 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Medical Large Vision-Language Models via Alignment Distillation
Dec 21, 2025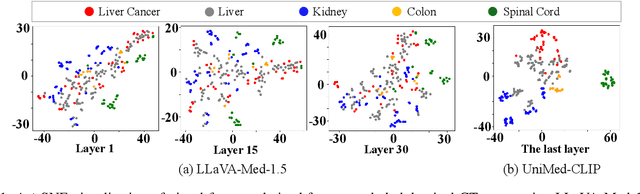
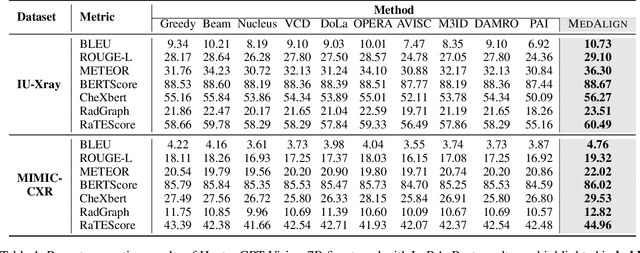
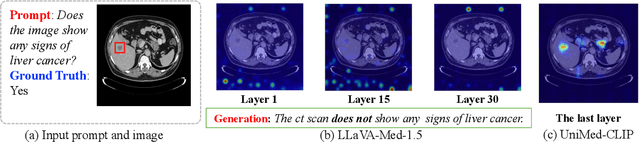
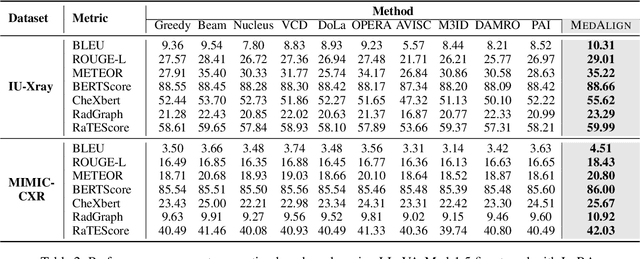
Medical Large Vision-Language Models (Med-LVLMs) have shown promising results in clinical applications, but often suffer from hallucinated outputs due to misaligned visual understanding. In this work, we identify two fundamental limitations contributing to this issue: insufficient visual representation learning and poor visual attention alignment. To address these problems, we propose MEDALIGN, a simple, lightweight alignment distillation framework that transfers visual alignment knowledge from a domain-specific Contrastive Language-Image Pre-training (CLIP) model to Med-LVLMs. MEDALIGN introduces two distillation losses: a spatial-aware visual alignment loss based on visual token-level similarity structures, and an attention-aware distillation loss that guides attention toward diagnostically relevant regions. Extensive experiments on medical report generation and medical visual question answering (VQA) benchmarks show that MEDALIGN consistently improves both performance and interpretability, yielding more visually grounded outputs.
MeCaMIL: Causality-Aware Multiple Instance Learning for Fair and Interpretable Whole Slide Image Diagnosis
Nov 14, 2025Multiple instance learning (MIL) has emerged as the dominant paradigm for whole slide image (WSI) analysis in computational pathology, achieving strong diagnostic performance through patch-level feature aggregation. However, existing MIL methods face critical limitations: (1) they rely on attention mechanisms that lack causal interpretability, and (2) they fail to integrate patient demographics (age, gender, race), leading to fairness concerns across diverse populations. These shortcomings hinder clinical translation, where algorithmic bias can exacerbate health disparities. We introduce \textbf{MeCaMIL}, a causality-aware MIL framework that explicitly models demographic confounders through structured causal graphs. Unlike prior approaches treating demographics as auxiliary features, MeCaMIL employs principled causal inference -- leveraging do-calculus and collider structures -- to disentangle disease-relevant signals from spurious demographic correlations. Extensive evaluation on three benchmarks demonstrates state-of-the-art performance across CAMELYON16 (ACC/AUC/F1: 0.939/0.983/0.946), TCGA-Lung (0.935/0.979/0.931), and TCGA-Multi (0.977/0.993/0.970, five cancer types). Critically, MeCaMIL achieves superior fairness -- demographic disparity variance drops by over 65% relative reduction on average across attributes, with notable improvements for underserved populations. The framework generalizes to survival prediction (mean C-index: 0.653, +0.017 over best baseline across five cancer types). Ablation studies confirm causal graph structure is essential -- alternative designs yield 0.048 lower accuracy and 4.2x times worse fairness. These results establish MeCaMIL as a principled framework for fair, interpretable, and clinically actionable AI in digital pathology. Code will be released upon acceptance.
