 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution
Apr 07, 2026Repository-level issue resolution benchmarks have become a standard testbed for evaluating LLM-based agents, yet success is still predominantly measured by test pass rates. In practice, however, acceptable patches must also comply with project-specific design constraints, such as architectural conventions, error-handling policies, and maintainability requirements, which are rarely encoded in tests and are often documented only implicitly in code review discussions. This paper introduces \textit{design-aware issue resolution} and presents \bench{}, a benchmark that makes such implicit design constraints explicit and measurable. \bench{} is constructed by mining and validating design constraints from real-world pull requests, linking them to issue instances, and automatically checking patch compliance using an LLM-based verifier, yielding 495 issues and 1,787 validated constraints across six repositories, aligned with SWE-bench-Verified and SWE-bench-Pro. Experiments with state-of-the-art agents show that test-based correctness substantially overestimates patch quality: fewer than half of resolved issues are fully design-satisfying, design violations are widespread, and functional correctness exhibits negligible statistical association with design satisfaction. While providing issue-specific design guidance reduces violations, substantial non-compliance remains, highlighting a fundamental gap in current agent capabilities and motivating design-aware evaluation beyond functional correctness.
Reframing Long-Tailed Learning via Loss Landscape Geometry
Mar 22, 2026Balancing performance trade-off on long-tail (LT) data distributions remains a long-standing challenge. In this paper, we posit that this dilemma stems from a phenomenon called "tail performance degradation" (the model tends to severely overfit on head classes while quickly forgetting tail classes) and pose a solution from a loss landscape perspective. We observe that different classes possess divergent convergence points in the loss landscape. Besides, this divergence is aggravated when the model settles into sharp and non-robust minima, rather than a shared and flat solution that is beneficial for all classes. In light of this, we propose a continual learning inspired framework to prevent "tail performance degradation". To avoid inefficient per-class parameter preservation, a Grouped Knowledge Preservation module is proposed to memorize group-specific convergence parameters, promoting convergence towards a shared solution. Concurrently, our framework integrates a Grouped Sharpness Aware module to seek flatter minima by explicitly addressing the geometry of the loss landscape. Notably, our framework requires neither external training samples nor pre-trained models, facilitating the broad applicability. Extensive experiments on four benchmarks demonstrate significant performance gains over state-of-the-art methods. The code is available at:https://gkp-gsa.github.io/.
S3T-Former: A Purely Spike-Driven State-Space Topology Transformer for Skeleton Action Recognition
Mar 18, 2026Skeleton-based action recognition is crucial for multimedia applications but heavily relies on power-hungry Artificial Neural Networks (ANNs), limiting their deployment on resource-constrained edge devices. Spiking Neural Networks (SNNs) provide an energy-efficient alternative; however, existing spiking models for skeleton data often compromise the intrinsic sparsity of SNNs by resorting to dense matrix aggregations, heavy multimodal fusion modules, or non-sparse frequency domain transformations. Furthermore, they severely suffer from the short-term amnesia of spiking neurons. In this paper, we propose the Spiking State-Space Topology Transformer (S3T-Former), which, to the best of our knowledge, is the first purely spike-driven Transformer architecture specifically designed for energy-efficient skeleton action recognition. Rather than relying on heavy fusion overhead, we formulate a Multi-Stream Anatomical Spiking Embedding (M-ASE) that acts as a generalized kinematic differential operator, elegantly transforming multimodal skeleton features into heterogeneous, highly sparse event streams. To achieve true topological and temporal sparsity, we introduce Lateral Spiking Topology Routing (LSTR) for on-demand conditional spike propagation, and a Spiking State-Space (S3) Engine to systematically capture long-range temporal dynamics without non-sparse spectral workarounds. Extensive experiments on multiple large-scale datasets demonstrate that S3T-Former achieves highly competitive accuracy while theoretically reducing energy consumption compared to classic ANNs, establishing a new state-of-the-art for energy-efficient neuromorphic action recognition.
RL-ScanIQA: Reinforcement-Learned Scanpaths for Blind 360°Image Quality Assessment
Mar 15, 2026Blind 360°image quality assessment (IQA) aims to predict perceptual quality for panoramic images without a pristine reference. Unlike conventional planar images, 360°content in immersive environments restricts viewers to a limited viewport at any moment, making viewing behaviors critical to quality perception. Although existing scanpath-based approaches have attempted to model viewing behaviors by approximating the human view-then-rate paradigm, they treat scanpath generation and quality assessment as separate steps, preventing end-to-end optimization and task-aligned exploration. To address this limitation, we propose RL-ScanIQA, a reinforcement-learned framework for blind 360°IQA. RL-ScanIQA optimize a PPO-trained scanpath policy and a quality assessor, where the policy receives quality-driven feedback to learn task-relevant viewing strategies. To improve training stability and prevent mode collapse, we design multi-level rewards, including scanpath diversity and equator-biased priors. We further boost cross-dataset robustness using distortion-space augmentation together with rank-consistent losses that preserve intra-image and inter-image quality orderings. Extensive experiments on three benchmarks show that RL-ScanIQA achieves superior in-dataset performance and cross-dataset generalization. Codes are available at https://github.com/wangyuji1/RLScanIQA.git.
