 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your Toxicity My Toxicity? Exploring the Impact of Rater Identity on Toxicity Annotation
May 01, 2022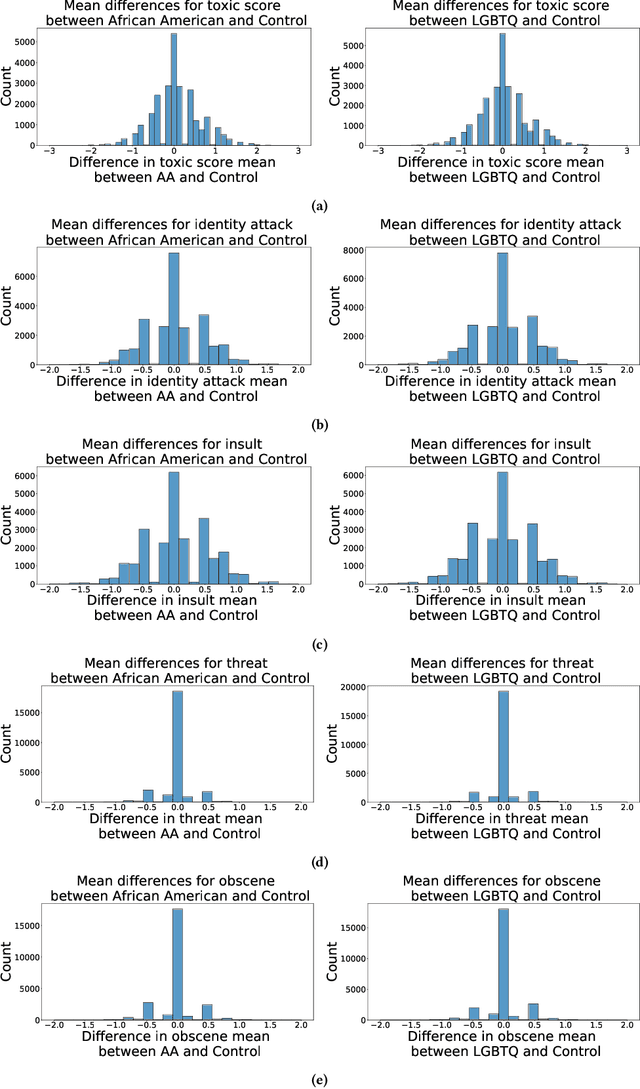

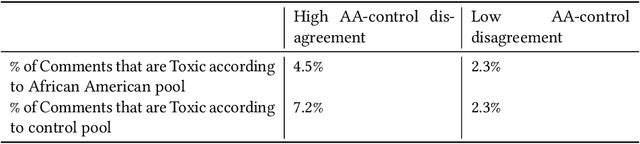

Machine learning models are commonly used to detect toxicity in online conversations. These models are trained on datasets annotated by human raters. We explore how raters' self-described identities impact how they annotate toxicity in online comments. We first define the concept of specialized rater pools: rater pools formed based on raters' self-described identities, rather than at random. We formed three such rater pools for this study--specialized rater pools of raters from the U.S. who identify as African American, LGBTQ, and those who identify as neither. Each of these rater pools annotated the same set of comments, which contains many references to these identity groups. We found that rater identity is a statistically significant factor in how raters will annotate toxicity for identity-related annotations. Using preliminary content analysis, we examined the comments with the most disagreement between rater pools and found nuanced differences in the toxicity annotations. Next, we trained models on the annotations from each of the different rater pools, and compared the scores of these models on comments from several test sets. Finally, we discuss how using raters that self-identify with the subjects of comments can create more inclusive machine learning models, and provide more nuanced ratings than those by random raters.
