 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
HER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
The Impact of Longitudinal Mammogram Alignment on Breast Cancer Risk Assessment
Nov 11, 2025Regular mammography screening is crucial for early breast cancer detection. By leveraging deep learning-based risk models, screening intervals can be personalized, especially for high-risk individuals. While recent methods increasingly incorporate longitudinal information from prior mammograms, accurate spatial alignment across time points remains a key challenge. Misalignment can obscure meaningful tissue changes and degrade model performance. In this study, we provide insights into various alignment strategies, image-based registration, feature-level (representation space) alignment with and without regularization, and implicit alignment methods, for their effectiveness in longitudinal deep learning-based risk modeling. Using two large-scale mammography datasets, we assess each method across key metrics, including predictive accuracy, precision, recall, and deformation field quality. Our results show that image-based registration consistently outperforms the more recently favored feature-based and implicit approaches across all metrics, enabling more accurate, temporally consistent predictions and generating smooth, anatomically plausible deformation fields. Although regularizing the deformation field improves deformation quality, it reduces the risk prediction performance of feature-level alignment. Applying image-based deformation fields within the feature space yields the best risk prediction performance. These findings underscore the importance of image-based deformation fields for spatial alignment in longitudinal risk modeling, offering improved prediction accuracy and robustness. This approach has strong potential to enhance personalized screening and enable earlier interventions for high-risk individuals. The code is available at https://github.com/sot176/Mammogram_Alignment_Study_Risk_Prediction.git, allowing full reproducibility of the results.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025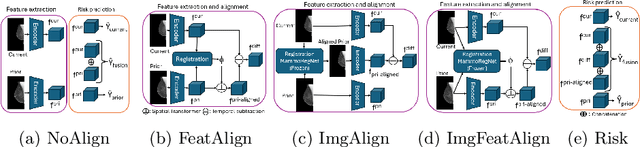
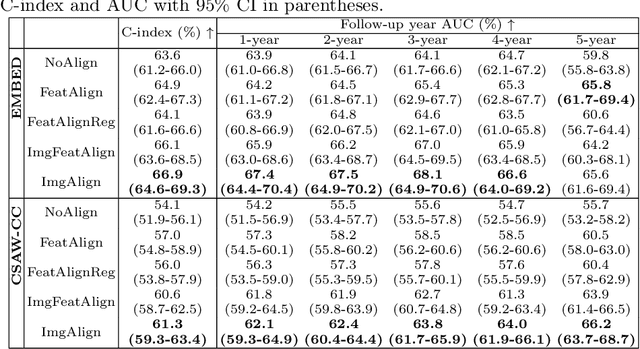
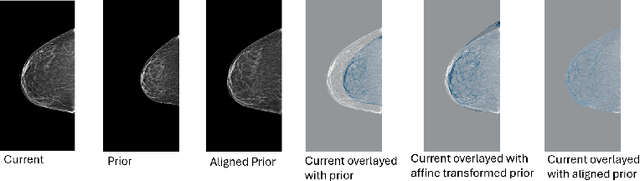

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Emotional RAG: Enhancing Role-Playing Agents through Emotional Retrieval
Oct 30, 2024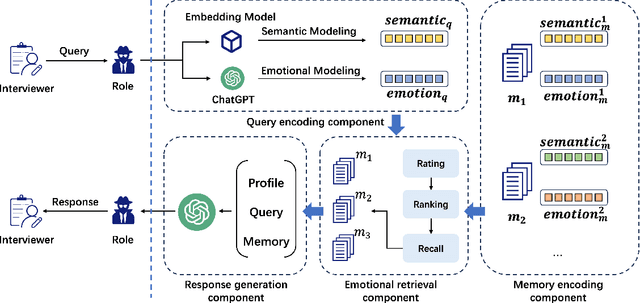


As LLMs exhibit a high degree of human-like capability, increasing attention has been paid to role-playing research areas in which responses generated by LLMs are expected to mimic human replies. This has promoted the exploration of role-playing agents in various applications, such as chatbots that can engage in natural conversations with users and virtual assistants that can provide personalized support and guidance. The crucial factor in the role-playing task is the effective utilization of character memory, which stores characters' profiles, experiences, and historical dialogues. Retrieval Augmented Generation (RAG) technology is used to access the related memory to enhance the response generation of role-playing agents. Most existing studies retrieve related information based on the semantic similarity of memory to maintain characters' personalized traits, and few attempts have been made to incorporate the emotional factor in the retrieval argument generation (RAG) of LLMs. Inspired by the Mood-Dependent Memory theory, which indicates that people recall an event better if they somehow reinstate during recall the original emotion they experienced during learning, we propose a novel emotion-aware memory retrieval framework, termed Emotional RAG, which recalls the related memory with consideration of emotional state in role-playing agents. Specifically, we design two kinds of retrieval strategies, i.e., combination strategy and sequential strategy, to incorporate both memory semantic and emotional states during the retrieval process. Extensive experiments on three representative role-playing datasets demonstrate that our Emotional RAG framework outperforms the method without considering the emotional factor in maintaining the personalities of role-playing agents. This provides evidence to further reinforce the Mood-Dependent Memory theory in psychology.
