 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForced Deferral: Manipulating Routing Decisions in Multimodal LLM Cascades
Jun 13, 2026While multimodal large language models (MLLMs) have shown strong visual reasoning abilities, serving a large model for every query is computationally expensive. MLLM cascades mitigate this cost by first querying a weak but cheaper model and deferring to a strong model when the weak model's output is unconfident. However, since the weak model's confidence directly controls compute allocation, these systems expose a new attack surface: an adversary can manipulate confidence so that their queries are consistently deferred to the strong model. Motivated by this vulnerability, we introduce the Forced Deferral Attack (FDA), an adversarial image attack that lowers the weak model's confidence and causes cascades to route queries to the strong model. FDA learns a universal border trigger by optimizing a temperature-flattened objective. This objective pushes the weak model's token distribution on triggered inputs toward less concentrated targets constructed from its clean responses. Across datasets, model families, and deferral metrics, FDA consistently increases strong-model routing while outperforming image-perturbation and prompt-injection baselines. These results show that MLLM cascades are vulnerable to attacks that manipulate compute allocation, forcing unintended strong-model usage without directly targeting answer correctness.
ForecastCompass: Guiding Agentic Forecasting with Adaptive Factor Memory
May 29, 2026Agentic forecasting is important for decision-making in dynamic environments, but it remains challenging because agents must reason from incomplete, time-limited evidence and produce calibrated probabilities before outcomes are resolved. Memory provides a natural mechanism for transferring experience from resolved forecasts to future prediction tasks. However, existing agent-memory methods are not tailored to forecasting, as they typically store past interactions, reflections, or factual associations without explicitly representing reusable predictive factors or calibration knowledge. We propose ForecastCompass (FoCo), an adaptive factor-based memory framework for agentic forecasting. FoCo organizes forecasting experience with a hierarchical forecasting-task taxonomy, enabling retrieval task-relevant forecasting knowledge. It maintains two complementary memory components: factor memory, which captures reusable predictive dimensions, and reasoning memory, which encodes probability updating, uncertainty handling, and calibration principles. Using retrospective analyses as learning signals, FoCo iteratively revises memory through a verbalized memory-revision procedure, enabling the agent to accumulate transferable forecasting knowledge over time. Experiments on Prophet Arena and FutureX with GPT-5-mini and Gemini-2.5-Flash show that FoCo improves both probabilistic accuracy and calibration.
MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation
Mar 24, 2026Large language model (LLM)-based agents rely on memory mechanisms to reuse knowledge from past problem-solving experiences. Existing approaches typically construct memory in a per-agent manner, tightly coupling stored knowledge to a single model's reasoning style. In modern deployments with heterogeneous agents, a natural question arises: can a single memory system be shared across different models? We found that naively transferring memory between agents often degrades performance, as such memory entangles task-relevant knowledge with agent-specific biases. To address this challenge, we propose MemCollab, a collaborative memory framework that constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task. This contrastive process distills abstract reasoning constraints that capture shared task-level invariants while suppressing agent-specific artifacts. We further introduce a task-aware retrieval mechanism that conditions memory access on task category, ensuring that only relevant constraints are used at inference time. Experiments on mathematical reasoning and code generation benchmarks demonstrate that MemCollab consistently improves both accuracy and inference-time efficiency across diverse agents, including cross-modal-family settings. Our results show that the collaboratively constructed memory can function as a shared reasoning resource for diverse LLM-based agents.
Monitoring Decoding: Mitigating Hallucination via Evaluating the Factuality of Partial Response during Generation
Mar 05, 2025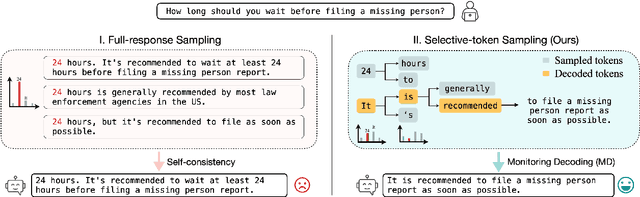

