 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenViDial 2.0: A Larger-Scale, Open-Domain Dialogue Generation Dataset with Visual Contexts
Paper and Code
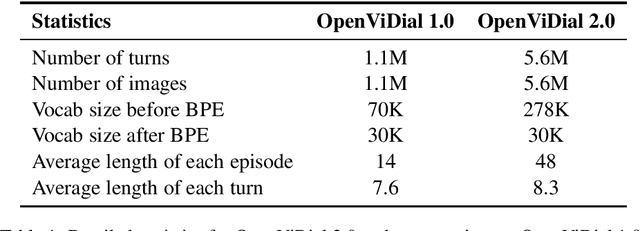


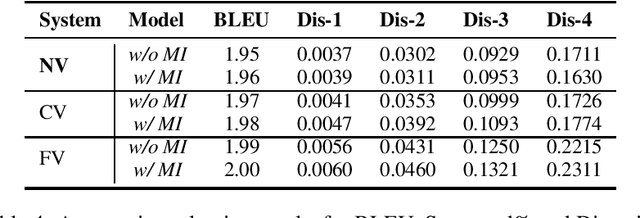
In order to better simulate the real human conversation process, models need to generate dialogue utterances based on not only preceding textual contexts but also visual contexts. However, with the development of multi-modal dialogue learning, the dataset scale gradually becomes a bottleneck. In this report, we release OpenViDial 2.0, a larger-scale open-domain multi-modal dialogue dataset compared to the previous version OpenViDial 1.0. OpenViDial 2.0 contains a total number of 5.6 million dialogue turns extracted from either movies or TV series from different resources, and each dialogue turn is paired with its corresponding visual context. We hope this large-scale dataset can help facilitate future researches on open-domain multi-modal dialog generation, e.g., multi-modal pretraining for dialogue generation.