 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-NER: Named Entity Recognition via Large Language Models
Apr 26, 2023Despite the fact that large-scale Language Models (LLM) have achieved SOTA performances on a variety of NLP tasks, its performance on NER is still significantly below supervised baselines. This is due to the gap between the two tasks the NER and LLMs: the former is a sequence labeling task in nature while the latter is a text-generation model. In this paper, we propose GPT-NER to resolve this issue. GPT-NER bridges the gap by transforming the sequence labeling task to a generation task that can be easily adapted by LLMs e.g., the task of finding location entities in the input text "Columbus is a city" is transformed to generate the text sequence "@@Columbus## is a city", where special tokens @@## marks the entity to extract. To efficiently address the "hallucination" issue of LLMs, where LLMs have a strong inclination to over-confidently label NULL inputs as entities, we propose a self-verification strategy by prompting LLMs to ask itself whether the extracted entities belong to a labeled entity tag. We conduct experiments on five widely adopted NER datasets, and GPT-NER achieves comparable performances to fully supervised baselines, which is the first time as far as we are concerned. More importantly, we find that GPT-NER exhibits a greater ability in the low-resource and few-shot setups, when the amount of training data is extremely scarce, GPT-NER performs significantly better than supervised models. This demonstrates the capabilities of GPT-NER in real-world NER applications where the number of labeled examples is limited.
GNN-SL: Sequence Labeling Based on Nearest Examples via GNN
Dec 12, 2022



To better handle long-tail cases in the sequence labeling (SL) task, in this work, we introduce graph neural networks sequence labeling (GNN-SL), which augments the vanilla SL model output with similar tagging examples retrieved from the whole training set. Since not all the retrieved tagging examples benefit the model prediction, we construct a heterogeneous graph, and leverage graph neural networks (GNNs) to transfer information