 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Task-agnostic Debiasing Through the Lenses of Intrinsic Bias and Forgetfulness
Jun 06, 2024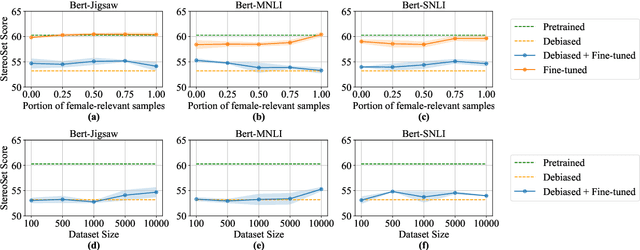
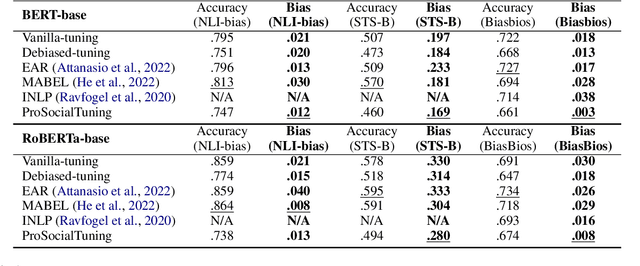
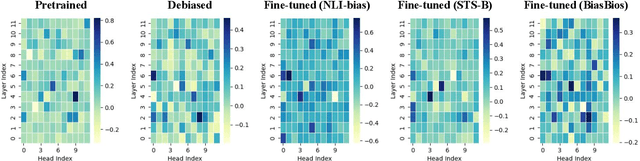

While task-agnostic debiasing provides notable generalizability and reduced reliance on downstream data, its impact on language modeling ability and the risk of relearning social biases from downstream task-specific data remain as the two most significant challenges when debiasing Pretrained Language Models (PLMs). The impact on language modeling ability can be alleviated given a high-quality and long-contextualized debiasing corpus, but there remains a deficiency in understanding the specifics of relearning biases. We empirically ascertain that the effectiveness of task-agnostic debiasing hinges on the quantitative bias level of both the task-specific data used for downstream applications and the debiased model. We empirically show that the lower bound of the bias level of the downstream fine-tuned model can be approximated by the bias level of the debiased model, in most practical cases. To gain more in-depth understanding about how the parameters of PLMs change during fine-tuning due to the forgetting issue of PLMs, we propose a novel framework which can Propagate Socially-fair Debiasing to Downstream Fine-tuning, ProSocialTuning. Our proposed framework can push the fine-tuned model to approach the bias lower bound during downstream fine-tuning, indicating that the ineffectiveness of debiasing can be alleviated by overcoming the forgetting issue through regularizing successfully debiased attention heads based on the PLMs' bias levels from stages of pretraining and debiasing.
On the Susceptibility and Robustness of Time Series Models through Adversarial Attack and Defense
Jan 09, 2023Under adversarial attacks, time series regression and classification are vulnerable. Adversarial defense, on the other hand, can make the models more resilient. It is important to evaluate how vulnerable different time series models are to attacks and how well they recover using defense. The sensitivity to various attacks and the robustness using the defense of several time series models are investigated in this study. Experiments are run on seven-time series models with three adversarial attacks and one adversarial defense. According to the findings, all models, particularly GRU and RNN, appear to be vulnerable. LSTM and GRU also have better defense recovery. FGSM exceeds the competitors in terms of attacks. PGD attacks are more difficult to recover from than other sorts of attacks.