 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Paper and Code
Oct 31, 2020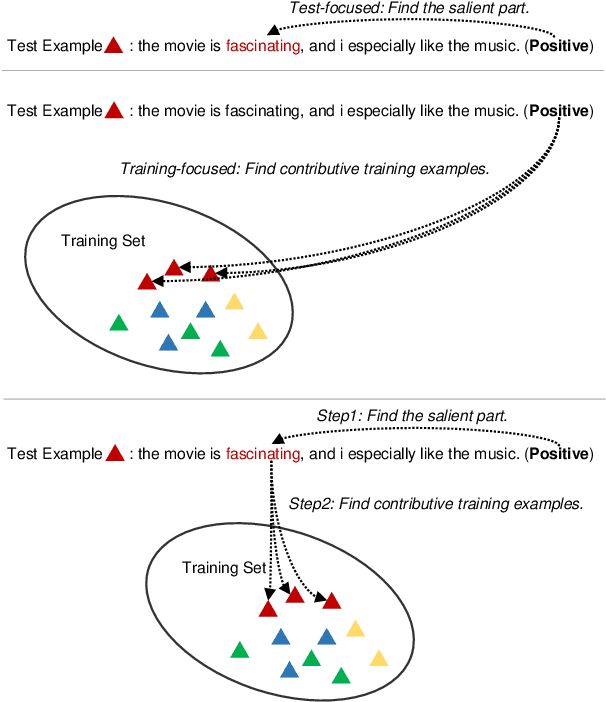
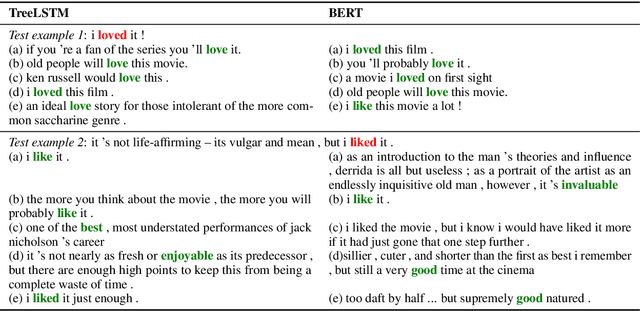

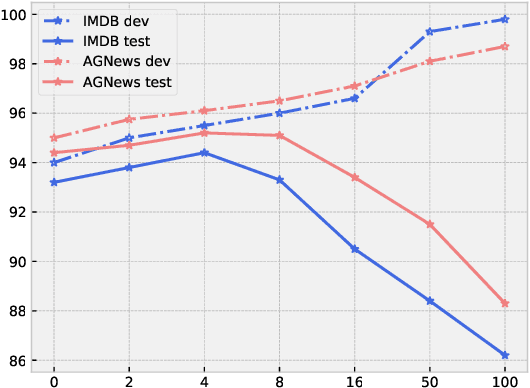
Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.