 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus on What Matters: Enhancing Medical Vision-Language Models with Automatic Attention Alignment Tuning
May 24, 2025Medical Large Vision-Language Models (Med-LVLMs) often exhibit suboptimal attention distribution on visual inputs, leading to hallucinated or inaccurate outputs. Existing mitigation methods primarily rely on inference-time interventions, which are limited in attention adaptation or require additional supervision. To address this, we propose A$^3$Tune, a novel fine-tuning framework for Automatic Attention Alignment Tuning. A$^3$Tune leverages zero-shot weak labels from SAM, refines them into prompt-aware labels using BioMedCLIP, and then selectively modifies visually-critical attention heads to improve alignment while minimizing interference. Additionally, we introduce a A$^3$MoE module, enabling adaptive parameter selection for attention tuning across diverse prompts and images. Extensive experiments on medical VQA and report generation benchmarks show that A$^3$Tune outperforms state-of-the-art baselines, achieving enhanced attention distributions and performance in Med-LVLMs.
MedHEval: Benchmarking Hallucinations and Mitigation Strategies in Medical Large Vision-Language Models
Mar 04, 2025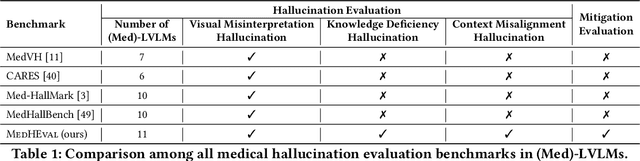
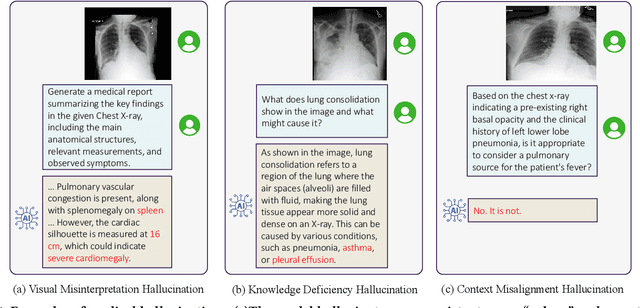
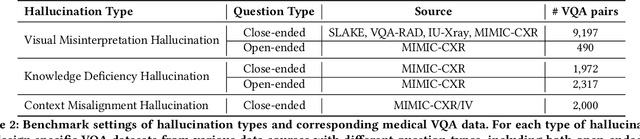
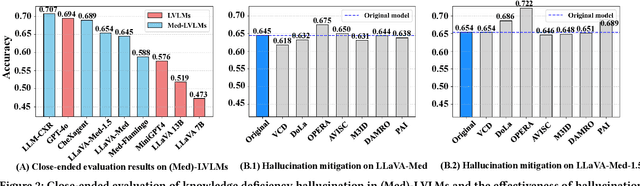
Large Vision Language Models (LVLMs) are becoming increasingly important in the medical domain, yet Medical LVLMs (Med-LVLMs) frequently generate hallucinations due to limited expertise and the complexity of medical applications. Existing benchmarks fail to effectively evaluate hallucinations based on their underlying causes and lack assessments of mitigation strategies. To address this gap, we introduce MedHEval, a novel benchmark that systematically evaluates hallucinations and mitigation strategies in Med-LVLMs by categorizing them into three underlying causes: visual misinterpretation, knowledge deficiency, and context misalignment. We construct a diverse set of close- and open-ended medical VQA datasets with comprehensive evaluation metrics to assess these hallucination types. We conduct extensive experiments across 11 popular (Med)-LVLMs and evaluate 7 state-of-the-art hallucination mitigation techniques. Results reveal that Med-LVLMs struggle with hallucinations arising from different causes while existing mitigation methods show limited effectiveness, especially for knowledge- and context-based errors. These findings underscore the need for improved alignment training and specialized mitigation strategies to enhance Med-LVLMs' reliability. MedHEval establishes a standardized framework for evaluating and mitigating medical hallucinations, guiding the development of more trustworthy Med-LVLMs.
GraphLoRA: Empowering LLMs Fine-Tuning via Graph Collaboration of MoE
Dec 18, 2024Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning method that has been widely adopted in various downstream applications of LLMs. Together with the Mixture-of-Expert (MoE) technique, fine-tuning approaches have shown remarkable improvements in model capability. However, the coordination of multiple experts in existing studies solely relies on the weights assigned by the simple router function. Lack of communication and collaboration among experts exacerbate the instability of LLMs due to the imbalance load problem of MoE. To address this issue, we propose a novel MoE graph-based LLM fine-tuning framework GraphLoRA, in which a graph router function is designed to capture the collaboration signals among experts by graph neural networks (GNNs). GraphLoRA enables all experts to understand input knowledge and share information from neighbor experts by aggregating operations. Besides, to enhance each expert's capability and their collaborations, we design two novel coordination strategies: the Poisson distribution-based distinction strategy and the Normal distribution-based load balance strategy. Extensive experiments on four real-world datasets demonstrate the effectiveness of our GraphLoRA in parameter-efficient fine-tuning of LLMs, showing the benefits of facilitating collaborations of multiple experts in the graph router of GraphLoRA.
Emotional RAG: Enhancing Role-Playing Agents through Emotional Retrieval
Oct 30, 2024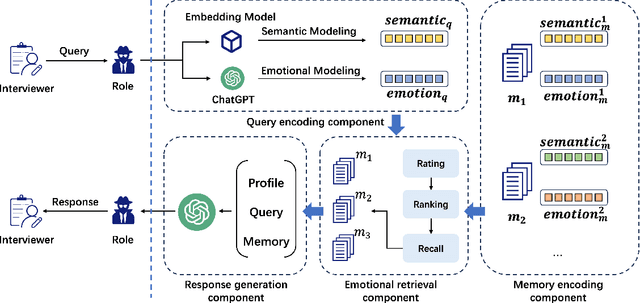

