 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Language Model's Reasoning Abilities with Weak Supervision
May 07, 2024



While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present \textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of \textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on \texttt{Anonymity Link}.
ToxicChat: Unveiling Hidden Challenges of Toxicity Detection in Real-World User-AI Conversation
Oct 26, 2023Despite remarkable advances that large language models have achieved in chatbots, maintaining a non-toxic user-AI interactive environment has become increasingly critical nowadays. However, previous efforts in toxicity detection have been mostly based on benchmarks derived from social media content, leaving the unique challenges inherent to real-world user-AI interactions insufficiently explored. In this work, we introduce ToxicChat, a novel benchmark based on real user queries from an open-source chatbot. This benchmark contains the rich, nuanced phenomena that can be tricky for current toxicity detection models to identify, revealing a significant domain difference compared to social media content. Our systematic evaluation of models trained on existing toxicity datasets has shown their shortcomings when applied to this unique domain of ToxicChat. Our work illuminates the potentially overlooked challenges of toxicity detection in real-world user-AI conversations. In the future, ToxicChat can be a valuable resource to drive further advancements toward building a safe and healthy environment for user-AI interactions.
Eliminating Reasoning via Inferring with Planning: A New Framework to Guide LLMs' Non-linear Thinking
Oct 18, 2023Chain-of-Thought(CoT) prompting and its variants explore equipping large language models (LLMs) with high-level reasoning abilities by emulating human-like linear cognition and logic. However, the human mind is complicated and mixed with both linear and nonlinear thinking. In this work, we propose \textbf{I}nferential \textbf{E}xclusion \textbf{P}rompting (IEP), a novel prompting that combines the principles of elimination and inference in order to guide LLMs to think non-linearly. IEP guides LLMs to plan and then utilize Natural Language Inference (NLI) to deduce each possible solution's entailment relation with context, commonsense, or facts, therefore yielding a broader perspective by thinking back for inferring. This forward planning and backward eliminating process allows IEP to better simulate the complex human thinking processes compared to other CoT-based methods, which only reflect linear cognitive processes. We conducted a series of empirical studies and have corroborated that IEP consistently outperforms CoT across various tasks. Additionally, we observe that integrating IEP and CoT further improves the LLMs' performance on certain tasks, highlighting the necessity of equipping LLMs with mixed logic processes. Moreover, to better evaluate comprehensive features inherent in human logic, we introduce \textbf{M}ental-\textbf{A}bility \textbf{R}easoning \textbf{B}enchmark (MARB). The benchmark comprises six novel subtasks with a total of 9,115 questions, among which 1,685 are developed with hand-crafted rationale references. We believe both \textsc{IEP} and \textsc{MARB} can serve as a promising direction for unveiling LLMs' logic and verbal reasoning abilities and drive further advancements. \textsc{MARB} will be available at ~\texttt{anonymity link} soon.
Critique Ability of Large Language Models
Oct 07, 2023

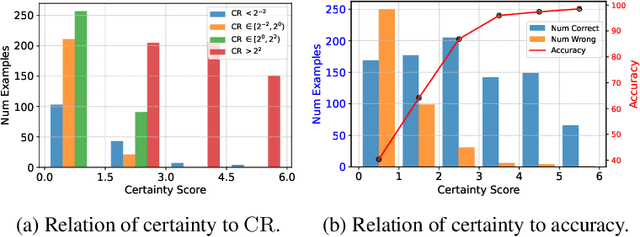

Critical thinking is essential for rational decision-making and problem-solving. This skill hinges on the ability to provide precise and reasoned critiques and is a hallmark of human intelligence. In the era of large language models (LLMs), this study explores the ability of LLMs to deliver accurate critiques across various tasks. We are interested in this topic as a capable critic model could not only serve as a reliable evaluator, but also as a source of supervised signals for model tuning. Particularly, if a model can self-critique, it has the potential for autonomous self-improvement. To examine this, we introduce a unified evaluation framework for assessing the critique abilities of LLMs. We develop a benchmark called CriticBench, which comprises 3K high-quality natural language queries and corresponding model responses; and annotate the correctness of these responses. The benchmark cover tasks such as math problem-solving, code completion, and question answering. We evaluate multiple LLMs on the collected dataset and our analysis reveals several noteworthy insights: (1) Critique is generally challenging for most LLMs, and this capability often emerges only when models are sufficiently large. (2) In particular, self-critique is especially difficult. Even top-performing LLMs struggle to achieve satisfactory performance. (3) Models tend to have lower critique accuracy on problems where they are most uncertain. To this end, we introduce a simple yet effective baseline named self-check, which leverages self-critique to improve task performance for various models. We hope this study serves as an initial exploration into understanding the critique abilities of LLMs, and aims to inform future research, including the development of more proficient critic models and the application of critiques across diverse tasks.
