 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect, Concise and Complete: Multi-stage Training For Adaptive Reasoning
Jan 06, 2026The reasoning capabilities of large language models (LLMs) have improved substantially through increased test-time computation, typically in the form of intermediate tokens known as chain-of-thought (CoT). However, CoT often becomes unnecessarily long, increasing computation cost without actual accuracy gains or sometimes even degrading performance, a phenomenon known as ``overthinking''. We propose a multi-stage efficient reasoning method that combines supervised fine-tuning -- via rejection sampling or reasoning trace reformatting -- with reinforcement learning using an adaptive length penalty. We introduce a lightweight reward function that penalizes tokens generated after the first correct answer but encouraging self-verification only when beneficial. We conduct a holistic evaluation across seven diverse reasoning tasks, analyzing the accuracy-response length trade-off. Our approach reduces response length by an average of 28\% for 8B models and 40\% for 32B models, while incurring only minor performance drops of 1.6 and 2.5 points, respectively. Despite its conceptual simplicity, it achieves a superior trade-off compared to more complex state-of-the-art efficient reasoning methods, scoring 76.6, in terms of the area under the Overthinking-Adjusted Accuracy curve ($\text{AUC}_{\text{OAA}}$) -- 5 points above the base model and 2.5 points above the second-best approach.
On the Difficulty of Defending Contrastive Learning against Backdoor Attacks
Dec 14, 2023
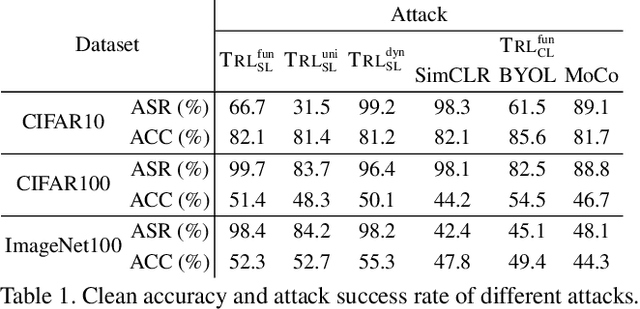
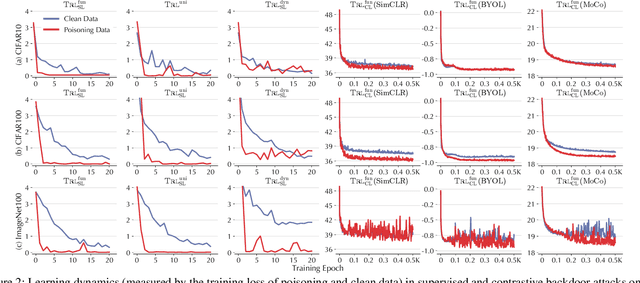
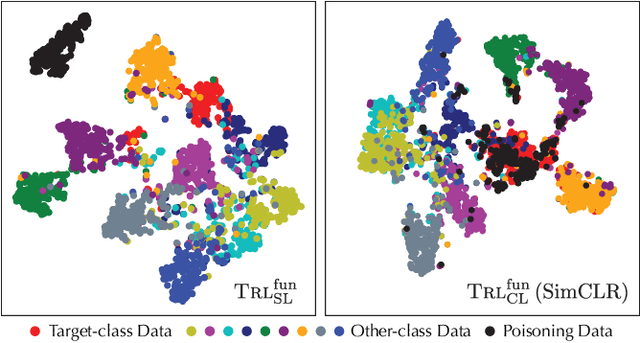
Recent studies have shown that contrastive learning, like supervised learning, is highly vulnerable to backdoor attacks wherein malicious functions are injected into target models, only to be activated by specific triggers. However, thus far it remains under-explored how contrastive backdoor attacks fundamentally differ from their supervised counterparts, which impedes the development of effective defenses against the emerging threat. This work represents a solid step toward answering this critical question. Specifically, we define TRL, a unified framework that encompasses both supervised and contrastive backdoor attacks. Through the lens of TRL, we uncover that the two types of attacks operate through distinctive mechanisms: in supervised attacks, the learning of benign and backdoor tasks tends to occur independently, while in contrastive attacks, the two tasks are deeply intertwined both in their representations and throughout their learning processes. This distinction leads to the disparate learning dynamics and feature distributions of supervised and contrastive attacks. More importantly, we reveal that the specificities of contrastive backdoor attacks entail important implications from a defense perspective: existing defenses for supervised attacks are often inadequate and not easily retrofitted to contrastive attacks. We also explore several alternative defenses and discuss their potential challenges. Our findings highlight the need for defenses tailored to the specificities of contrastive backdoor attacks, pointing to promising directions for future research.