A New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Feb 22, 2022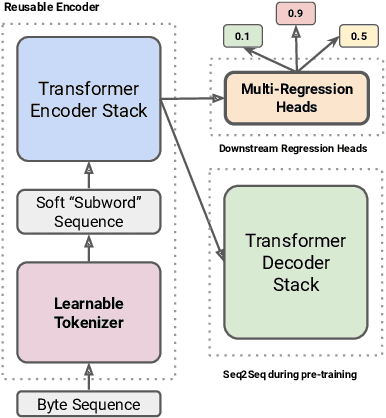
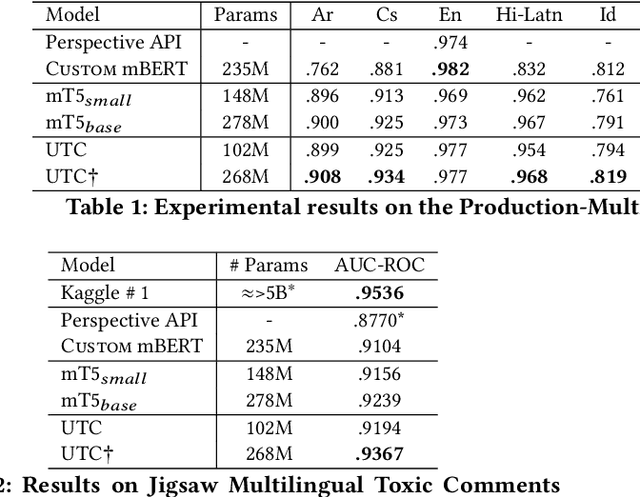
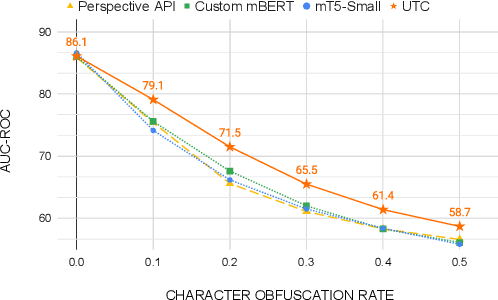
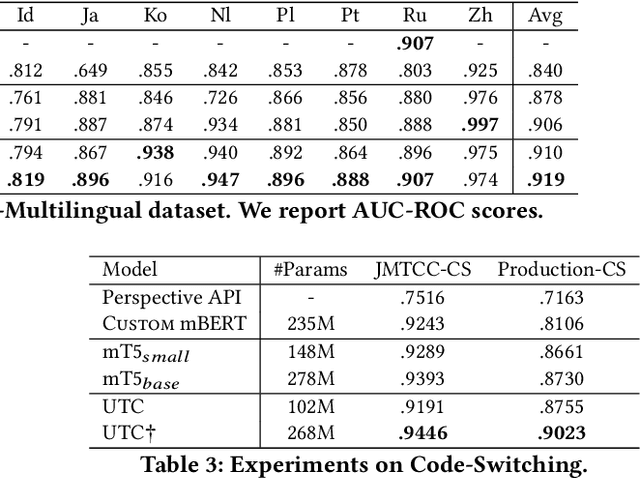
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.
Measuring and Improving Model-Moderator Collaboration using Uncertainty Estimation
Jul 09, 2021
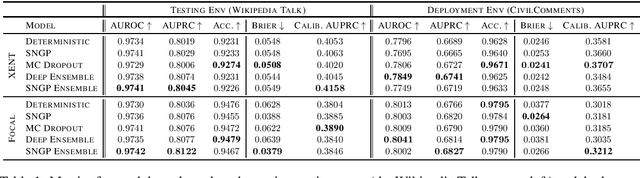
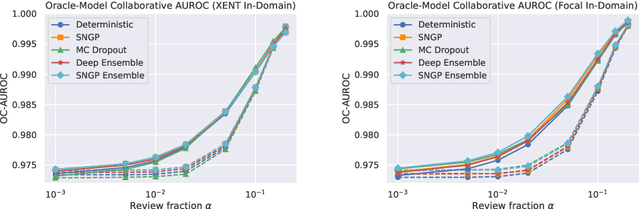
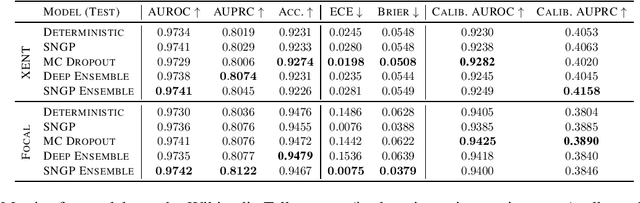
Content moderation is often performed by a collaboration between humans and machine learning models. However, it is not well understood how to design the collaborative process so as to maximize the combined moderator-model system performance. This work presents a rigorous study of this problem, focusing on an approach that incorporates model uncertainty into the collaborative process. First, we introduce principled metrics to describe the performance of the collaborative system under capacity constraints on the human moderator, quantifying how efficiently the combined system utilizes human decisions. Using these metrics, we conduct a large benchmark study evaluating the performance of state-of-the-art uncertainty models under different collaborative review strategies. We find that an uncertainty-based strategy consistently outperforms the widely used strategy based on toxicity scores, and moreover that the choice of review strategy drastically changes the overall system performance. Our results demonstrate the importance of rigorous metrics for understanding and developing effective moderator-model systems for content moderation, as well as the utility of uncertainty estimation in this domain.
Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification
Mar 11, 2019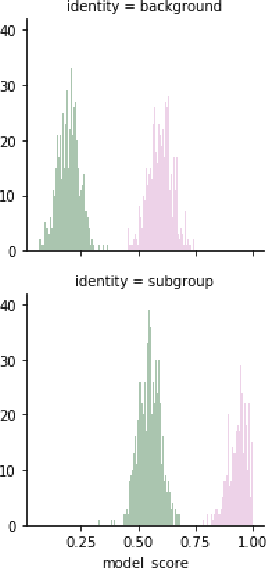
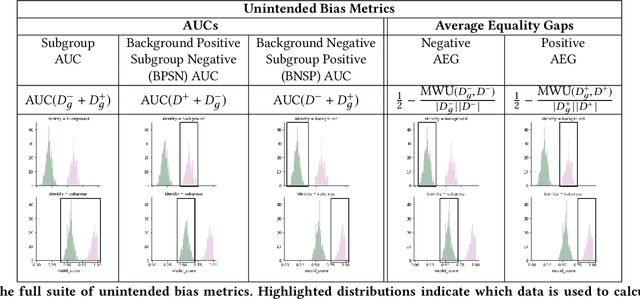
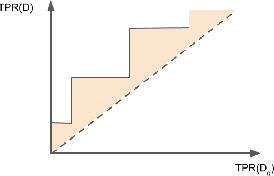
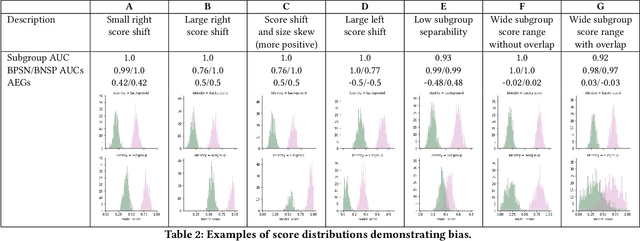
Unintended bias in Machine Learning can manifest as systemic differences in performance for different demographic groups, potentially compounding existing challenges to fairness in society at large. In this paper, we introduce a suite of threshold-agnostic metrics that provide a nuanced view of this unintended bias, by considering the various ways that a classifier's score distribution can vary across designated groups. We also introduce a large new test set of online comments with crowd-sourced annotations for identity references. We use this to show how our metrics can be used to find new and potentially subtle unintended bias in existing public models.
Limitations of Pinned AUC for Measuring Unintended Bias
Mar 05, 2019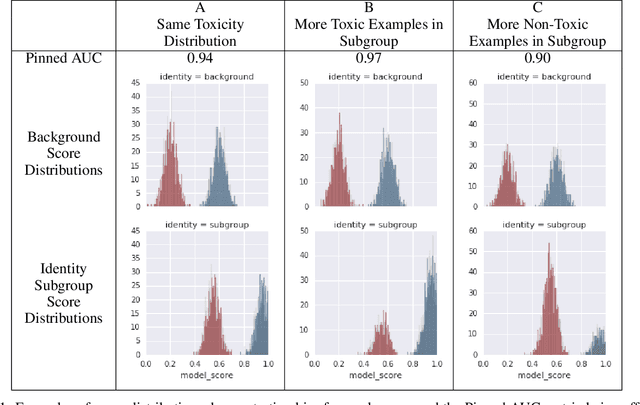
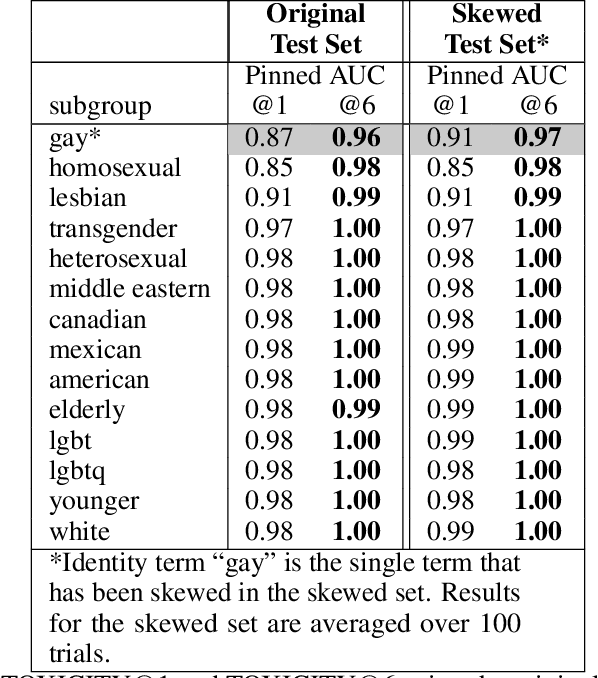
This report examines the Pinned AUC metric introduced and highlights some of its limitations. Pinned AUC provides a threshold-agnostic measure of unintended bias in a classification model, inspired by the ROC-AUC metric. However, as we highlight in this report, there are ways that the metric can obscure different kinds of unintended biases when the underlying class distributions on which bias is being measured are not carefully controlled.