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
Sep 30, 2023



Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset's content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at https://huggingface.co/datasets/lmsys/lmsys-chat-1m.
Is Argument Structure of Learner Chinese Understandable: A Corpus-Based Analysis
Aug 17, 2023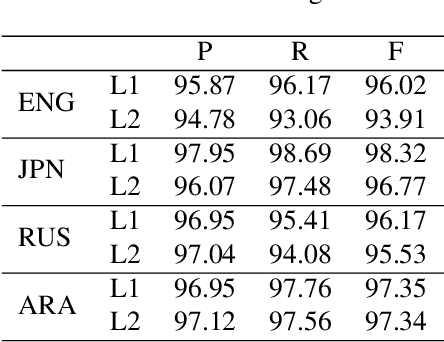
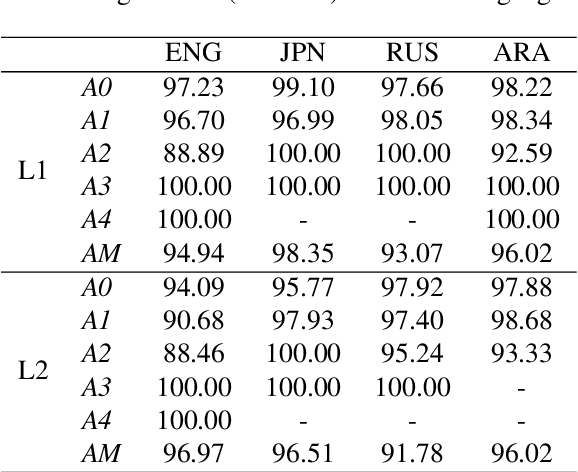
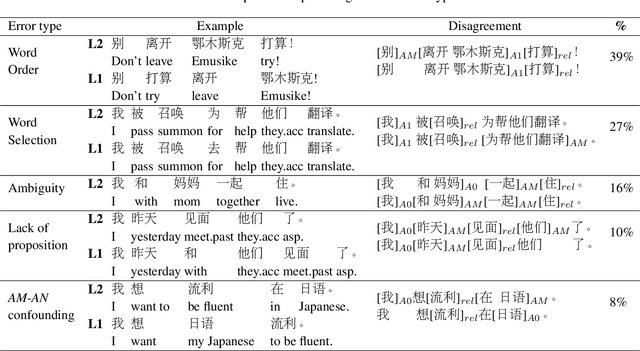
This paper presents a corpus-based analysis of argument structure errors in learner Chinese. The data for analysis includes sentences produced by language learners as well as their corrections by native speakers. We couple the data with semantic role labeling annotations that are manually created by two senior students whose majors are both Applied Linguistics. The annotation procedure is guided by the Chinese PropBank specification, which is originally developed to cover first language phenomena. Nevertheless, we find that it is quite comprehensive for handling second language phenomena. The inter-annotator agreement is rather high, suggesting the understandability of learner texts to native speakers. Based on our annotations, we present a preliminary analysis of competence errors related to argument structure. In particular, speech errors related to word order, word selection, lack of proposition, and argument-adjunct confounding are discussed.
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Jun 09, 2023



Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, such as position and verbosity biases and limited reasoning ability, and propose solutions to migrate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and Chatbot Arena, a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80\% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA/Vicuna. We will publicly release 80 MT-bench questions, 3K expert votes, and 30K conversations with human preferences from Chatbot Arena.