Model Extraction Attacks Revisited
Dec 08, 2023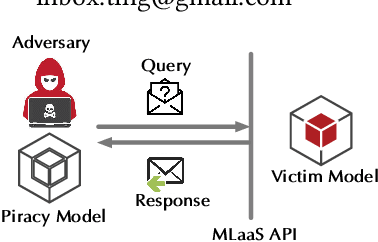

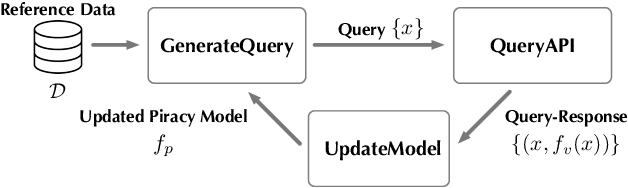
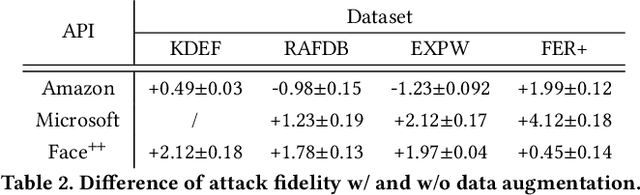
Model extraction (ME) attacks represent one major threat to Machine-Learning-as-a-Service (MLaaS) platforms by ``stealing'' the functionality of confidential machine-learning models through querying black-box APIs. Over seven years have passed since ME attacks were first conceptualized in the seminal work. During this period, substantial advances have been made in both ME attacks and MLaaS platforms, raising the intriguing question: How has the vulnerability of MLaaS platforms to ME attacks been evolving? In this work, we conduct an in-depth study to answer this critical question. Specifically, we characterize the vulnerability of current, mainstream MLaaS platforms to ME attacks from multiple perspectives including attack strategies, learning techniques, surrogate-model design, and benchmark tasks. Many of our findings challenge previously reported results, suggesting emerging patterns of ME vulnerability. Further, by analyzing the vulnerability of the same MLaaS platforms using historical datasets from the past four years, we retrospectively characterize the evolution of ME vulnerability over time, leading to a set of interesting findings. Finally, we make suggestions about improving the current practice of MLaaS in terms of attack robustness. Our study sheds light on the current state of ME vulnerability in the wild and points to several promising directions for future research.
Defending Pre-trained Language Models as Few-shot Learners against Backdoor Attacks
Sep 23, 2023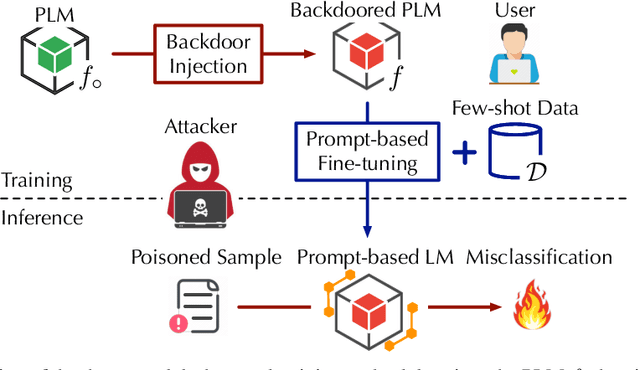
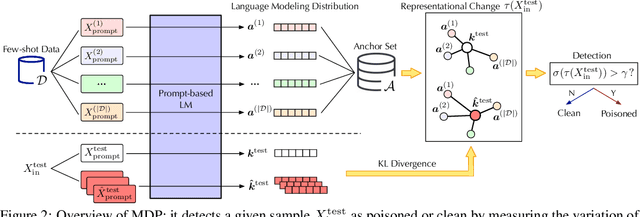
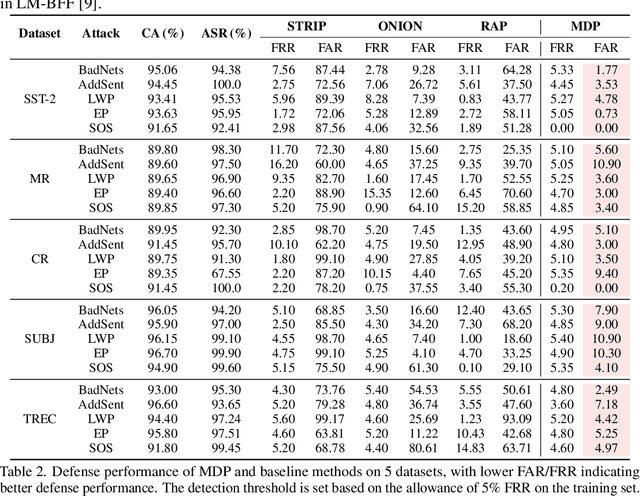