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
Jun 30, 2021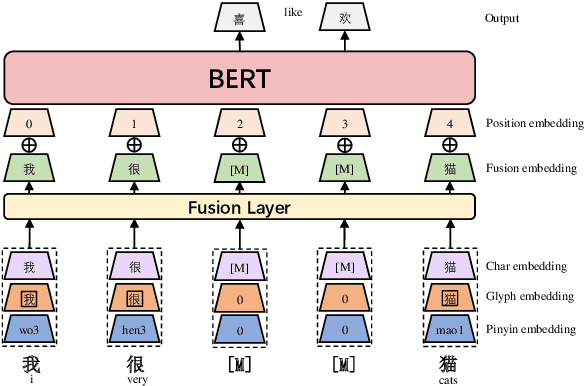

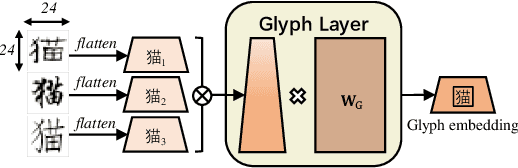
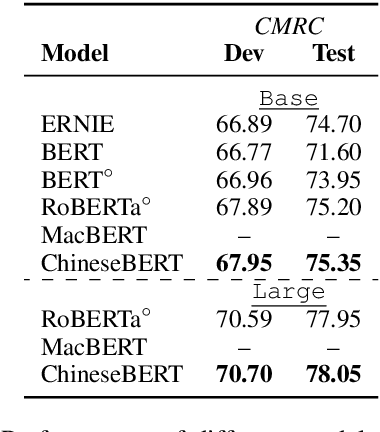
Recent pretraining models in Chinese neglect two important aspects specific to the Chinese language: glyph and pinyin, which carry significant syntax and semantic information for language understanding. In this work, we propose ChineseBERT, which incorporates both the {\it glyph} and {\it pinyin} information of Chinese characters into language model pretraining. The glyph embedding is obtained based on different fonts of a Chinese character, being able to capture character semantics from the visual features, and the pinyin embedding characterizes the pronunciation of Chinese characters, which handles the highly prevalent heteronym phenomenon in Chinese (the same character has different pronunciations with different meanings). Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields significant performance boost over baseline models with fewer training steps. The porpsoed model achieves new SOTA performances on a wide range of Chinese NLP tasks, including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition. Code and pretrained models are publicly available at https://github.com/ShannonAI/ChineseBert.