Neural-Symbolic Inference for Robust Autoregressive Graph Parsing via Compositional Uncertainty Quantification
Jan 26, 2023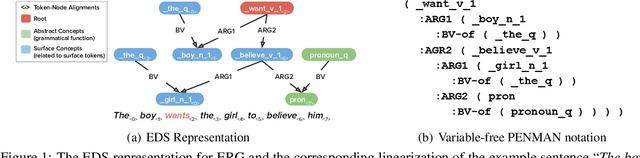



Pre-trained seq2seq models excel at graph semantic parsing with rich annotated data, but generalize worse to out-of-distribution (OOD) and long-tail examples. In comparison, symbolic parsers under-perform on population-level metrics, but exhibit unique strength in OOD and tail generalization. In this work, we study compositionality-aware approach to neural-symbolic inference informed by model confidence, performing fine-grained neural-symbolic reasoning at subgraph level (i.e., nodes and edges) and precisely targeting subgraph components with high uncertainty in the neural parser. As a result, the method combines the distinct strength of the neural and symbolic approaches in capturing different aspects of the graph prediction, leading to well-rounded generalization performance both across domains and in the tail. We empirically investigate the approach in the English Resource Grammar (ERG) parsing problem on a diverse suite of standard in-domain and seven OOD corpora. Our approach leads to 35.26% and 35.60% error reduction in aggregated Smatch score over neural and symbolic approaches respectively, and 14% absolute accuracy gain in key tail linguistic categories over the neural model, outperforming prior state-of-art methods that do not account for compositionality or uncertainty.
A Simple Approach to Improve Single-Model Deep Uncertainty via Distance-Awareness
May 01, 2022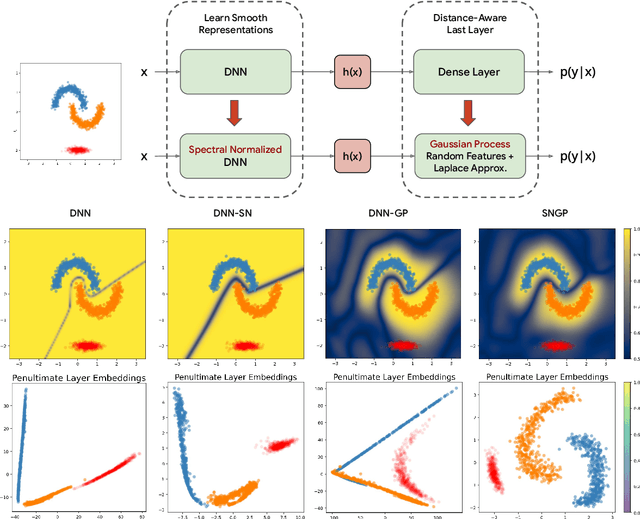
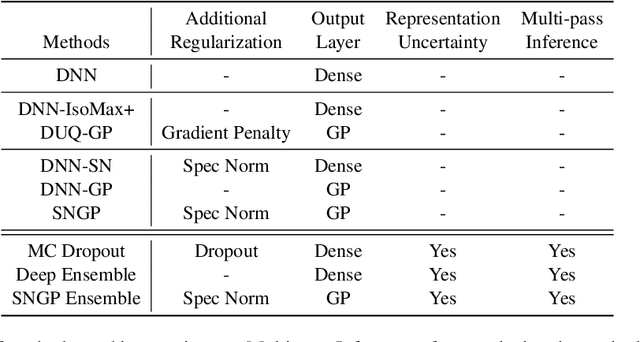
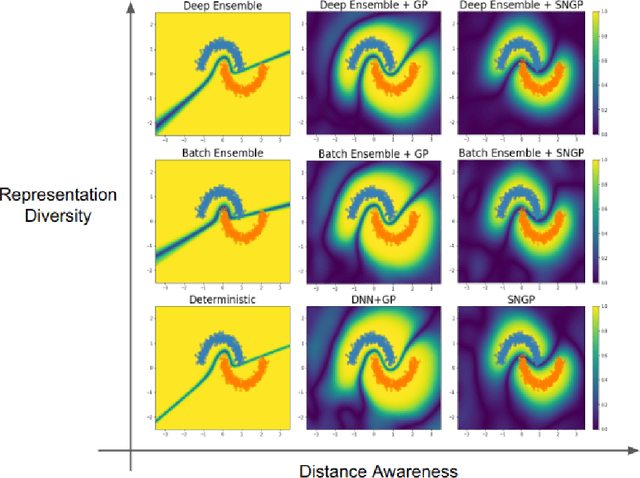
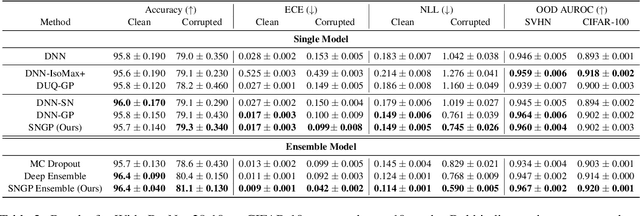
Accurate uncertainty quantification is a major challenge in deep learning, as neural networks can make overconfident errors and assign high confidence predictions to out-of-distribution (OOD) inputs. The most popular approaches to estimate predictive uncertainty in deep learning are methods that combine predictions from multiple neural networks, such as Bayesian neural networks (BNNs) and deep ensembles. However their practicality in real-time, industrial-scale applications are limited due to the high memory and computational cost. Furthermore, ensembles and BNNs do not necessarily fix all the issues with the underlying member networks. In this work, we study principled approaches to improve uncertainty property of a single network, based on a single, deterministic representation. By