 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARV: A Diagnostic Benchmark for Compositional Analogical Reasoning in Multimodal LLMs
Mar 30, 2026Analogical reasoning tests a fundamental aspect of human cognition: mapping the relation from one pair of objects to another. Existing evaluations of this ability in multimodal large language models (MLLMs) overlook the ability to compose rules from multiple sources, a critical component of higher-order intelligence. To close this gap, we introduce CARV (Compositional Analogical Reasoning in Vision), a novel task together with a 5,500-sample dataset as the first diagnostic benchmark. We extend the analogy from a single pair to multiple pairs, which requires MLLMs to extract symbolic rules from each pair and compose new transformations. Evaluation on the state-of-the-art MLLMs reveals a striking performance gap: even Gemini-2.5 Pro achieving only 40.4% accuracy, far below human-level performance of 100%. Diagnostic analysis shows two consistent failure modes: (1) decomposing visual changes into symbolic rules, and (2) maintaining robustness under diverse or complex settings, highlighting the limitations of current MLLMs on this task.
ReLope: KL-Regularized LoRA Probes for Multimodal LLM Routing
Mar 25, 2026Routing has emerged as a promising strategy for balancing performance and cost in large language model (LLM) systems that combine lightweight models with powerful but expensive large models. Recent studies show that \emph{probe routing}, which predicts the correctness of a small model using its hidden states, provides an effective solution in text-only LLMs. However, we observe that these probes degrade substantially when applied to multimodal LLMs (MLLMs). Through empirical analysis, we find that the presence of visual inputs weakens the separability of correctness signals in hidden states, making them harder to extract using standard probe designs. To address this challenge, we introduce two complementary approaches for improving probe routing in MLLMs. First, we propose the \emph{Attention Probe}, which aggregates hidden states from the preceding layer based on attention scores to recover distributed correctness signals. Second, we present the \emph{KL-Regularized LoRA Probe (ReLope)}, which inserts a lightweight LoRA adapter and applies a KL regularizer to learn routing-aware representations. Comprehensive experiments show that our methods consistently outperform baselines, suggesting that improving the quality of hidden states is key to effective routing in MLLMs. Our code is available at https://github.com/Spinozaaa/ReLope.
MemCollab: Cross-Agent Memory Collaboration via Contrastive Trajectory Distillation
Mar 24, 2026Large language model (LLM)-based agents rely on memory mechanisms to reuse knowledge from past problem-solving experiences. Existing approaches typically construct memory in a per-agent manner, tightly coupling stored knowledge to a single model's reasoning style. In modern deployments with heterogeneous agents, a natural question arises: can a single memory system be shared across different models? We found that naively transferring memory between agents often degrades performance, as such memory entangles task-relevant knowledge with agent-specific biases. To address this challenge, we propose MemCollab, a collaborative memory framework that constructs agent-agnostic memory by contrasting reasoning trajectories generated by different agents on the same task. This contrastive process distills abstract reasoning constraints that capture shared task-level invariants while suppressing agent-specific artifacts. We further introduce a task-aware retrieval mechanism that conditions memory access on task category, ensuring that only relevant constraints are used at inference time. Experiments on mathematical reasoning and code generation benchmarks demonstrate that MemCollab consistently improves both accuracy and inference-time efficiency across diverse agents, including cross-modal-family settings. Our results show that the collaboratively constructed memory can function as a shared reasoning resource for diverse LLM-based agents.
Mitigating topology biases in Graph Diffusion via Counterfactual Intervention
Mar 02, 2026Graph diffusion models have gained significant attention in graph generation tasks, but they often inherit and amplify topology biases from sensitive attributes (e.g. gender, age, region), leading to unfair synthetic graphs. Existing fair graph generation using diffusion models is limited to specific graph-based applications with complete labels or requires simultaneous updates for graph structure and node attributes, making them unsuitable for general usage. To relax these limitations by applying the debiasing method directly on graph topology, we propose Fair Graph Diffusion Model (FairGDiff), a counterfactual-based one-step solution that mitigates topology biases while balancing fairness and utility. In detail, we construct a causal model to capture the relationship between sensitive attributes, biased link formation, and the generated graph structure. By answering the counterfactual question "Would the graph structure change if the sensitive attribute were different?", we estimate an unbiased treatment and incorporate it into the diffusion process. FairGDiff integrates counterfactual learning into both forward diffusion and backward denoising, ensuring that the generated graphs are independent of sensitive attributes while preserving structural integrity. Extensive experiments on real-world datasets demonstrate that FairGDiff achieves a superior trade-off between fairness and utility, outperforming existing fair graph generation methods while maintaining scalability.
PreFlect: From Retrospective to Prospective Reflection in Large Language Model Agents
Feb 06, 2026Advanced large language model agents typically adopt self-reflection for improving performance, where agents iteratively analyze past actions to correct errors. However, existing reflective approaches are inherently retrospective: agents act, observe failure, and only then attempt to recover. In this work, we introduce PreFlect, a prospective reflection mechanism that shifts the paradigm from post hoc correction to pre-execution foresight by criticizing and refining agent plans before execution. To support grounded prospective reflection, we distill planning errors from historical agent trajectories, capturing recurring success and failure patterns observed across past executions. Furthermore, we complement prospective reflection with a dynamic re-planning mechanism that provides execution-time plan update in case the original plan encounters unexpected deviation. Evaluations on different benchmarks demonstrate that PreFlect significantly improves overall agent utility on complex real-world tasks, outperforming strong reflection-based baselines and several more complex agent architectures. Code will be updated at https://github.com/wwwhy725/PreFlect.
Exposing Vulnerabilities in Explanation for Time Series Classifiers via Dual-Target Attacks
Feb 02, 2026Interpretable time series deep learning systems are often assessed by checking temporal consistency on explanations, implicitly treating this as evidence of robustness. We show that this assumption can fail: Predictions and explanations can be adversarially decoupled, enabling targeted misclassification while the explanation remains plausible and consistent with a chosen reference rationale. We propose TSEF (Time Series Explanation Fooler), a dual-target attack that jointly manipulates the classifier and explainer outputs. In contrast to single-objective misclassification attacks that disrupt explanation and spread attribution mass broadly, TSEF achieves targeted prediction changes while keeping explanations consistent with the reference. Across multiple datasets and explainer backbones, our results consistently reveal that explanation stability is a misleading proxy for decision robustness and motivate coupling-aware robustness evaluations for trustworthy time series tasks.
Phi: Preference Hijacking in Multi-modal Large Language Models at Inference Time
Sep 15, 2025



