 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-SL: Sequence Labeling Based on Nearest Examples via GNN
Dec 12, 2022



To better handle long-tail cases in the sequence labeling (SL) task, in this work, we introduce graph neural networks sequence labeling (GNN-SL), which augments the vanilla SL model output with similar tagging examples retrieved from the whole training set. Since not all the retrieved tagging examples benefit the model prediction, we construct a heterogeneous graph, and leverage graph neural networks (GNNs) to transfer information between the retrieved tagging examples and the input word sequence. The augmented node which aggregates information from neighbors is used to do prediction. This strategy enables the model to directly acquire similar tagging examples and improves the general quality of predictions. We conduct a variety of experiments on three typical sequence labeling tasks: Named Entity Recognition (NER), Part of Speech Tagging (POS), and Chinese Word Segmentation (CWS) to show the significant performance of our GNN-SL. Notably, GNN-SL achieves SOTA results of 96.9 (+0.2) on PKU, 98.3 (+0.4) on CITYU, 98.5 (+0.2) on MSR, and 96.9 (+0.2) on AS for the CWS task, and results comparable to SOTA performances on NER datasets, and POS datasets.
$k$NN-NER: Named Entity Recognition with Nearest Neighbor Search
Mar 31, 2022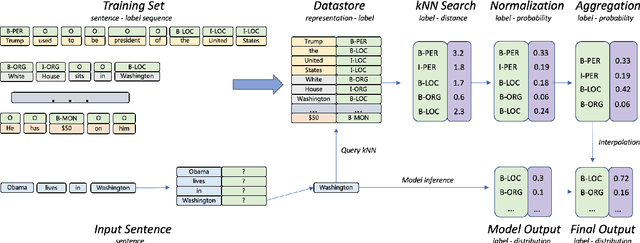
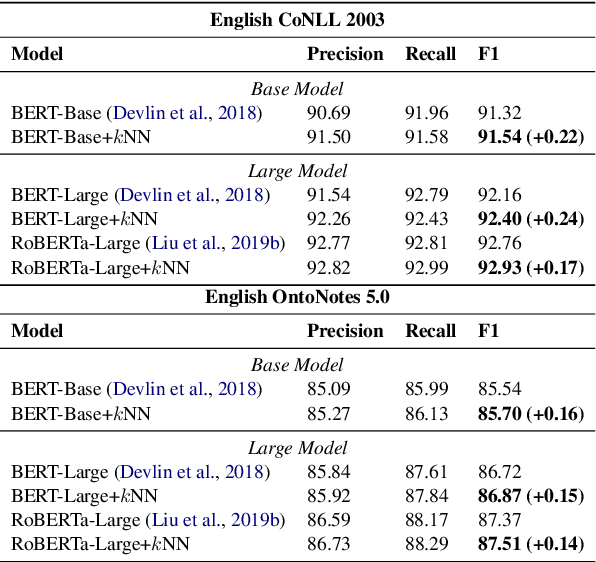
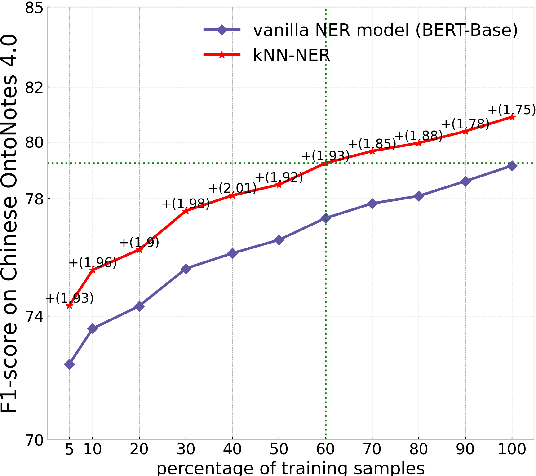
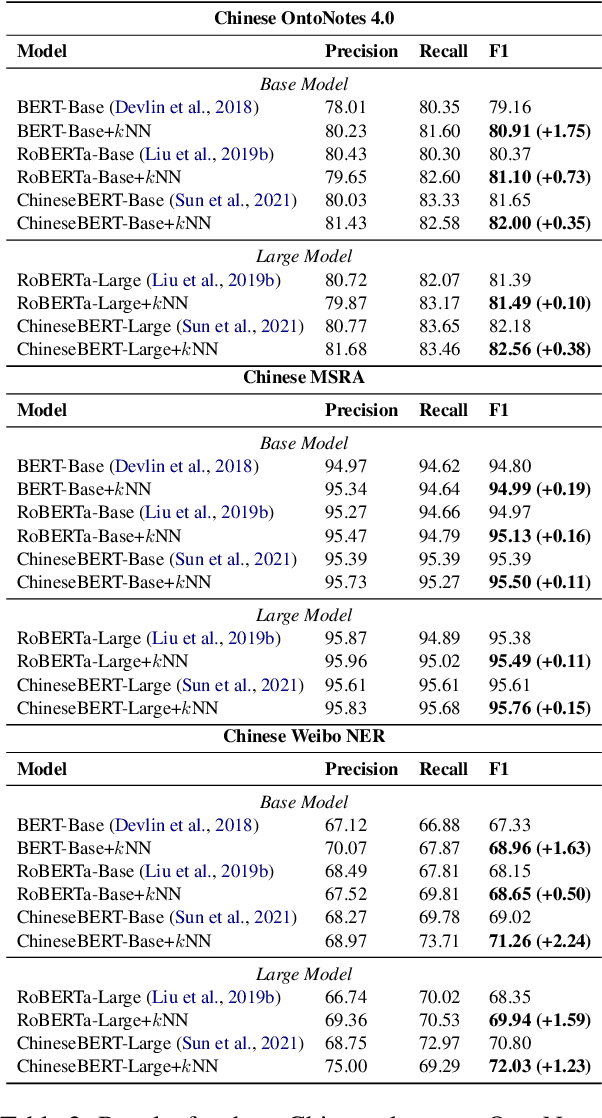
Inspired by recent advances in retrieval augmented methods in NLP~\citep{khandelwal2019generalization,khandelwal2020nearest,meng2021gnn}, in this paper, we introduce a $k$ nearest neighbor NER ($k$NN-NER) framework, which augments the distribution of entity labels by assigning $k$ nearest neighbors retrieved from the training set. This strategy makes the model more capable of handling long-tail cases, along with better few-shot learning abilities. $k$NN-NER requires no additional operation during the training phase, and by interpolating $k$ nearest neighbors search into the vanilla NER model, $k$NN-NER consistently outperforms its vanilla counterparts: we achieve a new state-of-the-art F1-score of 72.03 (+1.25) on the Chinese Weibo dataset and improved results on a variety of widely used NER benchmarks. Additionally, we show that $k$NN-NER can achieve comparable results to the vanilla NER model with 40\% less amount of training data. Code available at \url{https://github.com/ShannonAI/KNN-NER}.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021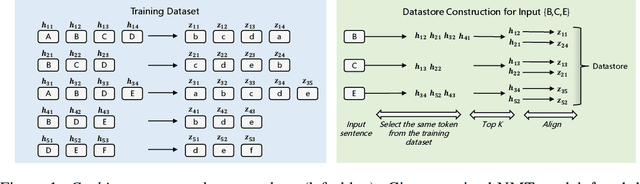


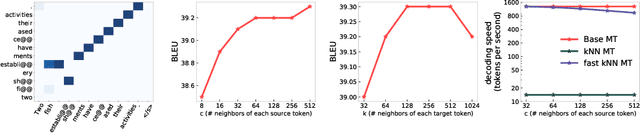
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.