formalizing the uncertainty quantification as a minimax learning problem, we first identify distance awareness, i.e., the model's ability to quantify the distance of a testing example from the training data, as a necessary condition for a DNN to achieve high-quality (i.e., minimax optimal) uncertainty estimation. We then propose Spectral-normalized Neural Gaussian Process (SNGP), a simple method that improves the distance-awareness ability of modern DNNs with two simple changes: (1) applying spectral normalization to hidden weights to enforce bi-Lipschitz smoothness in representations and (2) replacing the last output layer with a Gaussian process layer. On a suite of vision and language understanding benchmarks, SNGP outperforms other single-model approaches in prediction, calibration and out-of-domain detection. Furthermore, SNGP provides complementary benefits to popular techniques such as deep ensembles and data augmentation, making it a simple and scalable building block for probabilistic deep learning. Code is open-sourced at https://github.com/google/uncertainty-baselines
Measuring and Improving Model-Moderator Collaboration using Uncertainty Estimation
Jul 09, 2021
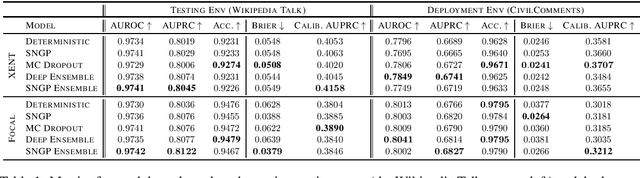
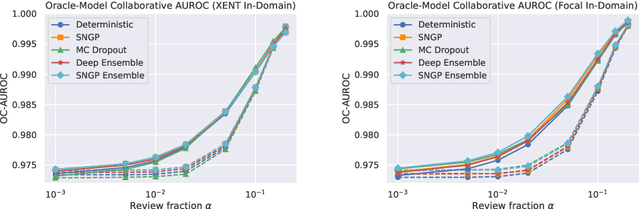
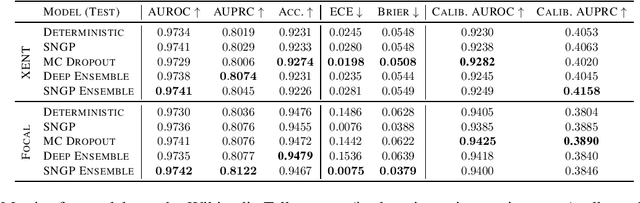
Content moderation is often performed by a collaboration between humans and machine learning models. However, it is not well understood how to design the collaborative process so as to maximize the combined moderator-model system performance. This work presents a rigorous study of this problem, focusing on an approach that incorporates model uncertainty into the collaborative process. First, we introduce principled metrics to describe the performance of the collaborative system under capacity constraints on the human moderator, quantifying how efficiently the combined system utilizes human decisions. Using these metrics, we conduct a large benchmark study evaluating the performance of state-of-the-art uncertainty models under different collaborative review strategies. We find that an uncertainty-based strategy consistently outperforms the widely used strategy based on toxicity scores, and moreover that the choice of review strategy drastically changes the overall system performance. Our results demonstrate the importance of rigorous metrics for understanding and developing effective moderator-model systems for content moderation, as well as the utility of uncertainty estimation in this domain.