 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriFi: Towards Verifiable Federated Unlearning
May 25, 2022


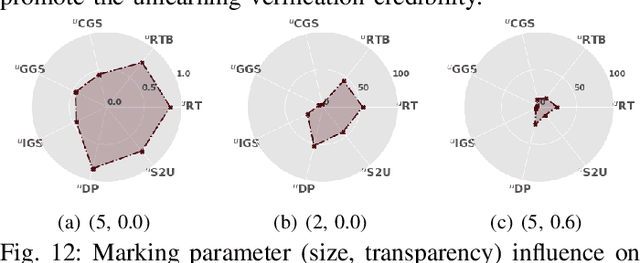
Federated learning (FL) is a collaborative learning paradigm where participants jointly train a powerful model without sharing their private data. One desirable property for FL is the implementation of the right to be forgotten (RTBF), i.e., a leaving participant has the right to request to delete its private data from the global model. However, unlearning itself may not be enough to implement RTBF unless the unlearning effect can be independently verified, an important aspect that has been overlooked in the current literature. In this paper, we prompt the concept of verifiable federated unlearning, and propose VeriFi, a unified framework integrating federated unlearning and verification that allows systematic analysis of the unlearning and quantification of its effect, with different combinations of multiple unlearning and verification methods. In VeriFi, the leaving participant is granted the right to verify (RTV), that is, the participant notifies the server before leaving, then actively verifies the unlearning effect in the next few communication rounds. The unlearning is done at the server side immediately after receiving the leaving notification, while the verification is done locally by the leaving participant via two steps: marking (injecting carefully-designed markers to fingerprint the leaver) and checking (examining the change of the global model's performance on the markers). Based on VeriFi, we conduct the first systematic and large-scale study for verifiable federated unlearning, considering 7 unlearning methods and 5 verification methods. Particularly, we propose a more efficient and FL-friendly unlearning method, and two more effective and robust non-invasive-verification methods. We extensively evaluate VeriFi on 7 datasets and 4 types of deep learning models. Our analysis establishes important empirical understandings for more trustworthy federated unlearning.
TROJANZOO: Everything you ever wanted to know about neural backdoors
Dec 22, 2020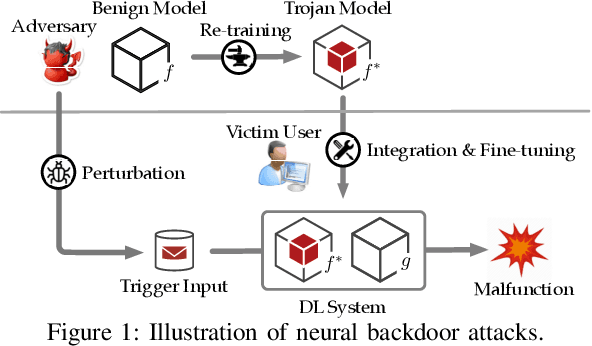
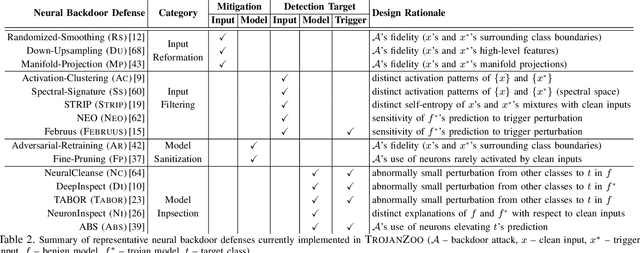
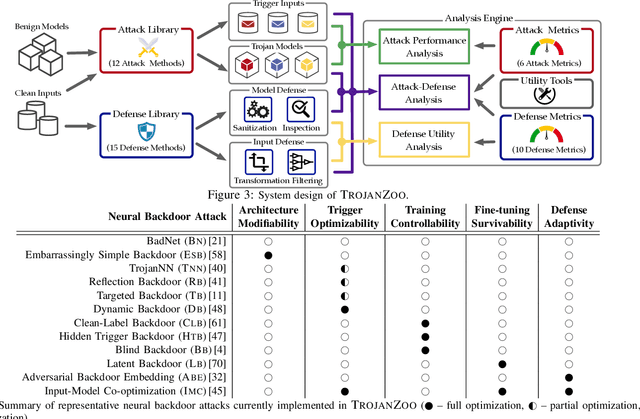
Neural backdoors represent one primary threat to the security of deep learning systems. The intensive research on this subject has produced a plethora of attacks/defenses, resulting in a constant arms race. However, due to the lack of evaluation benchmarks, many critical questions remain largely unexplored: (i) How effective, evasive, or transferable are different attacks? (ii) How robust, utility-preserving, or generic are different defenses? (iii) How do various factors (e.g., model architectures) impact their performance? (iv) What are the best practices (e.g., optimization strategies) to operate such attacks/defenses? (v) How can the existing attacks/defenses be further improved? To bridge the gap, we design and implement TROJANZOO, the first open-source platform for evaluating neural backdoor attacks/defenses in a unified, holistic, and practical manner. Thus, it has incorporated 12 representative attacks, 15 state-of-the-art defenses, 6 attack performance metrics, 10 defense utility metrics, as well as rich tools for in-depth analysis of attack-defense interactions. Leveraging TROJANZOO, we conduct a systematic study of existing attacks/defenses, leading to a number of interesting findings: (i) different attacks manifest various trade-offs among multiple desiderata (e.g., effectiveness, evasiveness, and transferability); (ii) one-pixel triggers often suffice; (iii) optimizing trigger patterns and trojan models jointly improves both attack effectiveness and evasiveness; (iv) sanitizing trojan models often introduces new vulnerabilities; (v) most defenses are ineffective against adaptive attacks, but integrating complementary ones significantly enhances defense robustness. We envision that such findings will help users select the right defense solutions and facilitate future research on neural backdoors.