 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Nearest Neighbor Machine Translation
Paper and Code
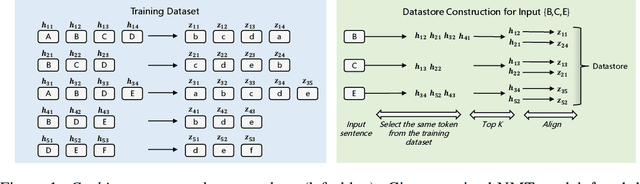


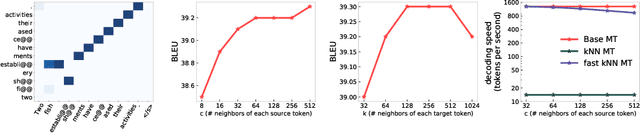
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.