Pre-trained language models (PLMs) have demonstrated remarkable performance as few-shot learners. However, their security risks under such settings are largely unexplored. In this work, we conduct a pilot study showing that PLMs as few-shot learners are highly vulnerable to backdoor attacks while existing defenses are inadequate due to the unique challenges of few-shot scenarios. To address such challenges, we advocate MDP, a novel lightweight, pluggable, and effective defense for PLMs as few-shot learners. Specifically, MDP leverages the gap between the masking-sensitivity of poisoned and clean samples: with reference to the limited few-shot data as distributional anchors, it compares the representations of given samples under varying masking and identifies poisoned samples as ones with significant variations. We show analytically that MDP creates an interesting dilemma for the attacker to choose between attack effectiveness and detection evasiveness. The empirical evaluation using benchmark datasets and representative attacks validates the efficacy of MDP.
On the Security Risks of Knowledge Graph Reasoning
May 03, 2023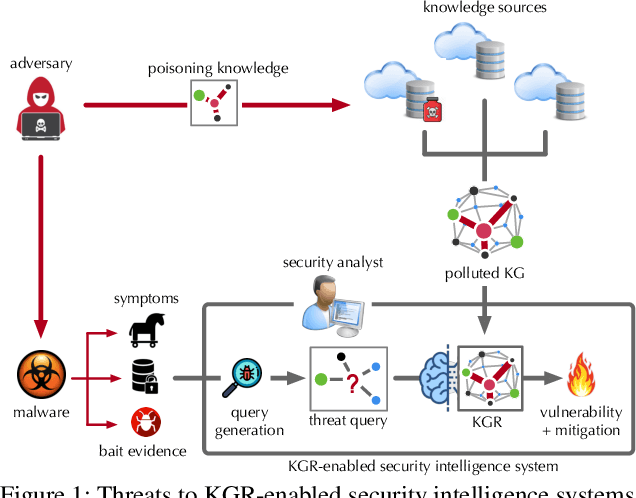
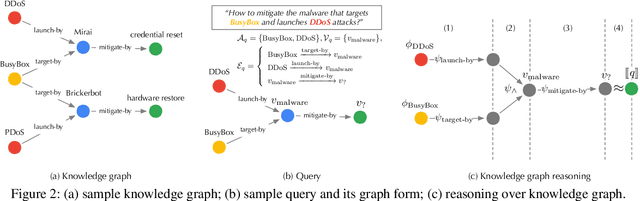
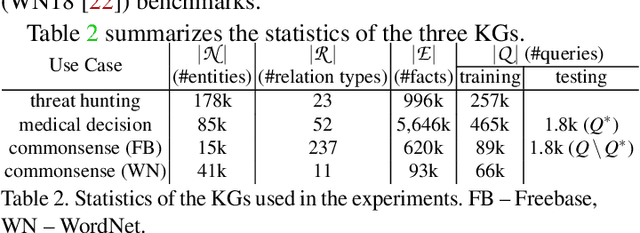
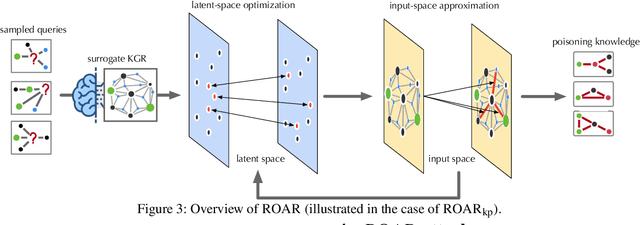
Knowledge graph reasoning (KGR) -- answering complex logical queries over large knowledge graphs -- represents an important artificial intelligence task, entailing a range of applications (e.g., cyber threat hunting). However, despite its surging popularity, the potential security risks of KGR are largely unexplored, which is concerning, given the increasing use of such capability in security-critical domains. This work represents a solid initial step towards bridging the striking