Self-Explaining Structures Improve NLP Models
Dec 09, 2020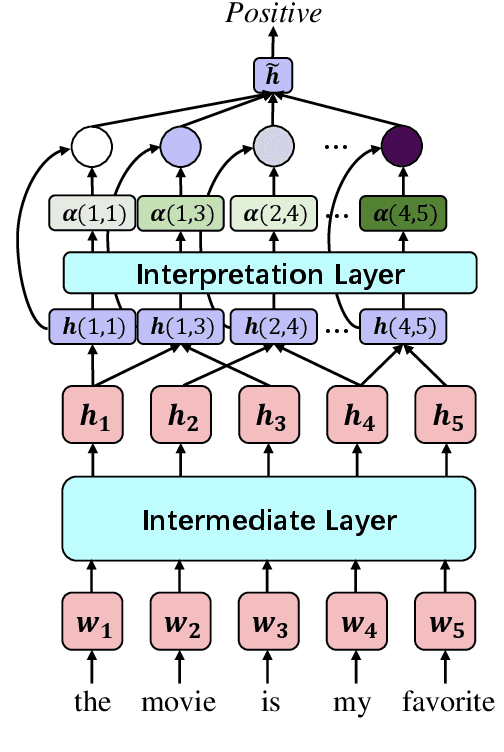
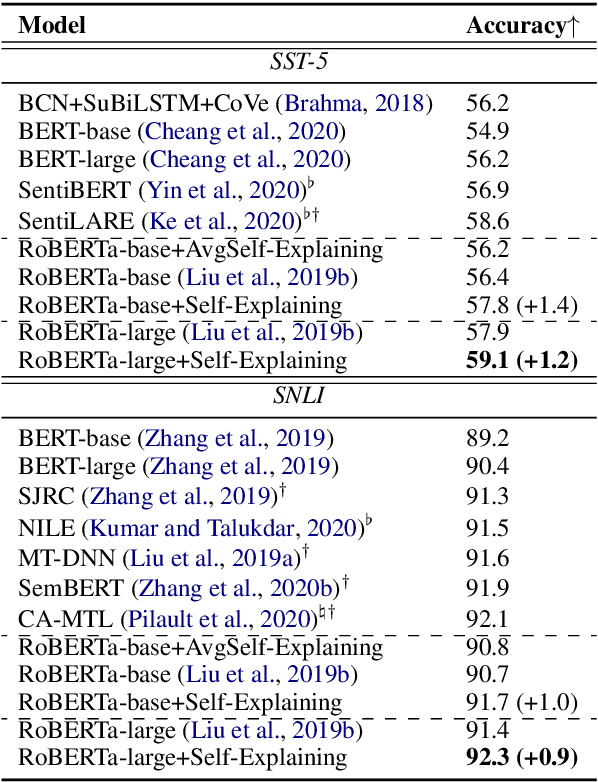

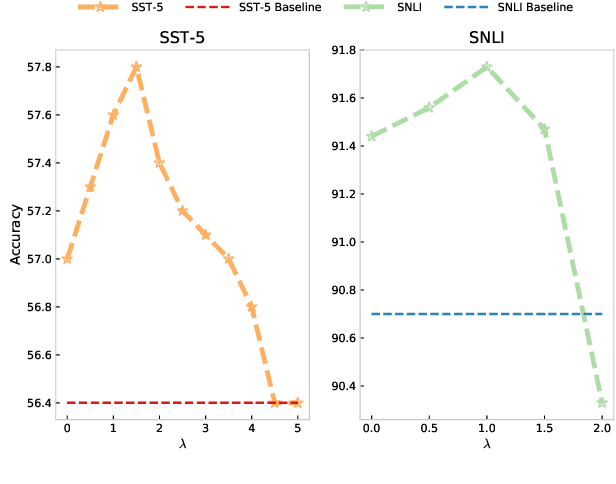
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.
Neural Semi-supervised Learning for Text Classification Under Large-Scale Pretraining
Nov 19, 2020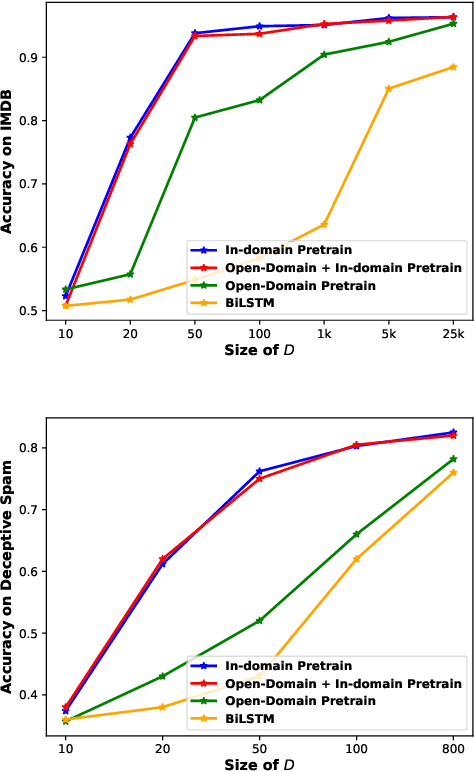
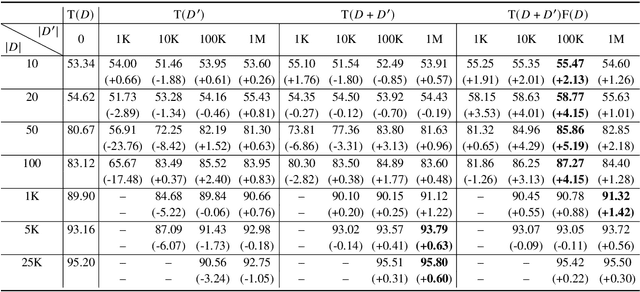
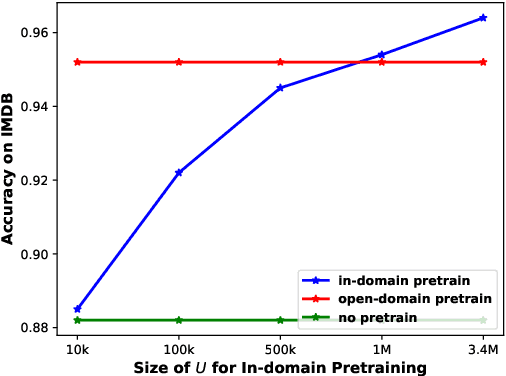

The goal of semi-supervised learning is to utilize the unlabeled, in-domain dataset U to improve models trained on the labeled dataset D. Under the context of large-scale language-model (LM) pretraining, how we can make the best use of U is poorly understood: is semi-supervised learning still beneficial with the presence of large-scale pretraining? should U be used for in-domain LM pretraining or pseudo-label generation? how should the pseudo-label based semi-supervised model be actually implemented? how different semi-supervised strategies affect performances regarding D of different sizes, U of different sizes, etc. In this paper, we conduct comprehensive studies on semi-supervised learning in the task of text classification under the context of large-scale LM pretraining. Our studies shed important