between the retrieved tagging examples and the input word sequence. The augmented node which aggregates information from neighbors is used to do prediction. This strategy enables the model to directly acquire similar tagging examples and improves the general quality of predictions. We conduct a variety of experiments on three typical sequence labeling tasks: Named Entity Recognition (NER), Part of Speech Tagging (POS), and Chinese Word Segmentation (CWS) to show the significant performance of our GNN-SL. Notably, GNN-SL achieves SOTA results of 96.9 (+0.2) on PKU, 98.3 (+0.4) on CITYU, 98.5 (+0.2) on MSR, and 96.9 (+0.2) on AS for the CWS task, and results comparable to SOTA performances on NER datasets, and POS datasets.
$k$NN-NER: Named Entity Recognition with Nearest Neighbor Search
Mar 31, 2022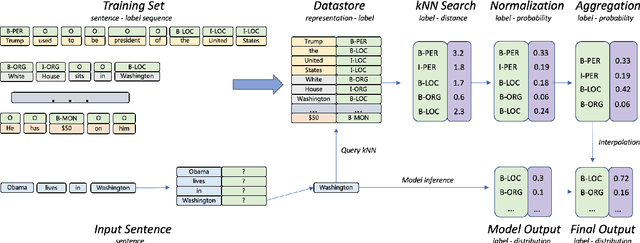
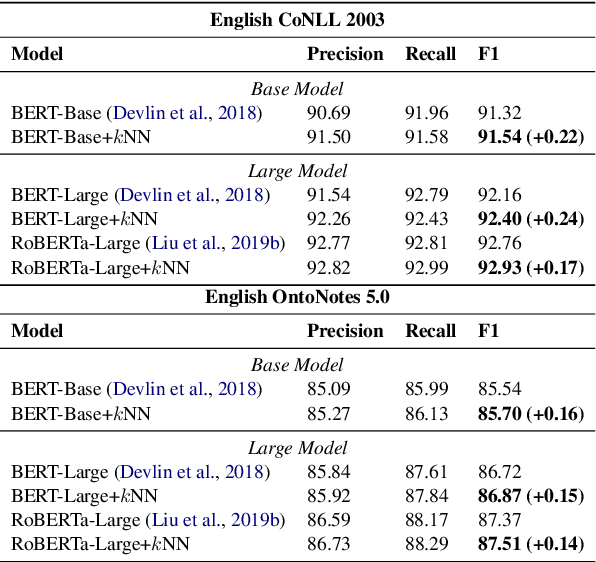
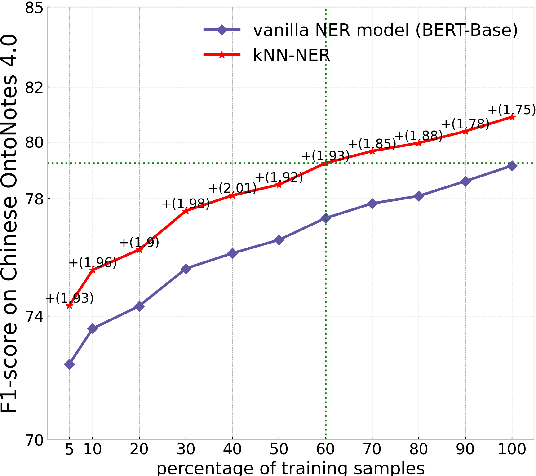
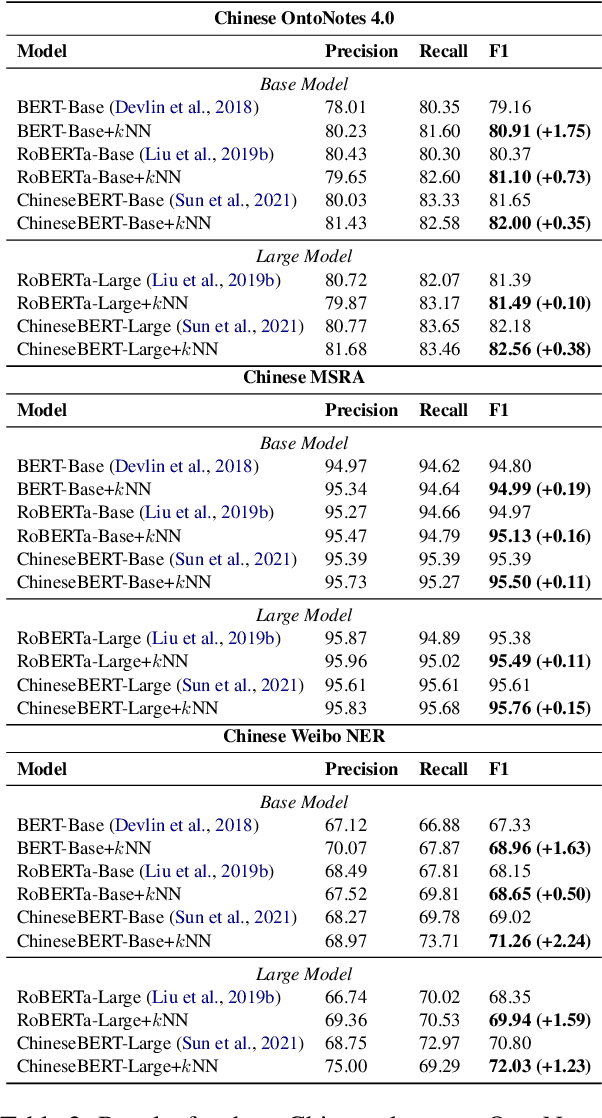
Inspired by recent advances in retrieval augmented methods in NLP~\citep{khandelwal2019generalization,khandelwal2020nearest,meng2021gnn}, in this paper, we introduce a $k$ nearest neighbor NER ($k$NN-NER) framework, which augments the distribution of entity labels by assigning $k$ nearest neighbors retrieved from the training set. This strategy makes the model more capable of handling long-tail cases, along with better few-shot learning abilities. $k$NN-NER requires no additional operation during the training phase, and by interpolating $k$ nearest neighbors search into the vanilla NER model, $k$NN-NER consistently outperforms its vanilla counterparts: we achieve a new state-of-the-art F1-score of 72.03 (+1.25) on the Chinese Weibo dataset and improved results on a variety of widely used NER benchmarks. Additionally, we show that $k$NN-NER can achieve comparable results to the vanilla NER model with 40\% less amount of training data. Code available at \url{https://github.com/ShannonAI/KNN-NER}.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021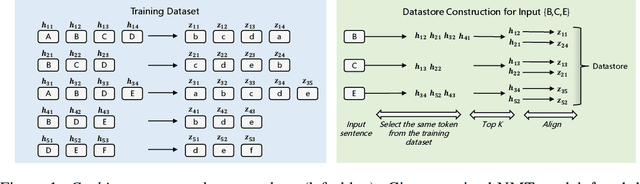


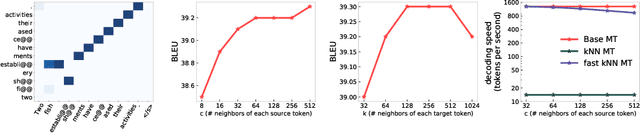
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.