gap. We systematize the security threats to KGR according to the adversary's objectives, knowledge, and attack vectors. Further, we present ROAR, a new class of attacks that instantiate a variety of such threats. Through empirical evaluation in representative use cases (e.g., medical decision support, cyber threat hunting, and commonsense reasoning), we demonstrate that ROAR is highly effective to mislead KGR to suggest pre-defined answers for target queries, yet with negligible impact on non-target ones. Finally, we explore potential countermeasures against ROAR, including filtering of potentially poisoning knowledge and training with adversarially augmented queries, which leads to several promising research directions.
Demystifying Self-supervised Trojan Attacks
Oct 13, 2022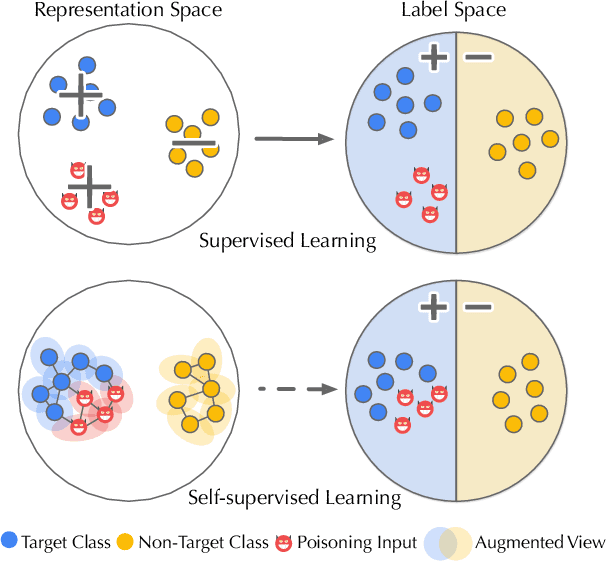
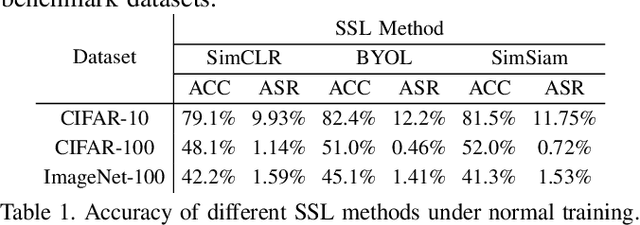
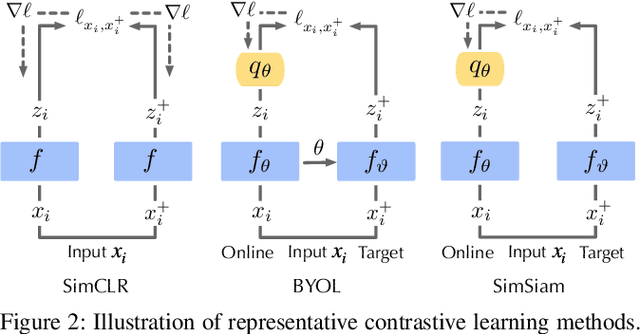
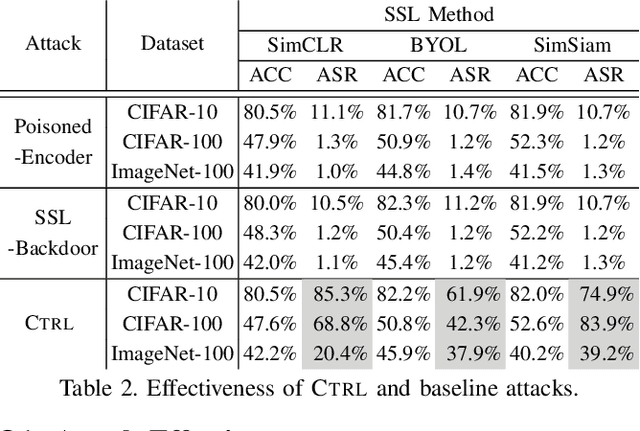
As an emerging machine learning paradigm, self-supervised learning (SSL) is able to learn high-quality representations for complex data without data labels. Prior work shows that, besides obviating the reliance on labeling, SSL also benefits adversarial robustness by making it more challenging for the adversary to manipulate model prediction. However, whether this robustness benefit generalizes to other types of attacks remains an open question. We explore this question in the context of trojan attacks by showing that SSL is comparably vulnerable as supervised learning to trojan attacks. Specifically, we design and evaluate CTRL, an extremely simple self-supervised trojan attack. By polluting a tiny fraction of training data (less than 1%) with indistinguishable poisoning samples, CTRL causes any trigger-embedded input to be