Decoupled Reasoning with Implicit Fact Tokens (DRIFT): A Dual-Model Framework for Efficient Long-Context Inference
Feb 10, 2026The integration of extensive, dynamic knowledge into Large Language Models (LLMs) remains a significant challenge due to the inherent entanglement of factual data and reasoning patterns. Existing solutions, ranging from non-parametric Retrieval-Augmented Generation (RAG) to parametric knowledge editing, are often constrained in practice by finite context windows, retriever noise, or the risk of catastrophic forgetting. In this paper, we propose DRIFT, a novel dual-model architecture designed to explicitly decouple knowledge extraction from the reasoning process. Unlike static prompt compression, DRIFT employs a lightweight knowledge model to dynamically compress document chunks into implicit fact tokens conditioned on the query. These dense representations are projected into the reasoning model's embedding space, replacing raw, redundant text while maintaining inference accuracy. Extensive experiments show that DRIFT significantly improves performance on long-context tasks, outperforming strong baselines among comparably sized models. Our approach provides a scalable and efficient paradigm for extending the effective context window and reasoning capabilities of LLMs. Our code is available at https://github.com/Lancelot-Xie/DRIFT.
Rewarding Creativity: A Human-Aligned Generative Reward Model for Reinforcement Learning in Storytelling
Jan 12, 2026While Large Language Models (LLMs) can generate fluent text, producing high-quality creative stories remains challenging. Reinforcement Learning (RL) offers a promising solution but faces two critical obstacles: designing reliable reward signals for subjective storytelling quality and mitigating training instability. This paper introduces the Reinforcement Learning for Creative Storytelling (RLCS) framework to systematically address both challenges. First, we develop a Generative Reward Model (GenRM) that provides multi-dimensional analysis and explicit reasoning about story preferences, trained through supervised fine-tuning on demonstrations with reasoning chains distilled from strong teacher models, followed by GRPO-based refinement on expanded preference data. Second, we introduce an entropy-based reward shaping strategy that dynamically prioritizes learning on confident errors and uncertain correct predictions, preventing overfitting on already-mastered patterns. Experiments demonstrate that GenRM achieves 68\% alignment with human creativity judgments, and RLCS significantly outperforms strong baselines including Gemini-2.5-Pro in overall story quality. This work provides a practical pipeline for applying RL to creative domains, effectively navigating the dual challenges of reward modeling and training stability.
AltLoRA: Towards Better Gradient Approximation in Low-Rank Adaptation with Alternating Projections
May 18, 2025Low-Rank Adaptation (LoRA) has emerged as an effective technique for reducing memory overhead in fine-tuning large language models. However, it often suffers from sub-optimal performance compared with full fine-tuning since the update is constrained in the low-rank space. Recent variants such as LoRA-Pro attempt to mitigate this by adjusting the gradients of the low-rank matrices to approximate the full gradient. However, LoRA-Pro's solution is not unique, and different solutions can lead to significantly varying performance in ablation studies. Besides, to incorporate momentum or adaptive optimization design, approaches like LoRA-Pro must first compute the equivalent gradient, causing a higher memory cost close to full fine-tuning. A key challenge remains in integrating momentum properly into the low-rank space with lower memory cost. In this work, we propose AltLoRA, an alternating projection method that avoids the difficulties in gradient approximation brought by the joint update design, meanwhile integrating momentum without higher memory complexity. Our theoretical analysis provides convergence guarantees and further shows that AltLoRA enables stable feature learning and robustness to transformation invariance. Extensive experiments across multiple tasks demonstrate that AltLoRA outperforms LoRA and its variants, narrowing the gap toward full fine-tuning while preserving superior memory efficiency.
AutoGLM: Autonomous Foundation Agents for GUIs
Oct 28, 2024



We present AutoGLM, a new series in the ChatGLM family, designed to serve as foundation agents for autonomous control of digital devices through Graphical User Interfaces (GUIs). While foundation models excel at acquiring human knowledge, they often struggle with decision-making in dynamic real-world environments, limiting their progress toward artificial general intelligence. This limitation underscores the importance of developing foundation agents capable of learning through autonomous environmental interactions by reinforcing existing models. Focusing on Web Browser and Phone as representative GUI scenarios, we have developed AutoGLM as a practical foundation agent system for real-world GUI interactions. Our approach integrates a comprehensive suite of techniques and infrastructures to create deployable agent systems suitable for user delivery. Through this development, we have derived two key insights: First, the design of an appropriate "intermediate interface" for GUI control is crucial, enabling the separation of planning and grounding behaviors, which require distinct optimization for flexibility and accuracy respectively. Second, we have developed a novel progressive training framework that enables self-evolving online curriculum reinforcement learning for AutoGLM. Our evaluations demonstrate AutoGLM's effectiveness across multiple domains. For web browsing, AutoGLM achieves a 55.2% success rate on VAB-WebArena-Lite (improving to 59.1% with a second attempt) and 96.2% on OpenTable evaluation tasks. In Android device control, AutoGLM attains a 36.2% success rate on AndroidLab (VAB-Mobile) and 89.7% on common tasks in popular Chinese APPs.