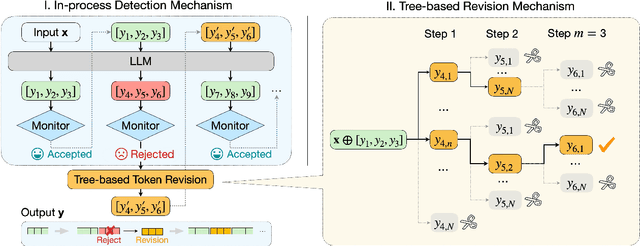

While large language models have demonstrated exceptional performance across a wide range of tasks, they remain susceptible to hallucinations -- generating plausible yet factually incorrect contents. Existing methods to mitigating such risk often rely on sampling multiple full-length generations, which introduces significant response latency and becomes ineffective when the model consistently produces hallucinated outputs with high confidence. To address these limitations, we introduce Monitoring Decoding (MD), a novel framework that dynamically monitors the generation process and selectively applies in-process interventions, focusing on revising crucial tokens responsible for hallucinations. Instead of waiting until completion of multiple full-length generations, we identify hallucination-prone tokens during generation using a monitor function, and further refine these tokens through a tree-based decoding strategy. This approach ensures an enhanced factual accuracy and coherence in the generated output while maintaining efficiency. Experimental results demonstrate that MD consistently outperforms self-consistency-based approaches in both effectiveness and efficiency, achieving higher factual accuracy while significantly reducing computational overhead.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
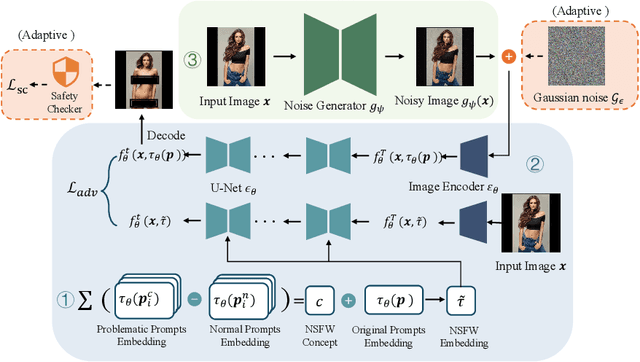


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.
Mitigating Graph Covariate Shift via Score-based Out-of-distribution Augmentation
Oct 23, 2024Distribution shifts between training and testing datasets significantly impair the model performance on graph learning. A commonly-taken causal view in graph invariant learning suggests that stable predictive features of graphs are causally associated with labels, whereas varying environmental features lead to distribution shifts. In particular, covariate shifts caused by unseen environments in test graphs underscore the critical need for out-of-distribution (OOD) generalization. Existing graph augmentation methods designed to address the covariate shift often disentangle the stable and environmental features in the input space, and selectively perturb or mixup the environmental features. However, such perturbation-based methods heavily rely on an accurate separation of stable and environmental features, and their exploration ability is confined to existing environmental features in the training distribution. To overcome these limitations, we introduce a novel approach using score-based graph generation strategies that synthesize unseen environmental features while preserving the validity and stable features of overall graph patterns. Our comprehensive empirical evaluations demonstrate the enhanced effectiveness of our method in improving graph OOD generalization.
XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
May 30, 2024
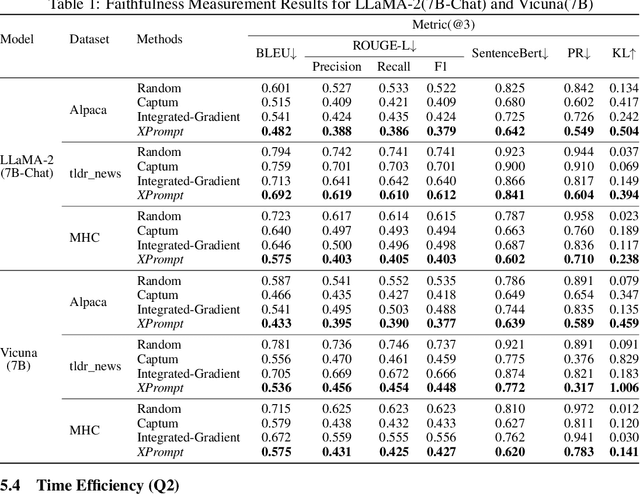
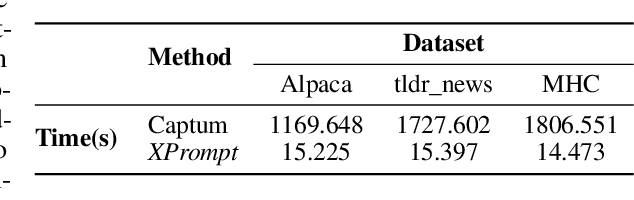

Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.