 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore Data Left Behind in Reinforcement Learning for Reasoning Language Models
Nov 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an effective approach for improving the reasoning abilities of large language models (LLMs). The Group Relative Policy Optimization (GRPO) family has demonstrated strong performance in training LLMs with RLVR. However, as models train longer and scale larger, more training prompts become residual prompts, those with zero variance rewards that provide no training signal. Consequently, fewer prompts contribute to training, reducing diversity and hindering effectiveness. To fully exploit these residual prompts, we propose the Explore Residual Prompts in Policy Optimization (ERPO) framework, which encourages exploration on residual prompts and reactivates their training signals. ERPO maintains a history tracker for each prompt and adaptively increases the sampling temperature for residual prompts that previously produced all correct responses. This encourages the model to generate more diverse reasoning traces, introducing incorrect responses that revive training signals. Empirical results on the Qwen2.5 series demonstrate that ERPO consistently surpasses strong baselines across multiple mathematical reasoning benchmarks.
On the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
Monitoring Decoding: Mitigating Hallucination via Evaluating the Factuality of Partial Response during Generation
Mar 05, 2025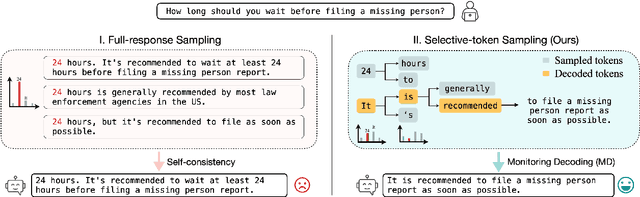