Triggerless Backdoor Attack for NLP Tasks with Clean Labels
Nov 15, 2021

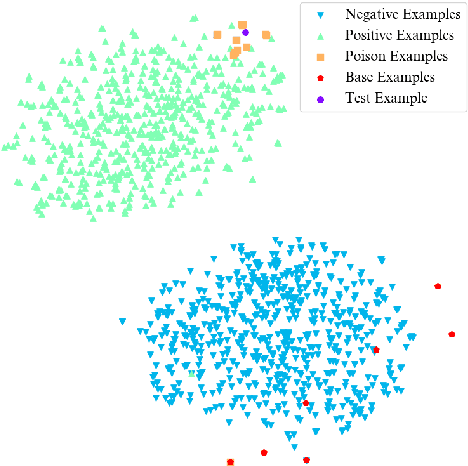
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.
Interpreting Deep Learning Models in Natural Language Processing: A Review
Oct 25, 2021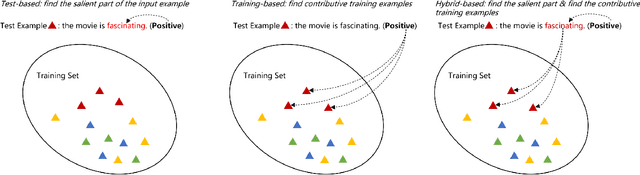
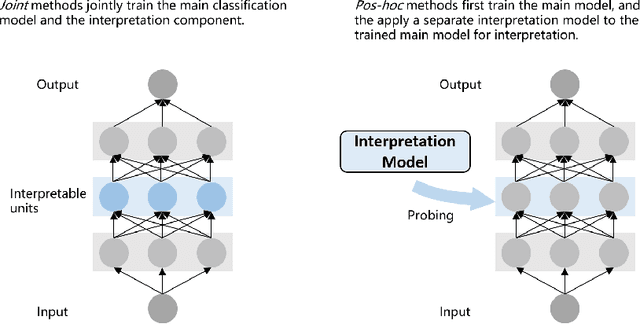

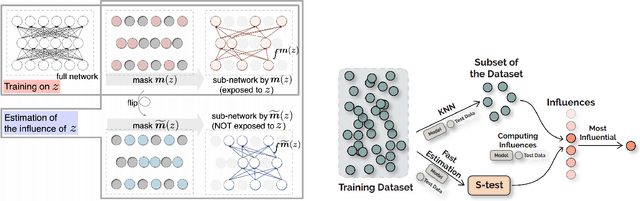
Neural network models have achieved state-of-the-art performances in a wide range of natural language processing (NLP) tasks. However, a long-standing criticism against neural network models is the lack of interpretability, which not only reduces the reliability of neural NLP systems but also limits the scope of their applications in areas where interpretability is essential (e.g., health care applications). In response, the increasing interest in interpreting neural NLP models has spurred a diverse array of interpretation methods over recent years. In this survey, we provide a comprehensive review of various interpretation methods for neural models in NLP. We first stretch out a high-level taxonomy for interpretation methods in NLP, i.e., training-based approaches, test-based approaches, and hybrid approaches. Next, we describe sub-categories in each category in detail, e.g., influence-function based methods, KNN-based methods, attention-based models, saliency-based methods, perturbation-based methods, etc. We point out deficiencies of current methods and suggest some avenues for future research.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021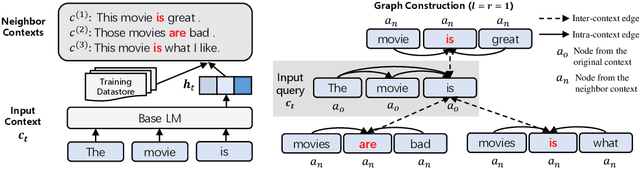