Two-Stage Decoupling Framework for Variable-Length Glaucoma Prognosis
Sep 15, 2025Glaucoma is one of the leading causes of irreversible blindness worldwide. Glaucoma prognosis is essential for identifying at-risk patients and enabling timely intervention to prevent blindness. Many existing approaches rely on historical sequential data but are constrained by fixed-length inputs, limiting their flexibility. Additionally, traditional glaucoma prognosis methods often employ end-to-end models, which struggle with the limited size of glaucoma datasets. To address these challenges, we propose a Two-Stage Decoupling Framework (TSDF) for variable-length glaucoma prognosis. In the first stage, we employ a feature representation module that leverages self-supervised learning to aggregate multiple glaucoma datasets for training, disregarding differences in their supervisory information. This approach enables datasets of varying sizes to learn better feature representations. In the second stage, we introduce a temporal aggregation module that incorporates an attention-based mechanism to process sequential inputs of varying lengths, ensuring flexible and efficient utilization of all available data. This design significantly enhances model performance while maintaining a compact parameter size. Extensive experiments on two benchmark glaucoma datasets:the Ocular Hypertension Treatment Study (OHTS) and the Glaucoma Real-world Appraisal Progression Ensemble (GRAPE),which differ significantly in scale and clinical settings,demonstrate the effectiveness and robustness of our approach.
Rethinking Contrastive Learning in Session-based Recommendation
Jun 05, 2025



Session-based recommendation aims to predict intents of anonymous users based on limited behaviors. With the ability in alleviating data sparsity, contrastive learning is prevailing in the task. However, we spot that existing contrastive learning based methods still suffer from three obstacles: (1) they overlook item-level sparsity and primarily focus on session-level sparsity; (2) they typically augment sessions using item IDs like crop, mask and reorder, failing to ensure the semantic consistency of augmented views; (3) they treat all positive-negative signals equally, without considering their varying utility. To this end, we propose a novel multi-modal adaptive contrastive learning framework called MACL for session-based recommendation. In MACL, a multi-modal augmentation is devised to generate semantically consistent views at both item and session levels by leveraging item multi-modal features. Besides, we present an adaptive contrastive loss that distinguishes varying contributions of positive-negative signals to improve self-supervised learning. Extensive experiments on three real-world datasets demonstrate the superiority of MACL over state-of-the-art methods.
Focus on What Matters: Enhancing Medical Vision-Language Models with Automatic Attention Alignment Tuning
May 24, 2025Medical Large Vision-Language Models (Med-LVLMs) often exhibit suboptimal attention distribution on visual inputs, leading to hallucinated or inaccurate outputs. Existing mitigation methods primarily rely on inference-time interventions, which are limited in attention adaptation or require additional supervision. To address this, we propose A$^3$Tune, a novel fine-tuning framework for Automatic Attention Alignment Tuning. A$^3$Tune leverages zero-shot weak labels from SAM, refines them into prompt-aware labels using BioMedCLIP, and then selectively modifies visually-critical attention heads to improve alignment while minimizing interference. Additionally, we introduce a A$^3$MoE module, enabling adaptive parameter selection for attention tuning across diverse prompts and images. Extensive experiments on medical VQA and report generation benchmarks show that A$^3$Tune outperforms state-of-the-art baselines, achieving enhanced attention distributions and performance in Med-LVLMs.
Robustifying Vision-Language Models via Dynamic Token Reweighting
May 22, 2025Large vision-language models (VLMs) are highly vulnerable to jailbreak attacks that exploit visual-textual interactions to bypass safety guardrails. In this paper, we present DTR, a novel inference-time defense that mitigates multimodal jailbreak attacks through optimizing the model's key-value (KV) caches. Rather than relying on curated safety-specific data or costly image-to-text conversion, we introduce a new formulation of the safety-relevant distributional shift induced by the visual modality. This formulation enables DTR to dynamically adjust visual token weights, minimizing the impact of adversarial visual inputs while preserving the model's general capabilities and inference efficiency. Extensive evaluation across diverse VLMs and attack benchmarks demonstrates that \sys outperforms existing defenses in both attack robustness and benign task performance, marking the first successful application of KV cache optimization for safety enhancement in multimodal foundation models. The code for replicating DTR is available: https://anonymous.4open.science/r/DTR-2755 (warning: this paper contains potentially harmful content generated by VLMs.)