Recently, Multimodal Large Language Models (MLLMs) have gained significant attention across various domains. However, their widespread adoption has also raised serious safety concerns. In this paper, we uncover a new safety risk of MLLMs: the output preference of MLLMs can be arbitrarily manipulated by carefully optimized images. Such attacks often generate contextually relevant yet biased responses that are neither overtly harmful nor unethical, making them difficult to detect. Specifically, we introduce a novel method, Preference Hijacking (Phi), for manipulating the MLLM response preferences using a preference hijacked image. Our method works at inference time and requires no model modifications. Additionally, we introduce a universal hijacking perturbation -- a transferable component that can be embedded into different images to hijack MLLM responses toward any attacker-specified preferences. Experimental results across various tasks demonstrate the effectiveness of our approach. The code for Phi is accessible at https://github.com/Yifan-Lan/Phi.
Topological Structure Learning Should Be A Research Priority for LLM-Based Multi-Agent Systems
May 29, 2025Large Language Model-based Multi-Agent Systems (MASs) have emerged as a powerful paradigm for tackling complex tasks through collaborative intelligence. Nevertheless, the question of how agents should be structurally organized for optimal cooperation remains largely unexplored. In this position paper, we aim to gently redirect the focus of the MAS research community toward this critical dimension: develop topology-aware MASs for specific tasks. Specifically, the system consists of three core components - agents, communication links, and communication patterns - that collectively shape its coordination performance and efficiency. To this end, we introduce a systematic, three-stage framework: agent selection, structure profiling, and topology synthesis. Each stage would trigger new research opportunities in areas such as language models, reinforcement learning, graph learning, and generative modeling; together, they could unleash the full potential of MASs in complicated real-world applications. Then, we discuss the potential challenges and opportunities in the evaluation of multiple systems. We hope our perspective and framework can offer critical new insights in the era of agentic AI.
Monitoring Decoding: Mitigating Hallucination via Evaluating the Factuality of Partial Response during Generation
Mar 05, 2025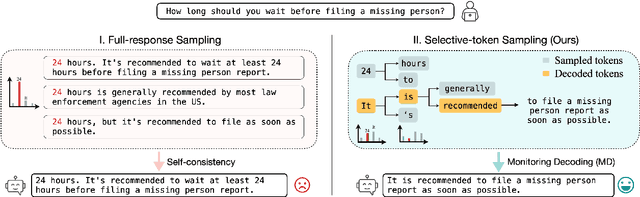

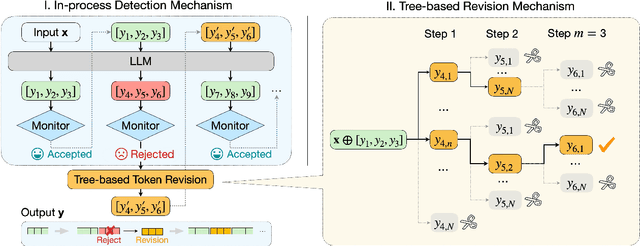

While large language models have demonstrated exceptional performance across a wide range of tasks, they remain susceptible to hallucinations -- generating plausible yet factually incorrect contents. Existing methods to mitigating such risk often rely on sampling multiple full-length generations, which introduces significant response latency and becomes ineffective when the model consistently produces hallucinated outputs with high confidence. To address these limitations, we introduce Monitoring Decoding (MD), a novel framework that dynamically monitors the generation process and selectively applies in-process interventions, focusing on revising crucial tokens responsible for hallucinations. Instead of waiting until completion of multiple full-length generations, we identify hallucination-prone tokens during generation using a monitor function, and further refine these tokens through a tree-based decoding strategy. This approach ensures an enhanced factual accuracy and coherence in the generated output while maintaining efficiency. Experimental results demonstrate that MD consistently outperforms self-consistency-based approaches in both effectiveness and efficiency, achieving higher factual accuracy while significantly reducing computational overhead.
GuardDoor: Safeguarding Against Malicious Diffusion Editing via Protective Backdoors
Mar 05, 2025



The growing accessibility of diffusion models has revolutionized image editing but also raised significant concerns about unauthorized modifications, such as misinformation and plagiarism. Existing countermeasures largely rely on adversarial perturbations designed to disrupt diffusion model outputs. However, these approaches are found to be easily neutralized by simple image preprocessing techniques, such as compression and noise addition. To address this limitation, we propose GuardDoor, a novel and robust protection mechanism that fosters collaboration between image owners and model providers. Specifically, the model provider participating in the mechanism fine-tunes the image encoder to embed a protective backdoor, allowing image owners to request the attachment of imperceptible triggers to their images. When unauthorized users attempt to edit these protected images with this diffusion model, the model produces meaningless outputs, reducing the risk of malicious image editing. Our method demonstrates enhanced robustness against image preprocessing operations and is scalable for large-scale deployment. This work underscores the potential of cooperative frameworks between model providers and image owners to safeguard digital content in the era of generative AI.