 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Diagnose and Correct Moral Errors: Towards Enhancing Moral Sensitivity in Large Language Models
Jan 06, 2026Moral sensitivity is fundamental to human moral competence, as it guides individuals in regulating everyday behavior. Although many approaches seek to align large language models (LLMs) with human moral values, how to enable them morally sensitive has been extremely challenging. In this paper, we take a step toward answering the question: how can we enhance moral sensitivity in LLMs? Specifically, we propose two pragmatic inference methods that faciliate LLMs to diagnose morally benign and hazardous input and correct moral errors, whereby enhancing LLMs' moral sensitivity. A central strength of our pragmatic inference methods is their unified perspective: instead of modeling moral discourses across semantically diverse and complex surface forms, they offer a principled perspective for designing pragmatic inference procedures grounded in their inferential loads. Empirical evidence demonstrates that our pragmatic methods can enhance moral sensitivity in LLMs and achieves strong performance on representative morality-relevant benchmarks.
Towards Understanding Task-agnostic Debiasing Through the Lenses of Intrinsic Bias and Forgetfulness
Jun 06, 2024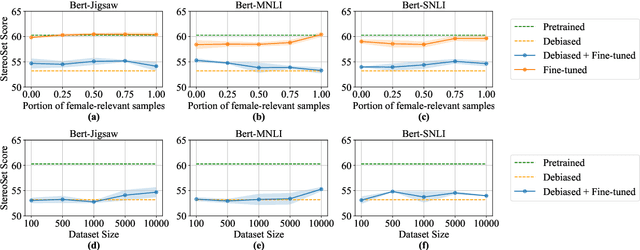
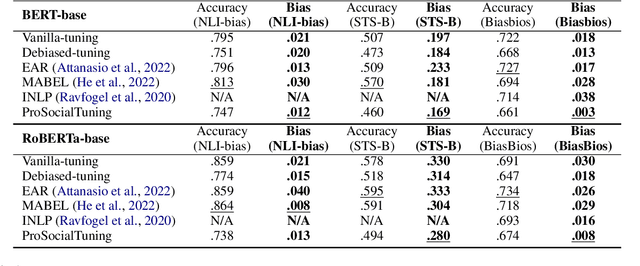
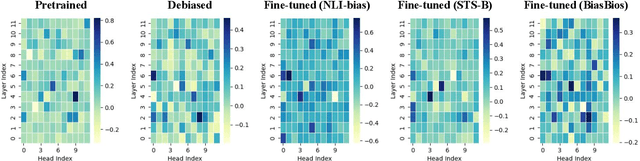

While task-agnostic debiasing provides notable generalizability and reduced reliance on downstream data, its impact on language modeling ability and the risk of relearning social biases from downstream task-specific data remain as the two most significant challenges when debiasing Pretrained Language Models (PLMs). The impact on language modeling ability can be alleviated given a high-quality and long-contextualized debiasing corpus, but there remains a deficiency in understanding the specifics of relearning biases. We empirically ascertain that the effectiveness of task-agnostic debiasing hinges on the quantitative bias level of both the task-specific data used for downstream applications and the debiased model. We empirically show that the lower bound of the bias level of the downstream fine-tuned model can be approximated by the bias level of the debiased model, in most practical cases. To gain more in-depth understanding about how the parameters of PLMs change during fine-tuning due to the forgetting issue of PLMs, we propose a novel framework which can Propagate Socially-fair Debiasing to Downstream Fine-tuning, ProSocialTuning. Our proposed framework can push the fine-tuned model to approach the bias lower bound during downstream fine-tuning, indicating that the ineffectiveness of debiasing can be alleviated by overcoming the forgetting issue through regularizing successfully debiased attention heads based on the PLMs' bias levels from stages of pretraining and debiasing.
On the Intrinsic Self-Correction Capability of LLMs: Uncertainty and Latent Concept
Jun 04, 2024Large Language Models (LLMs) can improve their responses when instructed to do so, a capability known as self-correction. When these instructions lack specific details about the issues in the response, this is referred to as leveraging the intrinsic self-correction capability. The empirical success of self-correction can be found in various applications, e.g., text detoxification and social bias mitigation. However, leveraging this self-correction capability may not always be effective, as it has the potential to revise an initially correct response into an incorrect one. In this paper, we endeavor to understand how and why leveraging the self-correction capability is effective. We identify that appropriate instructions can guide LLMs to a convergence state, wherein additional self-correction steps do not yield further performance improvements. We empirically demonstrate that model uncertainty and activated latent concepts jointly characterize the effectiveness of self-correction. Furthermore, we provide a mathematical formulation indicating that the activated latent concept drives the convergence of the model uncertainty and self-correction performance. Our analysis can also be generalized to the self-correction behaviors observed in Vision-Language Models (VLMs). Moreover, we highlight that task-agnostic debiasing can benefit from our principle in terms of selecting effective fine-tuning samples. Such initial success demonstrates the potential extensibility for better instruction tuning and safety alignment.