MEDMKG: Benchmarking Medical Knowledge Exploitation with Multimodal Knowledge Graph
May 22, 2025Medical deep learning models depend heavily on domain-specific knowledge to perform well on knowledge-intensive clinical tasks. Prior work has primarily leveraged unimodal knowledge graphs, such as the Unified Medical Language System (UMLS), to enhance model performance. However, integrating multimodal medical knowledge graphs remains largely underexplored, mainly due to the lack of resources linking imaging data with clinical concepts. To address this gap, we propose MEDMKG, a Medical Multimodal Knowledge Graph that unifies visual and textual medical information through a multi-stage construction pipeline. MEDMKG fuses the rich multimodal data from MIMIC-CXR with the structured clinical knowledge from UMLS, utilizing both rule-based tools and large language models for accurate concept extraction and relationship modeling. To ensure graph quality and compactness, we introduce Neighbor-aware Filtering (NaF), a novel filtering algorithm tailored for multimodal knowledge graphs. We evaluate MEDMKG across three tasks under two experimental settings, benchmarking twenty-four baseline methods and four state-of-the-art vision-language backbones on six datasets. Results show that MEDMKG not only improves performance in downstream medical tasks but also offers a strong foundation for developing adaptive and robust strategies for multimodal knowledge integration in medical artificial intelligence.
A Survey on Side Information-driven Session-based Recommendation: From a Data-centric Perspective
May 18, 2025Session-based recommendation is gaining increasing attention due to its practical value in predicting the intents of anonymous users based on limited behaviors. Emerging efforts incorporate various side information to alleviate inherent data scarcity issues in this task, leading to impressive performance improvements. The core of side information-driven session-based recommendation is the discovery and utilization of diverse data. In this survey, we provide a comprehensive review of this task from a data-centric perspective. Specifically, this survey commences with a clear formulation of the task. This is followed by a detailed exploration of various benchmarks rich in side information that are pivotal for advancing research in this field. Afterwards, we delve into how different types of side information enhance the task, underscoring data characteristics and utility. Moreover, we discuss the usage of various side information, including data encoding, data injection, and involved techniques. A systematic review of research progress is then presented, with the taxonomy by the types of side information. Finally, we summarize the current limitations and present the future prospects of this vibrant topic.
AutoRAN: Weak-to-Strong Jailbreaking of Large Reasoning Models
May 16, 2025This paper presents AutoRAN, the first automated, weak-to-strong jailbreak attack framework targeting large reasoning models (LRMs). At its core, AutoRAN leverages a weak, less-aligned reasoning model to simulate the target model's high-level reasoning structures, generates narrative prompts, and iteratively refines candidate prompts by incorporating the target model's intermediate reasoning steps. We evaluate AutoRAN against state-of-the-art LRMs including GPT-o3/o4-mini and Gemini-2.5-Flash across multiple benchmark datasets (AdvBench, HarmBench, and StrongReject). Results demonstrate that AutoRAN achieves remarkable success rates (approaching 100%) within one or a few turns across different LRMs, even when judged by a robustly aligned external model. This work reveals that leveraging weak reasoning models can effectively exploit the critical vulnerabilities of much more capable reasoning models, highlighting the need for improved safety measures specifically designed for reasoning-based models. The code for replicating AutoRAN and running records are available at: (https://github.com/JACKPURCELL/AutoRAN-public). (warning: this paper contains potentially harmful content generated by LRMs.)
Brain Effective Connectivity Estimation via Fourier Spatiotemporal Attention
Mar 14, 2025



Estimating brain effective connectivity (EC) from functional magnetic resonance imaging (fMRI) data can aid in comprehending the neural mechanisms underlying human behavior and cognition, providing a foundation for disease diagnosis. However, current spatiotemporal attention modules handle temporal and spatial attention separately, extracting temporal and spatial features either sequentially or in parallel. These approaches overlook the inherent spatiotemporal correlations present in real world fMRI data. Additionally, the presence of noise in fMRI data further limits the performance of existing methods. In this paper, we propose a novel brain effective connectivity estimation method based on Fourier spatiotemporal attention (FSTA-EC), which combines Fourier attention and spatiotemporal attention to simultaneously capture inter-series (spatial) dynamics and intra-series (temporal) dependencies from high-noise fMRI data. Specifically, Fourier attention is designed to convert the high-noise fMRI data to frequency domain, and map the denoised fMRI data back to physical domain, and spatiotemporal attention is crafted to simultaneously learn spatiotemporal dynamics. Furthermore, through a series of proofs, we demonstrate that incorporating learnable filter into fast Fourier transform and inverse fast Fourier transform processes is mathematically equivalent to performing cyclic convolution. The experimental results on simulated and real-resting-state fMRI datasets demonstrate that the proposed method exhibits superior performance when compared to state-of-the-art methods.