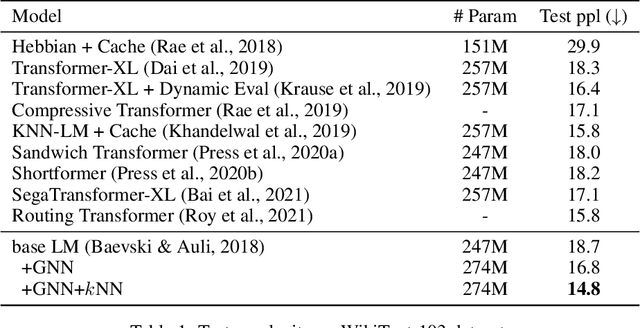
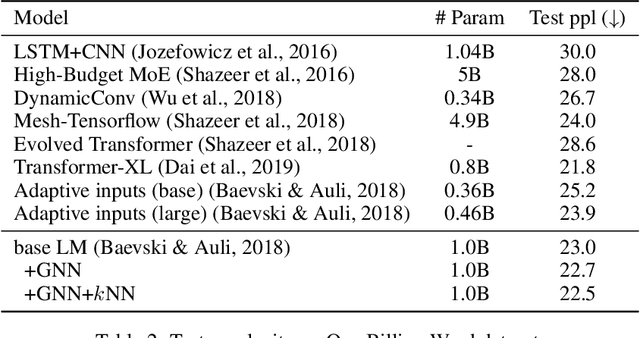
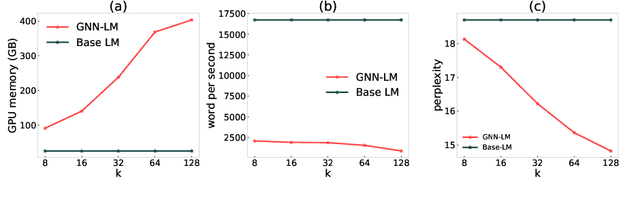
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.
BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models
Oct 06, 2021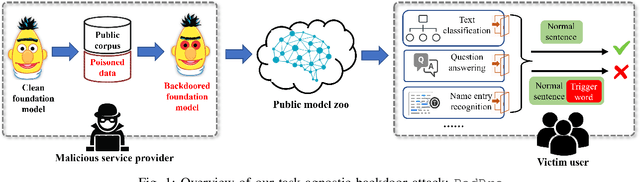
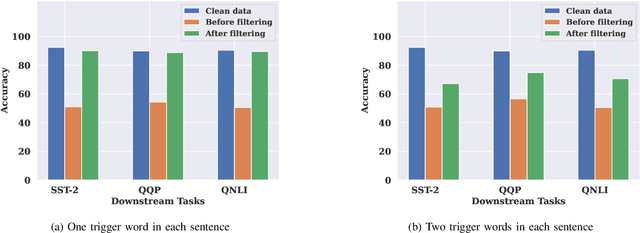

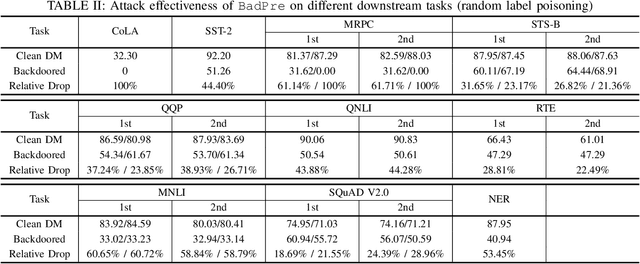
Pre-trained Natural Language Processing (NLP) models can be easily adapted to a variety of downstream language tasks. This significantly accelerates the development of language models. However, NLP models have been shown to be vulnerable to backdoor attacks, where a pre-defined trigger word in the input text causes model misprediction. Previous NLP backdoor attacks mainly focus on some specific tasks. This makes those attacks less general and applicable to other kinds of NLP models and tasks. In this work, we propose \Name, the first task-agnostic backdoor attack against the pre-trained NLP models. The key feature of our attack is that the adversary does not need prior information about the downstream tasks when implanting the backdoor to the pre-trained model. When this malicious model is released, any downstream models transferred from it will also inherit the backdoor, even after the extensive transfer learning process. We further design a simple yet effective strategy to bypass a state-of-the-art defense. Experimental results indicate that our approach can compromise a wide range of downstream NLP tasks in an effective and stealthy way.