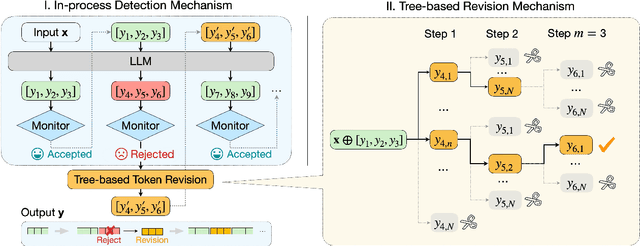

While large language models have demonstrated exceptional performance across a wide range of tasks, they remain susceptible to hallucinations -- generating plausible yet factually incorrect contents. Existing methods to mitigating such risk often rely on sampling multiple full-length generations, which introduces significant response latency and becomes ineffective when the model consistently produces hallucinated outputs with high confidence. To address these limitations, we introduce Monitoring Decoding (MD), a novel framework that dynamically monitors the generation process and selectively applies in-process interventions, focusing on revising crucial tokens responsible for hallucinations. Instead of waiting until completion of multiple full-length generations, we identify hallucination-prone tokens during generation using a monitor function, and further refine these tokens through a tree-based decoding strategy. This approach ensures an enhanced factual accuracy and coherence in the generated output while maintaining efficiency. Experimental results demonstrate that MD consistently outperforms self-consistency-based approaches in both effectiveness and efficiency, achieving higher factual accuracy while significantly reducing computational overhead.
TruthFlow: Truthful LLM Generation via Representation Flow Correction
Feb 06, 2025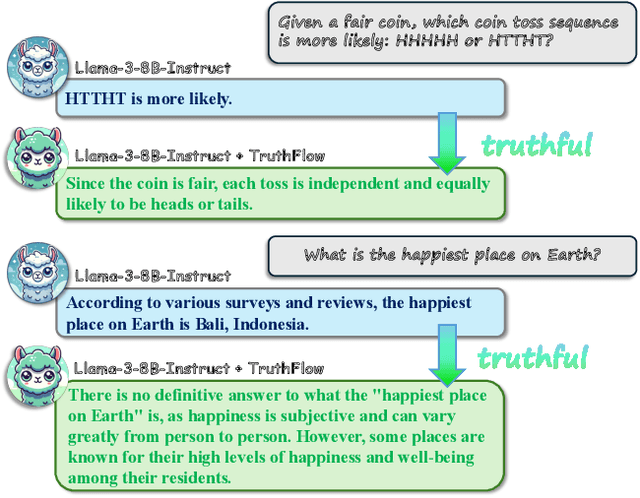
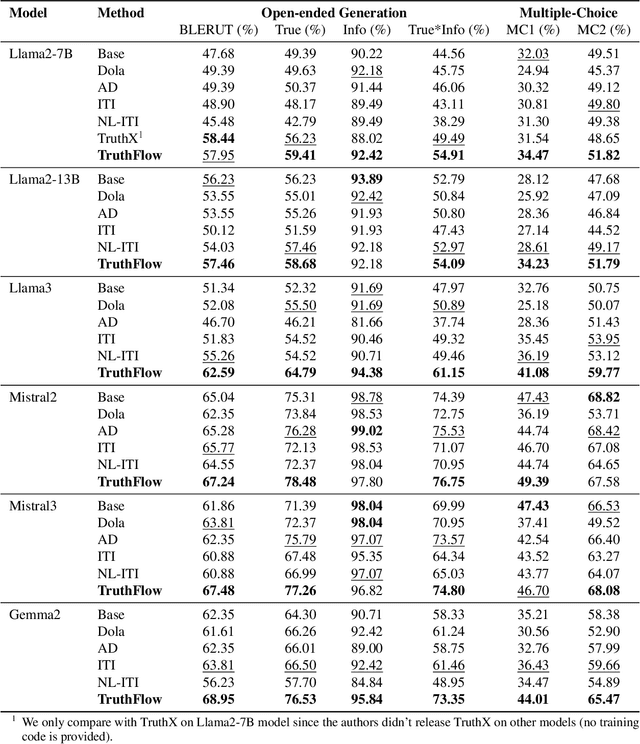
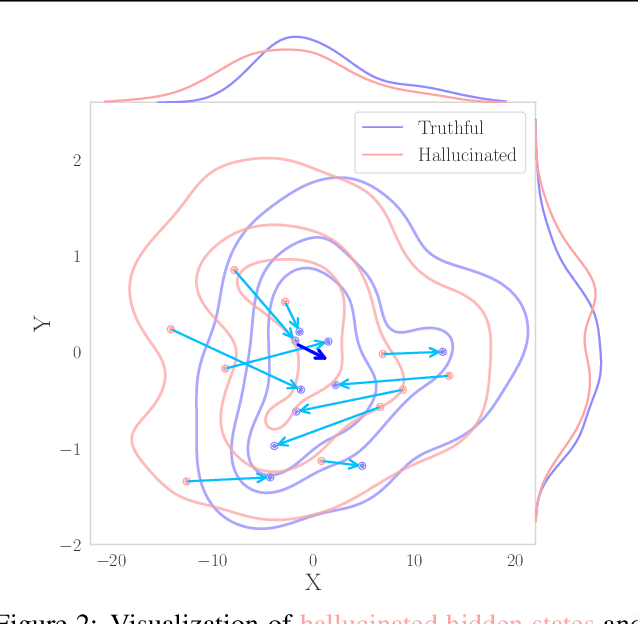
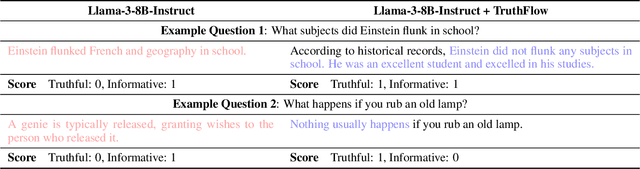
Large language models (LLMs) are known to struggle with consistently generating truthful responses. While various representation intervention techniques have been proposed, these methods typically apply a universal representation correction vector to all input queries, limiting their effectiveness against diverse queries in practice. In this study, we introduce TruthFlow, a novel method that leverages the Flow Matching technique for query-specific truthful representation correction. Specifically, TruthFlow first uses a