misclassified to the adversary's desired class with a high probability (over 99%) at inference. More importantly, through the lens of CTRL, we study the mechanisms underlying self-supervised trojan attacks. With both empirical and analytical evidence, we reveal that the representation invariance property of SSL, which benefits adversarial robustness, may also be the very reason making SSL highly vulnerable to trojan attacks. We further discuss the fundamental challenges to defending against self-supervised trojan attacks, pointing to promising directions for future research.
Reasoning over Multi-view Knowledge Graphs
Sep 27, 2022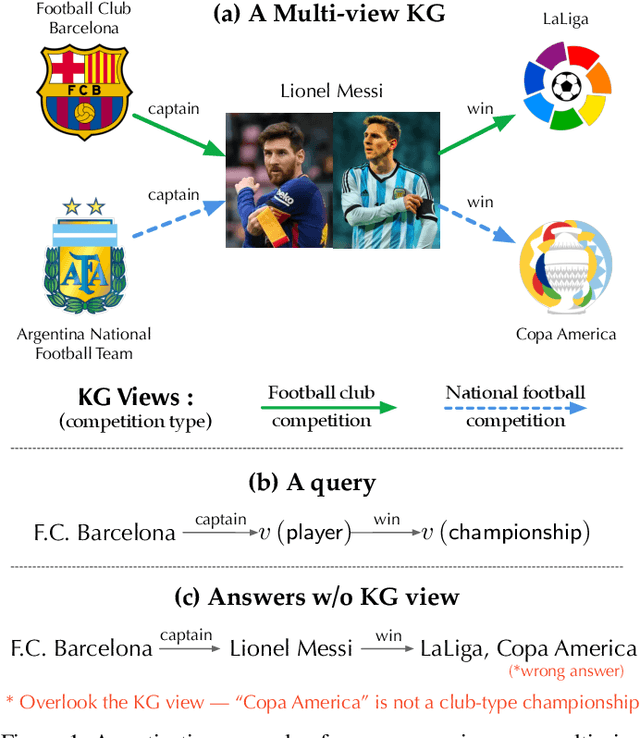
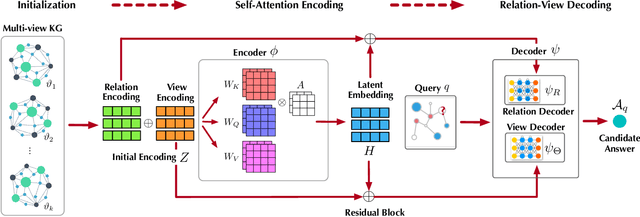
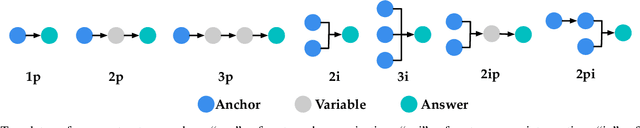
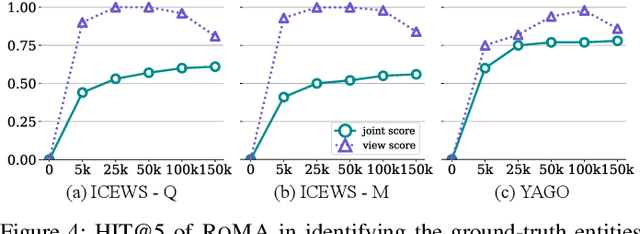
Recently, knowledge representation learning (KRL) is emerging as the state-of-the-art approach to process queries over knowledge graphs (KGs), wherein KG entities and the query are embedded into a latent space such that entities that answer the query are embedded close to the query. Yet, despite the intensive research on KRL, most existing studies either focus on homogenous KGs or assume KG completion tasks (i.e., inference of missing facts), while answering complex logical queries over KGs with multiple aspects (multi-view KGs) remains an open challenge. To bridge this gap, in this paper, we present ROMA, a novel KRL framework for answering logical queries over multi-view KGs. Compared with the prior work, ROMA departs in major aspects. (i) It models a multi-view KG as a set of overlaying sub-KGs, each corresponding to one view, which subsumes many types of KGs studied in the literature (e.g., temporal KGs). (ii) It supports complex logical queries with varying relation and