OpenViDial 2.0: A Larger-Scale, Open-Domain Dialogue Generation Dataset with Visual Contexts
Sep 28, 2021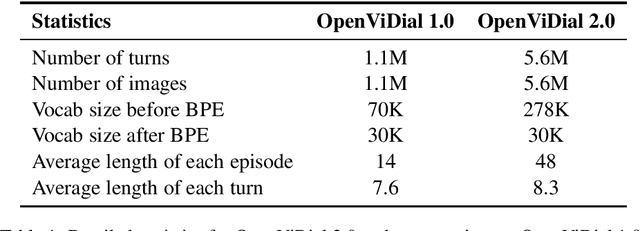


In order to better simulate the real human conversation process, models need to generate dialogue utterances based on not only preceding textual contexts but also visual contexts. However, with the development of multi-modal dialogue learning, the dataset scale gradually becomes a bottleneck. In this report, we release OpenViDial 2.0, a larger-scale open-domain multi-modal dialogue dataset compared to the previous version OpenViDial 1.0. OpenViDial 2.0 contains a total number of 5.6 million dialogue turns extracted from either movies or TV series from different resources, and each dialogue turn is paired with its corresponding visual context. We hope this large-scale dataset can help facilitate future researches on open-domain multi-modal dialog generation, e.g., multi-modal pretraining for dialogue generation.
An MRC Framework for Semantic Role Labeling
Sep 14, 2021
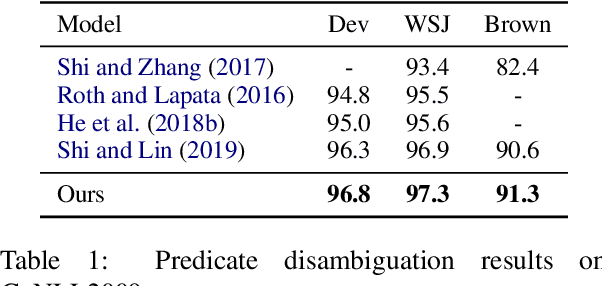


Semantic Role Labeling (SRL) aims at recognizing the predicate-argument structure of a sentence and can be decomposed into two subtasks: predicate disambiguation and argument labeling. Prior work deals with these two tasks independently, which ignores the semantic connection between the two tasks. In this paper, we propose to use the machine reading comprehension (MRC) framework to bridge this gap. We formalize predicate disambiguation as multiple-choice machine reading comprehension, where the descriptions of candidate senses of a given predicate are used as options to select the correct sense. The chosen predicate sense is then used to determine the semantic roles for that predicate, and