lights on the behavior of semi-supervised learning methods: (1) with the presence of in-domain pretraining LM on U, open-domain LM pretraining is unnecessary; (2) both the in-domain pretraining strategy and the pseudo-label based strategy introduce significant performance boosts, with the former performing better with larger U, the latter performing better with smaller U, and the combination leading to the largest performance boost; (3) self-training (pretraining first on pseudo labels D' and then fine-tuning on D) yields better performances when D is small, while joint training on the combination of pseudo labels D' and the original dataset D yields better performances when D is large. Using semi-supervised learning strategies, we are able to achieve a performance of around 93.8% accuracy with only 50 training data points on the IMDB dataset, and a competitive performance of 96.6% with the full IMDB dataset. Our work marks an initial step in understanding the behavior of semi-supervised learning models under the context of large-scale pretraining.
Pair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Oct 31, 2020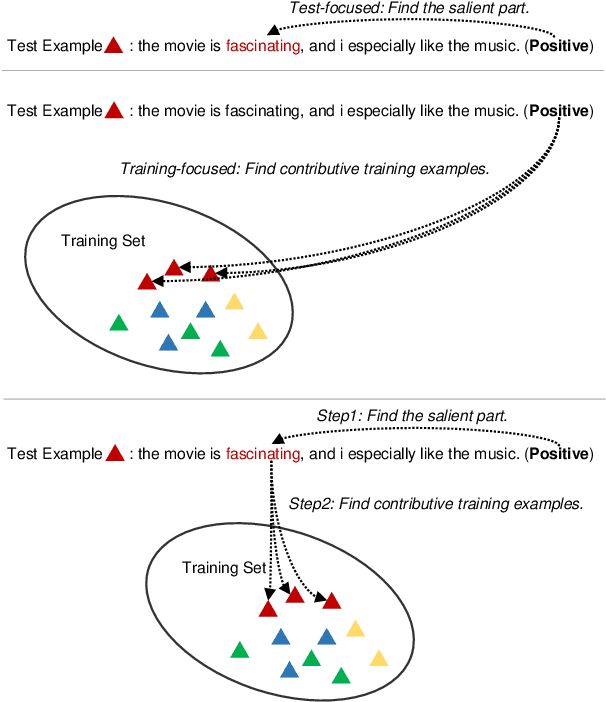
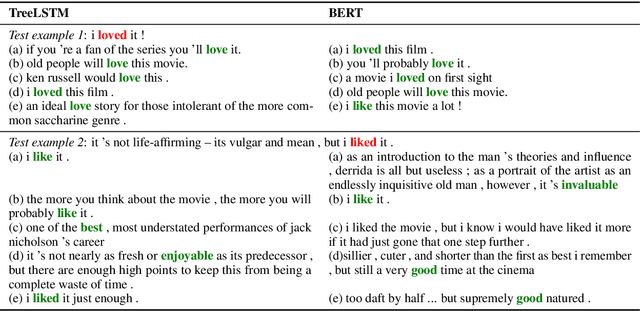

Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.