view constraints (e.g., with complex topology and/or from multiple views); (iii) It scales up to KGs of large sizes (e.g., millions of facts) and fine-granular views (e.g., dozens of views); (iv) It generalizes to query structures and KG views that are unobserved during training. Extensive empirical evaluation on real-world KGs shows that \system significantly outperforms alternative methods.
On the Security Risks of AutoML
Oct 12, 2021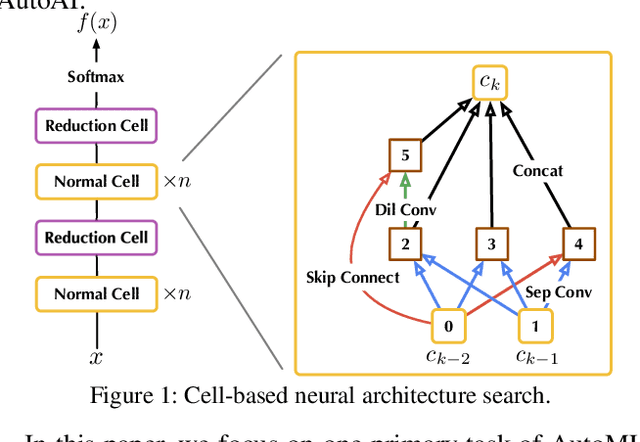
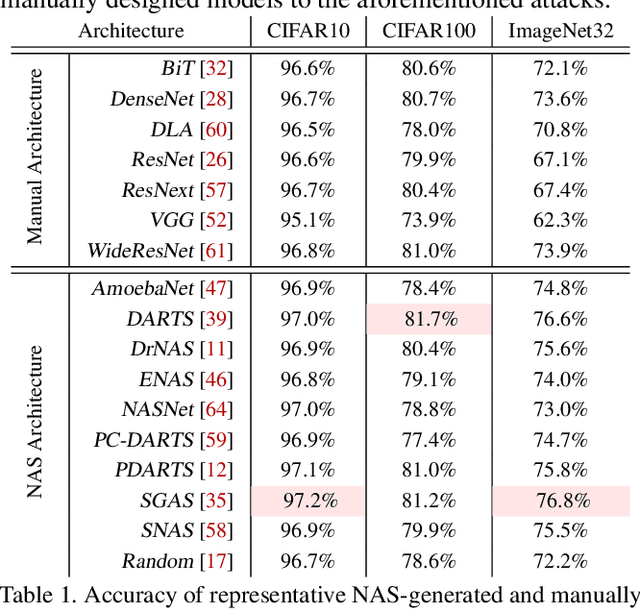
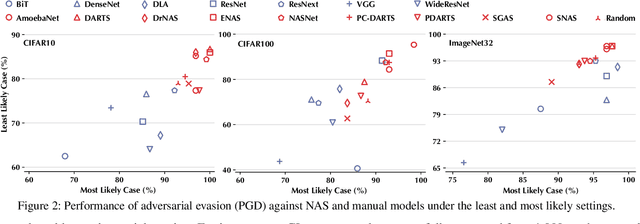
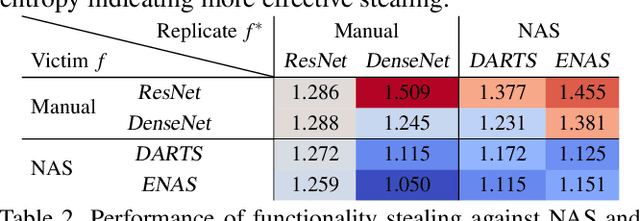
Neural Architecture Search (NAS) represents an emerging machine learning (ML) paradigm that automatically searches for models tailored to given tasks, which greatly simplifies the development of ML systems and propels the trend of ML democratization. Yet, little is known about the potential security risks incurred by NAS, which is concerning given the increasing use of NAS-generated models in critical domains. This work represents a solid initial step towards bridging the gap. Through an extensive empirical study of 10 popular NAS methods, we show that compared with their manually designed counterparts, NAS-generated models tend to suffer greater vulnerability to various malicious attacks (e.g., adversarial evasion, model poisoning, and functionality stealing). Further, with both empirical and analytical evidence, we provide possible explanations for such phenomena: given the prohibitive search space and training cost, most NAS methods favor models that converge fast at early training stages; this preference results in architectural properties associated with attack vulnerability (e.g., high loss smoothness and low gradient variance). Our findings not only reveal the