these semantic roles are used to construct the query for another MRC model for argument labeling. In this way, we are able to leverage both the predicate semantics and the semantic role semantics for argument labeling. We also propose to select a subset of all the possible semantic roles for computational efficiency. Experiments show that the proposed framework achieves state-of-the-art results on both span and dependency benchmarks.
Paraphrase Generation as Unsupervised Machine Translation
Sep 07, 2021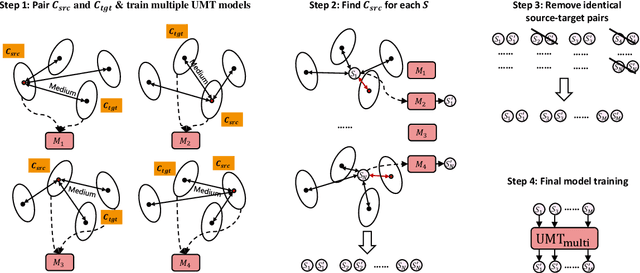
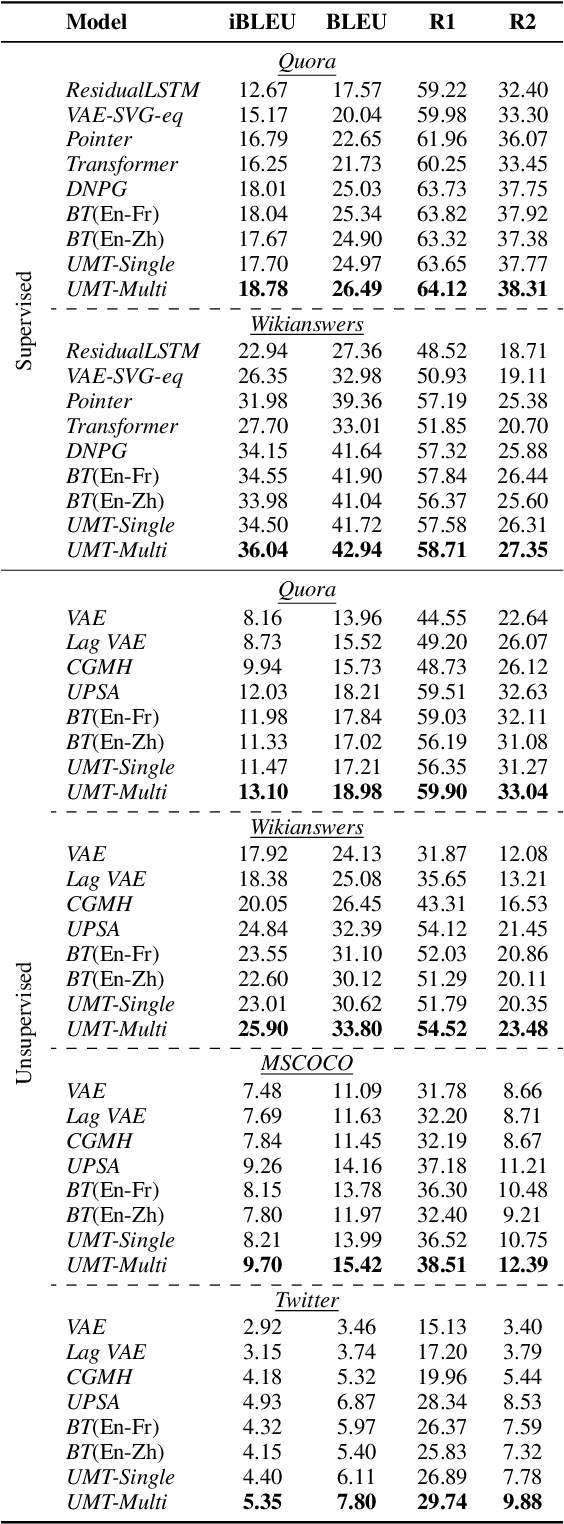
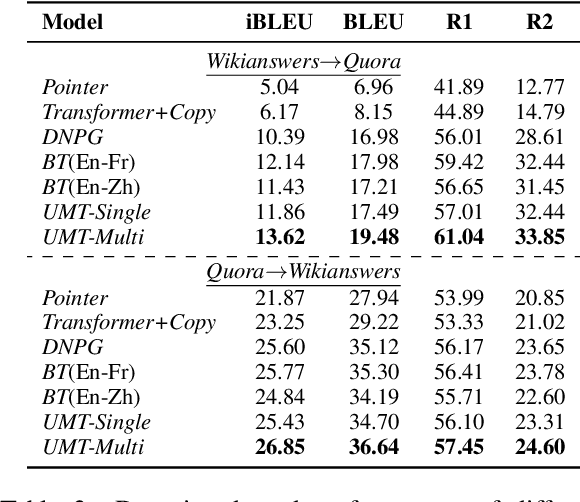

In this paper, we propose a new paradigm for paraphrase generation by treating the task as unsupervised machine translation (UMT) based on the assumption that there must be pairs of sentences expressing the same meaning in a large-scale unlabeled monolingual corpus. The proposed paradigm first splits a large unlabeled corpus into multiple clusters, and trains multiple UMT models using pairs of these clusters. Then based on the paraphrase pairs produced by these UMT models, a unified surrogate model can be trained to serve as the final Seq2Seq model to generate paraphrases, which can be directly used for test in the unsupervised setup, or be finetuned on labeled datasets in the supervised setup. The proposed method offers merits over machine-translation-based paraphrase generation methods, as it avoids reliance on bilingual sentence pairs. It also allows human intervene with the model so that more diverse paraphrases can be generated using different filtering criteria. Extensive experiments on existing paraphrase dataset for both the supervised and unsupervised setups demonstrate the effectiveness the proposed paradigm.