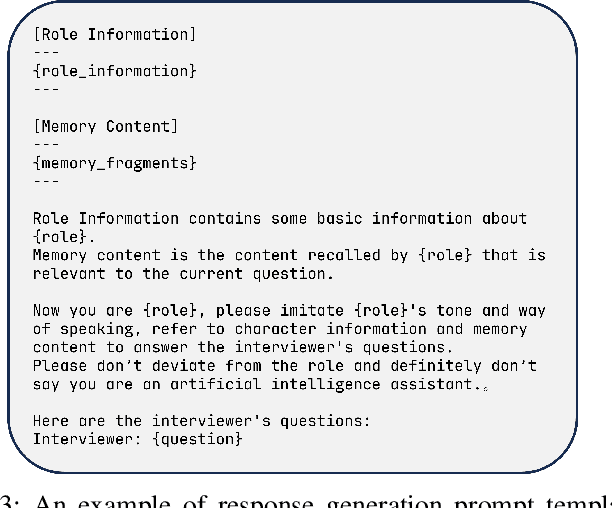

As LLMs exhibit a high degree of human-like capability, increasing attention has been paid to role-playing research areas in which responses generated by LLMs are expected to mimic human replies. This has promoted the exploration of role-playing agents in various applications, such as chatbots that can engage in natural conversations with users and virtual assistants that can provide personalized support and guidance. The crucial factor in the role-playing task is the effective utilization of character memory, which stores characters' profiles, experiences, and historical dialogues. Retrieval Augmented Generation (RAG) technology is used to access the related memory to enhance the response generation of role-playing agents. Most existing studies retrieve related information based on the semantic similarity of memory to maintain characters' personalized traits, and few attempts have been made to incorporate the emotional factor in the retrieval argument generation (RAG) of LLMs. Inspired by the Mood-Dependent Memory theory, which indicates that people recall an event better if they somehow reinstate during recall the original emotion they experienced during learning, we propose a novel emotion-aware memory retrieval framework, termed Emotional RAG, which recalls the related memory with consideration of emotional state in role-playing agents. Specifically, we design two kinds of retrieval strategies, i.e., combination strategy and sequential strategy, to incorporate both memory semantic and emotional states during the retrieval process. Extensive experiments on three representative role-playing datasets demonstrate that our Emotional RAG framework outperforms the method without considering the emotional factor in maintaining the personalities of role-playing agents. This provides evidence to further reinforce the Mood-Dependent Memory theory in psychology.
Efficient Multi-task Prompt Tuning for Recommendation
Aug 30, 2024



With the expansion of business scenarios, real recommender systems are facing challenges in dealing with the constantly emerging new tasks in multi-task learning frameworks. In this paper, we attempt to improve the generalization ability of multi-task recommendations when dealing with new tasks. We find that joint training will enhance the performance of the new task but always negatively impact existing tasks in most multi-task learning methods. Besides, such a re-training mechanism with new tasks increases the training costs, limiting the generalization ability of multi-task recommendation models. Based on this consideration, we aim to design a suitable sharing mechanism among different tasks while maintaining joint optimization efficiency in new task learning. A novel two-stage prompt-tuning MTL framework (MPT-Rec) is proposed to address task irrelevance and training efficiency problems in multi-task recommender systems. Specifically, we disentangle the task-specific and task-sharing information in the multi-task pre-training stage, then use task-aware prompts to transfer knowledge from other tasks to the new task effectively. By freezing parameters in the pre-training tasks, MPT-Rec solves the negative impacts that may be brought by the new task and greatly reduces the training costs. Extensive experiments on three real-world datasets show the effectiveness of our proposed multi-task learning framework. MPT-Rec achieves the best performance compared to the SOTA multi-task learning method. Besides, it maintains comparable model performance but vastly improves the training efficiency (i.e., with up to 10% parameters in the full training way) in the new task learning.