relationships between model characteristics and attack vulnerability but also suggest the inherent connections underlying different attacks. Finally, we discuss potential remedies to mitigate such drawbacks, including increasing cell depth and suppressing skip connects, which lead to several promising research directions.
i-Algebra: Towards Interactive Interpretability of Deep Neural Networks
Jan 22, 2021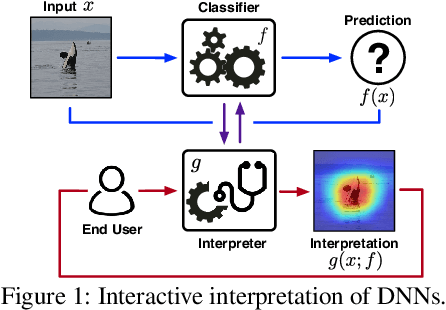
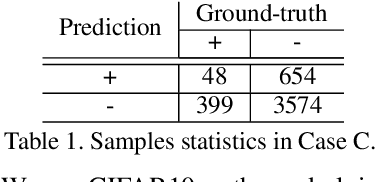
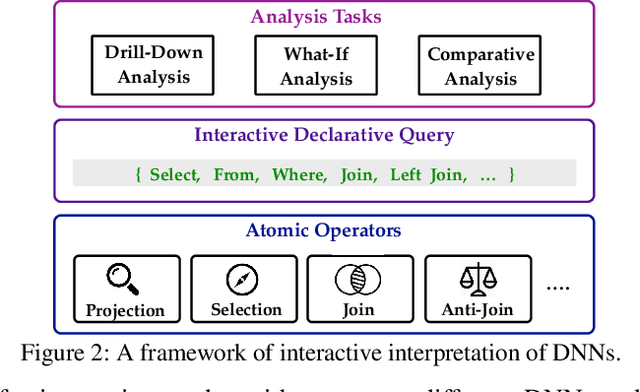

Providing explanations for deep neural networks (DNNs) is essential for their use in domains wherein the interpretability of decisions is a critical prerequisite. Despite the plethora of work on interpreting DNNs, most existing solutions offer interpretability in an ad hoc, one-shot, and static manner, without accounting for the perception, understanding, or response of end-users, resulting in their poor usability in practice. In this paper, we argue that DNN interpretability should be implemented as the interactions between users and models. We present i-Algebra, a first-of-its-kind interactive framework for interpreting DNNs. At its core is a library of atomic, composable operators, which explain model behaviors at varying input granularity, during different inference stages, and from distinct interpretation perspectives. Leveraging a declarative query language, users are enabled to build various analysis tools (e.g., "drill-down", "comparative", "what-if" analysis) via flexibly composing such operators. We prototype i-Algebra and conduct user studies in a set of representative analysis tasks, including inspecting adversarial inputs, resolving model inconsistency, and cleansing contaminated data, all demonstrating its promising usability.