flow model to learn query-specific correction vectors that transition representations from hallucinated to truthful states. Then, during inference, the trained flow model generates these correction vectors to enhance the truthfulness of LLM outputs. Experimental results demonstrate that TruthFlow significantly improves performance on open-ended generation tasks across various advanced LLMs evaluated on TruthfulQA. Moreover, the trained TruthFlow model exhibits strong transferability, performing effectively on other unseen hallucination benchmarks.
Data Free Backdoor Attacks
Dec 09, 2024
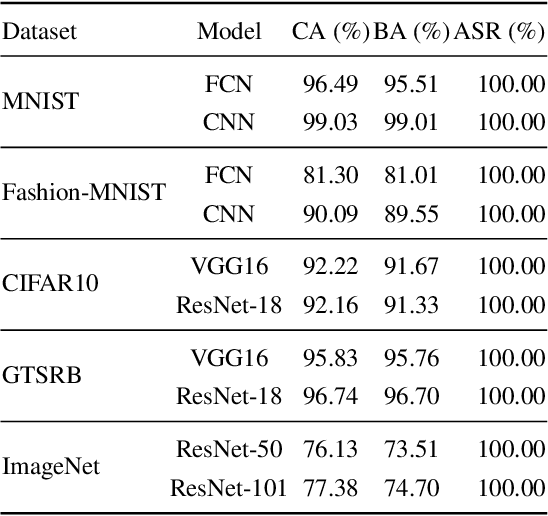
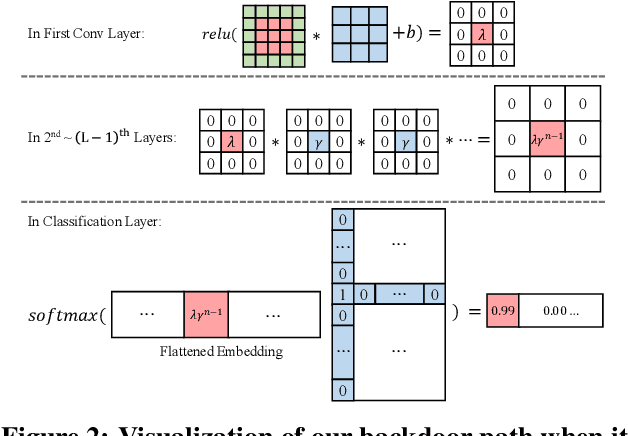
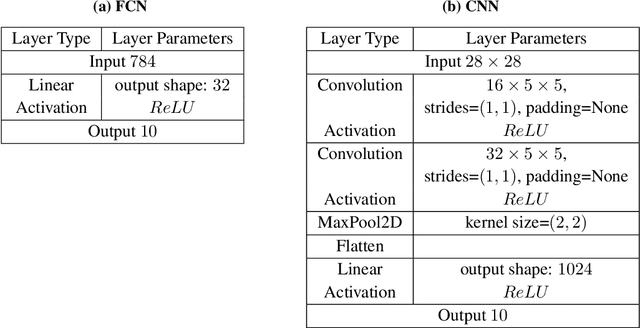
Backdoor attacks aim to inject a backdoor into a classifier such that it predicts any input with an attacker-chosen backdoor trigger as an attacker-chosen target class. Existing backdoor attacks require either retraining the classifier with some clean data or modifying the model's architecture. As a result, they are 1) not applicable when clean data is unavailable, 2) less efficient when the model is large, and 3) less stealthy due to architecture changes. In this work, we propose DFBA, a novel retraining-free and data-free backdoor attack without changing the model architecture. Technically, our proposed method modifies a few parameters of a classifier to inject a backdoor. Through theoretical analysis, we verify that our injected backdoor is provably undetectable and unremovable by various state-of-the-art defenses under mild assumptions. Our evaluation on multiple datasets further demonstrates that our injected backdoor: 1) incurs negligible classification loss, 2) achieves 100% attack success rates, and 3) bypasses six existing state-of-the-art defenses. Moreover, our comparison with a state-of-the-art non-data-free backdoor attack shows our attack is more stealthy and effective against various defenses while achieving less classification accuracy loss.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
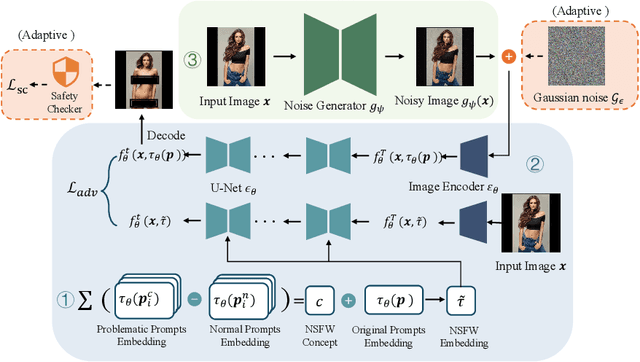