FADAS: Towards Federated Adaptive Asynchronous Optimization
Jul 25, 2024
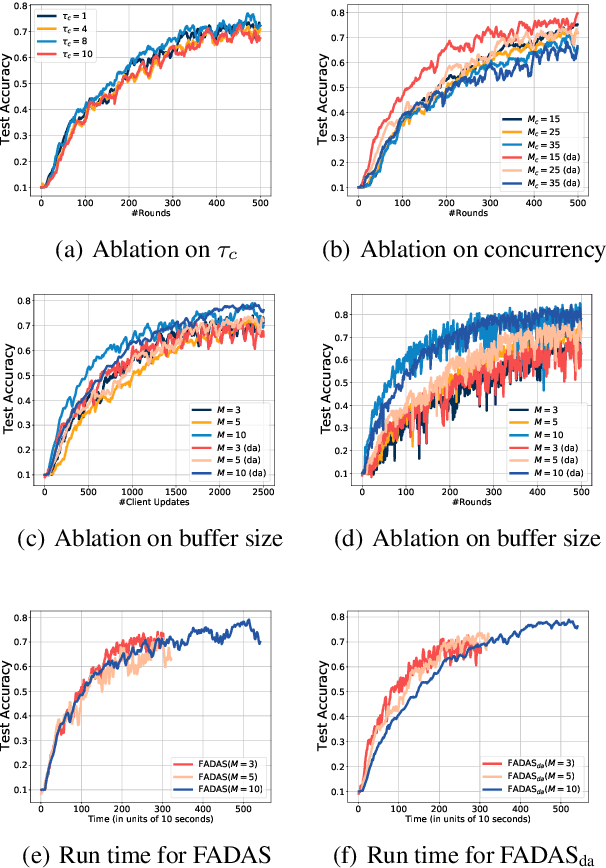

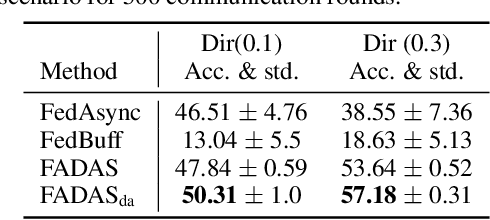
Federated learning (FL) has emerged as a widely adopted training paradigm for privacy-preserving machine learning. While the SGD-based FL algorithms have demonstrated considerable success in the past, there is a growing trend towards adopting adaptive federated optimization methods, particularly for training large-scale models. However, the conventional synchronous aggregation design poses a significant challenge to the practical deployment of those adaptive federated optimization methods, particularly in the presence of straggler clients. To fill this research gap, this paper introduces federated adaptive asynchronous optimization, named FADAS, a novel method that incorporates asynchronous updates into adaptive federated optimization with provable guarantees. To further enhance the efficiency and resilience of our proposed method in scenarios with significant asynchronous delays, we also extend FADAS with a delay-adaptive learning adjustment strategy. We rigorously establish the convergence rate of the proposed algorithms and empirical results demonstrate the superior performance of FADAS over other asynchronous FL baselines.
XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
May 30, 2024
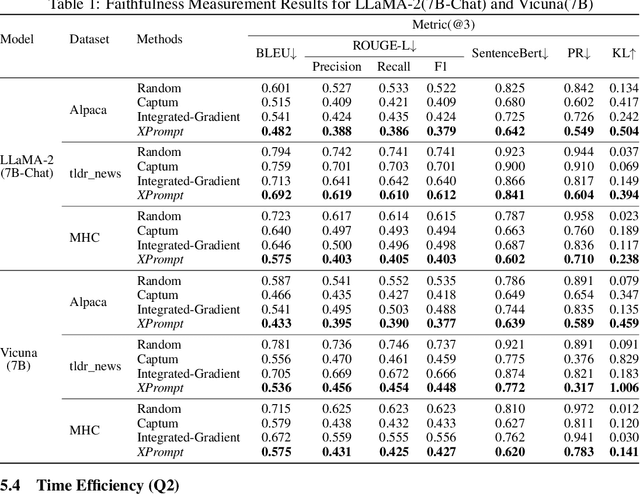
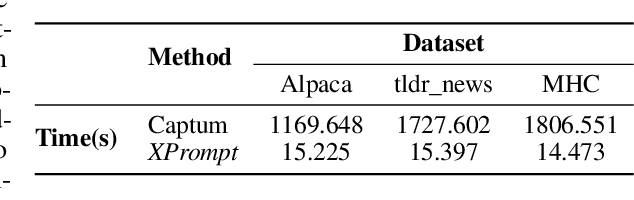

Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.