OpenViDial 2.0: A Larger-Scale, Open-Domain Dialogue Generation Dataset with Visual Contexts
Sep 28, 2021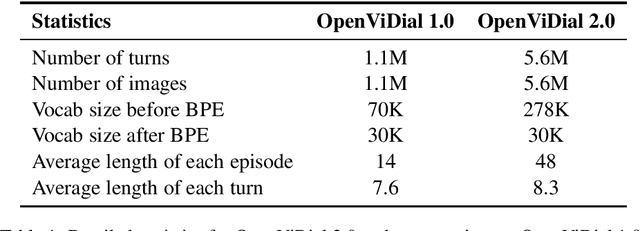


In order to better simulate the real human conversation process, models need to generate dialogue utterances based on not only preceding textual contexts but also visual contexts. However, with the development of multi-modal dialogue learning, the dataset scale gradually becomes a bottleneck. In this report, we release OpenViDial 2.0, a larger-scale open-domain multi-modal dialogue dataset compared to the previous version OpenViDial 1.0. OpenViDial 2.0 contains a total number of 5.6 million dialogue turns extracted from either movies or TV series from different resources, and each dialogue turn is paired with its corresponding visual context. We hope this large-scale dataset can help facilitate future researches on open-domain multi-modal dialog generation, e.g., multi-modal pretraining for dialogue generation.
Modeling Text-visual Mutual Dependency for Multi-modal Dialog Generation
May 30, 2021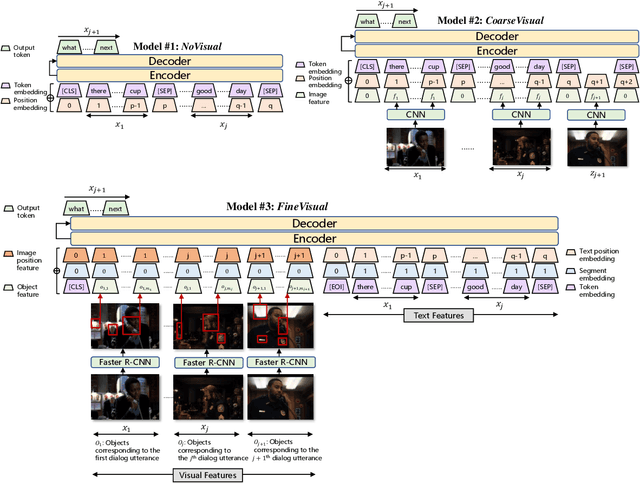
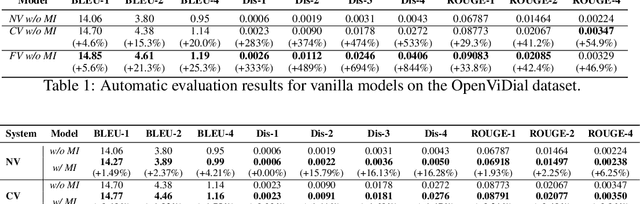
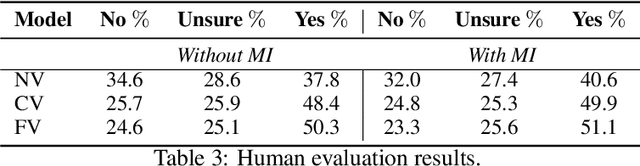

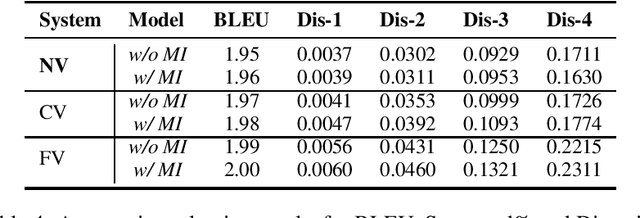
Multi-modal dialog modeling is of growing interest. In this work, we propose frameworks to resolve a specific case of multi-modal dialog generation that better mimics multi-modal dialog generation in the real world, where each dialog turn is associated with the visual context in which it takes place. Specifically, we propose to model the mutual dependency between text-visual features, where the model not only needs to learn the probability of generating the next dialog utterance given preceding dialog utterances and visual contexts, but also the probability of predicting the visual features in which a dialog utterance takes place, leading the generated dialog utterance specific to the visual context. We observe significant performance boosts over vanilla models when the mutual dependency between text and visual features is modeled. Code is available at https://github.com/ShannonAI/OpenViDial.