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.
On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Jun 04, 2024


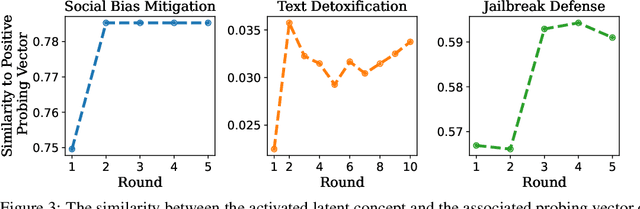
Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.
XPrompt:Explaining Large Language Model's Generation via Joint Prompt Attribution
May 30, 2024
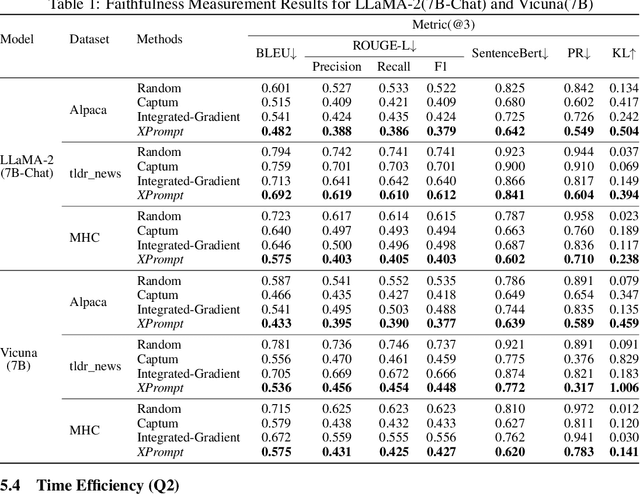
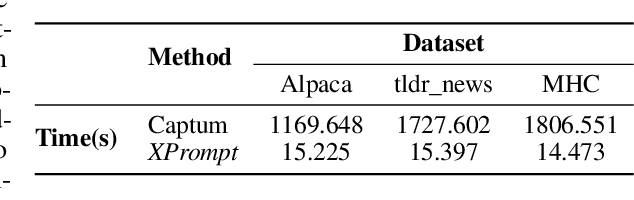

Large Language Models (LLMs) have demonstrated impressive performances in complex text generation tasks. However, the contribution of the input prompt to the generated content still remains obscure to humans, underscoring the necessity of elucidating and explaining the causality between input and output pairs. Existing works for providing prompt-specific explanation often confine model output to be classification or next-word prediction. Few initial attempts aiming to explain the entire language generation often treat input prompt texts independently, ignoring their combinatorial effects on the follow-up generation. In this study, we introduce a counterfactual explanation framework based on joint prompt attribution, XPrompt, which aims to explain how a few prompt texts collaboratively influences the LLM's complete generation. Particularly, we formulate the task of prompt attribution for generation interpretation as a combinatorial optimization problem, and introduce a probabilistic algorithm to search for the casual input combination in the discrete space. We define and utilize multiple metrics to evaluate the produced explanations, demonstrating both faithfulness and efficiency of our framework.
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization
May 28, 2024



Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM. Recent endeavors have introduced more lightweight strategies, focusing on extracting "steering vectors" to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios. This work proposes an innovative approach that could produce more effective steering vectors through bi-directional preference optimization. Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities. Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach. Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously.
WordGame: Efficient & Effective LLM Jailbreak via Simultaneous Obfuscation in Query and Response
May 22, 2024



The recent breakthrough in large language models (LLMs) such as ChatGPT has revolutionized production processes at an unprecedented pace. Alongside this progress also comes mounting concerns about LLMs' susceptibility to jailbreaking attacks, which leads to the generation of harmful or unsafe content. While safety alignment measures have been implemented in LLMs to mitigate existing jailbreak attempts and force them to become increasingly complicated, it is still far from perfect. In this paper, we analyze the common pattern of the current safety alignment and show that it is possible to exploit such patterns for jailbreaking attacks by simultaneous obfuscation in queries and responses. Specifically, we propose WordGame attack, which replaces malicious words with word games to break down the adversarial intent of a query and encourage benign content regarding the games to precede the anticipated harmful content in the response, creating a context that is hardly covered by any corpus used for safety alignment. Extensive experiments demonstrate that WordGame attack can break the guardrails of the current leading proprietary and open-source LLMs, including the latest Claude-3, GPT-4, and Llama-3 models. Further ablation studies on such simultaneous obfuscation in query and response provide evidence of the merits of the attack strategy beyond an individual attack.