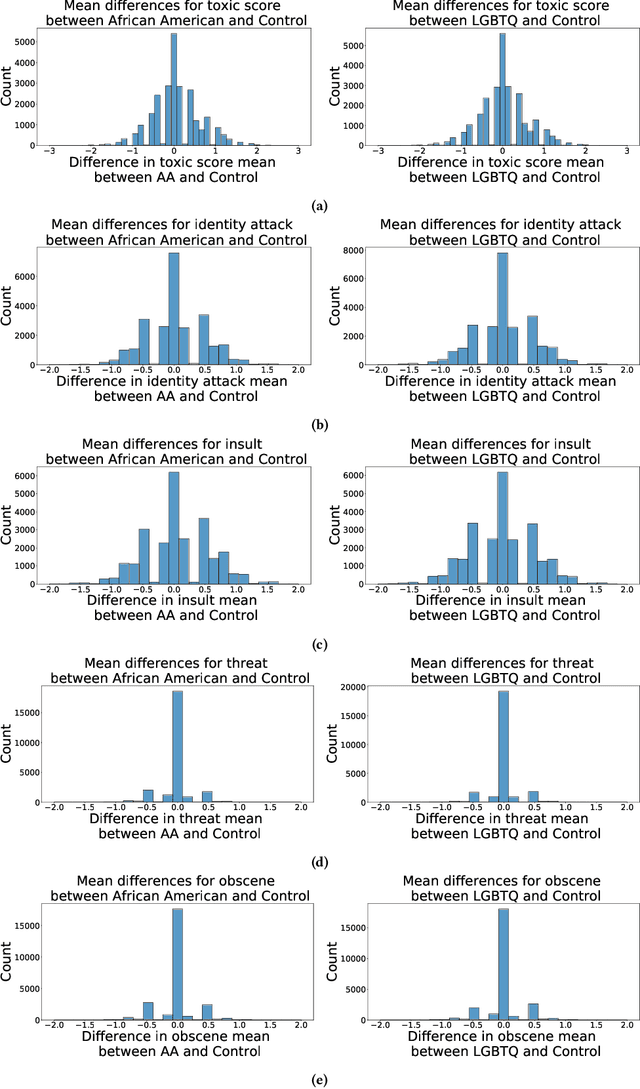

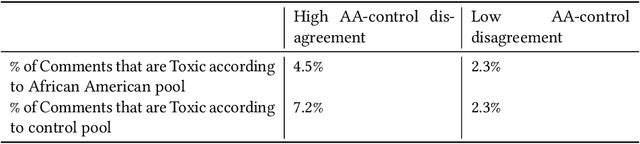

Machine learning models are commonly used to detect toxicity in online conversations. These models are trained on datasets annotated by human raters. We explore how raters' self-described identities impact how they annotate toxicity in online comments. We first define the concept of specialized rater pools: rater pools formed based on raters' self-described identities, rather than at random. We formed three such rater pools for this study--specialized rater pools of raters from the U.S. who identify as African American, LGBTQ, and those who identify as neither. Each of these rater pools annotated the same set of comments, which contains many references to these identity groups. We found that rater identity is a statistically significant factor in how raters will annotate toxicity for identity-related annotations. Using preliminary content analysis, we examined the comments with the most disagreement between rater pools and found nuanced differences in the toxicity annotations. Next, we trained models on the annotations from each of the different rater pools, and compared the scores of these models on comments from several test sets. Finally, we discuss how using raters that self-identify with the subjects of comments can create more inclusive machine learning models, and provide more nuanced ratings than those by random raters.
Whose Ground Truth? Accounting for Individual and Collective Identities Underlying Dataset Annotation
Dec 08, 2021Human annotations play a crucial role in machine learning (ML) research and development. However, the ethical considerations around the processes and decisions that go into building ML datasets has not received nearly enough attention. In this paper, we survey an array of literature that provides insights into ethical considerations around crowdsourced dataset annotation. We synthesize these insights, and lay out the challenges in this space along two layers: (1) who the annotator is, and how the annotators' lived experiences can impact their annotations, and (2) the relationship between the annotators and the crowdsourcing platforms and what that relationship affords them. Finally, we put forth a concrete set of recommendations and considerations for dataset developers at various stages of the ML data pipeline: task formulation, selection of annotators, platform and infrastructure choices, dataset analysis and evaluation, and dataset documentation and release.