TROJANZOO: Everything you ever wanted to know about neural backdoors
Dec 22, 2020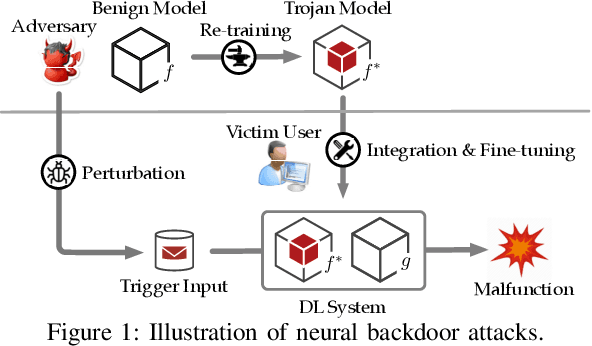
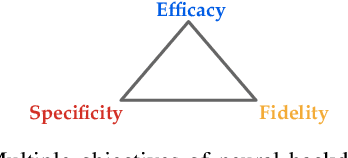
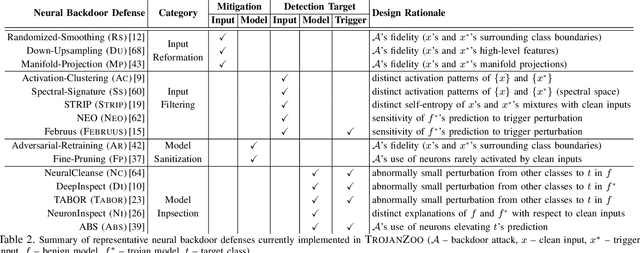
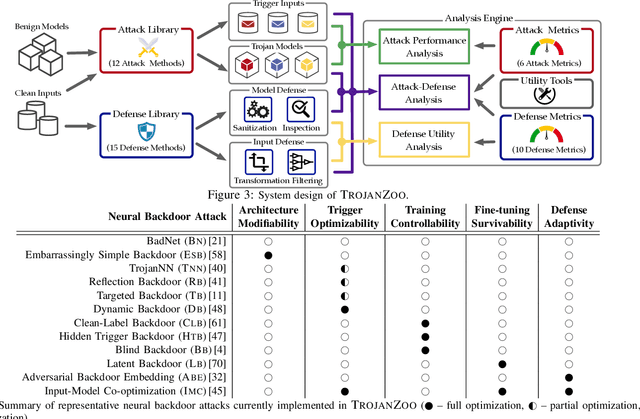
Neural backdoors represent one primary threat to the security of deep learning systems. The intensive research on this subject has produced a plethora of attacks/defenses, resulting in a constant arms race. However, due to the lack of evaluation benchmarks, many critical questions remain largely unexplored: (i) How effective, evasive, or transferable are different attacks? (ii) How robust, utility-preserving, or generic are different defenses? (iii) How do various factors (e.g., model architectures) impact their performance? (iv) What are the best practices (e.g., optimization strategies) to operate such attacks/defenses? (v) How can the existing attacks/defenses be further improved? To bridge the gap, we design and implement TROJANZOO, the first open-source platform for evaluating neural backdoor attacks/defenses in a unified, holistic, and practical manner. Thus, it has incorporated 12 representative attacks, 15 state-of-the-art defenses, 6 attack performance metrics, 10 defense utility metrics, as well as rich tools for in-depth analysis of attack-defense interactions. Leveraging TROJANZOO, we conduct a systematic study of existing attacks/defenses, leading to a number of interesting findings: (i) different attacks manifest various trade-offs among multiple desiderata (e.g., effectiveness, evasiveness, and transferability); (ii) one-pixel triggers often suffice; (iii) optimizing trigger patterns and trojan models jointly improves both attack effectiveness and evasiveness; (iv) sanitizing trojan models often introduces new vulnerabilities; (v) most defenses are ineffective against adaptive attacks, but integrating complementary ones significantly enhances defense robustness. We envision that such findings will help users select the right defense solutions and facilitate future research on neural backdoors.