 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Syllogisms Revisited: A Review of the Logical Reasoning Abilities of LLMs for Analyzing Categorical Syllogism
Jun 26, 2024There have been a huge number of benchmarks proposed to evaluate how large language models (LLMs) behave for logic inference tasks. However, it remains an open question how to properly evaluate this ability. In this paper, we provide a systematic overview of prior works on the logical reasoning ability of LLMs for analyzing categorical syllogisms. We first investigate all the possible variations for the categorical syllogisms from a purely logical perspective and then examine the underlying configurations (i.e., mood and figure) tested by the existing datasets. Our results indicate that compared to template-based synthetic datasets, crowdsourcing approaches normally sacrifice the coverage of configurations (i.e., mood and figure) of categorical syllogisms for more language variations, thus bringing challenges to fully testing LLMs under different situations. We then proceed to summarize the findings and observations for the performances of LLMs to infer the validity of syllogisms from the current literature. The error rate breakdown analyses suggest that the interpretation of the quantifiers seems to be the current bottleneck that limits the performances of the LLMs and is thus worth more attention. Finally, we discuss several points that might be worth considering when researchers plan on the future release of categorical syllogism datasets. We hope our work will not only provide a timely review of the current literature regarding categorical syllogisms, but also motivate more interdisciplinary research between communities, specifically computational linguists and logicians.
ADS-Cap: A Framework for Accurate and Diverse Stylized Captioning with Unpaired Stylistic Corpora
Aug 02, 2023Generating visually grounded image captions with specific linguistic styles using unpaired stylistic corpora is a challenging task, especially since we expect stylized captions with a wide variety of stylistic patterns. In this paper, we propose a novel framework to generate Accurate and Diverse Stylized Captions (ADS-Cap). Our ADS-Cap first uses a contrastive learning module to align the image and text features, which unifies paired factual and unpaired stylistic corpora during the training process. A conditional variational auto-encoder is then used to automatically memorize diverse stylistic patterns in latent space and enhance diversity through sampling. We also design a simple but effective recheck module to boost style accuracy by filtering style-specific captions. Experimental results on two widely used stylized image captioning datasets show that regarding consistency with the image, style accuracy and diversity, ADS-Cap achieves outstanding performances compared to various baselines. We finally conduct extensive analyses to understand the effectiveness of our method. Our code is available at https://github.com/njucckevin/ADS-Cap.
$SmartProbe$: A Virtual Moderator for Market Research Surveys
May 14, 2023



Market research surveys are a powerful methodology for understanding consumer perspectives at scale, but are limited by depth of understanding and insights. A virtual moderator can introduce elements of qualitative research into surveys, developing a rapport with survey participants and dynamically asking probing questions, ultimately to elicit more useful information for market researchers. In this work, we introduce ${\tt SmartProbe}$, an API which leverages the adaptive capabilities of large language models (LLMs), and incorporates domain knowledge from market research, in order to generate effective probing questions in any market research survey. We outline the modular processing flow of $\tt SmartProbe$, and evaluate the quality and effectiveness of its generated probing questions. We believe our efforts will inspire industry practitioners to build real-world applications based on the latest advances in LLMs. Our demo is publicly available at https://nexxt.in/smartprobe-demo
Which Model Shall I Choose? Cost/Quality Trade-offs for Text Classification Tasks
Jan 17, 2023



Industry practitioners always face the problem of choosing the appropriate model for deployment under different considerations, such as to maximize a metric that is crucial for production, or to reduce the total cost given financial concerns. In this work, we focus on the text classification task and present a quantitative analysis for this challenge. Using classification accuracy as the main metric, we evaluate the classifiers' performances for a variety of models, including large language models, along with their associated costs, including the annotation cost, training (fine-tuning) cost, and inference cost. We then discuss the model choices for situations like having a large number of samples needed for inference. We hope our work will help people better understand the cost/quality trade-offs for the text classification task.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

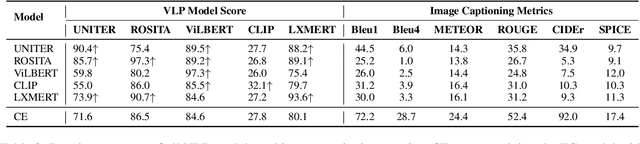
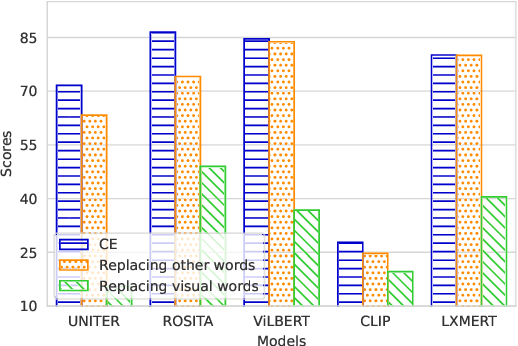
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.
Music-to-Text Synaesthesia: Generating Descriptive Text from Music Recordings
Oct 02, 2022
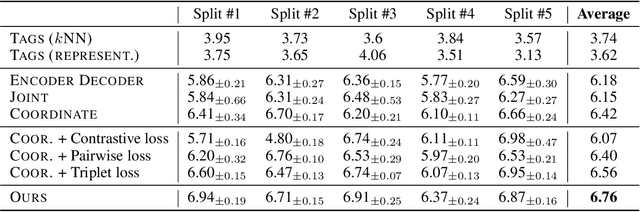
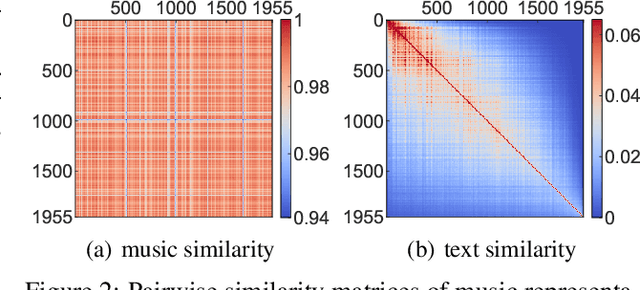

In this paper, we consider a novel research problem, music-to-text synaesthesia. Different from the classical music tagging problem that classifies a music recording into pre-defined categories, the music-to-text synaesthesia aims to generate descriptive texts from music recordings for further understanding. Although this is a new and interesting application to the machine learning community, to our best knowledge, the existing music-related datasets do not contain the semantic descriptions on music recordings and cannot serve the music-to-text synaesthesia task. In light of this, we collect a new dataset that contains 1,955 aligned pairs of classical music recordings and text descriptions. Based on this, we build a computational model to generate sentences that can describe the content of the music recording. To tackle the highly non-discriminative classical music, we design a group topology-preservation loss in our computational model, which considers more samples as a group reference and preserves the relative topology among different samples. Extensive experimental results qualitatively and quantitatively demonstrate the effectiveness of our proposed model over five heuristics or pre-trained competitive methods and their variants on our collected dataset.
Analyzing the Intensity of Complaints on Social Media
Apr 20, 2022
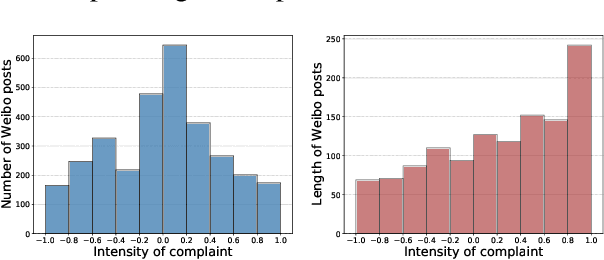

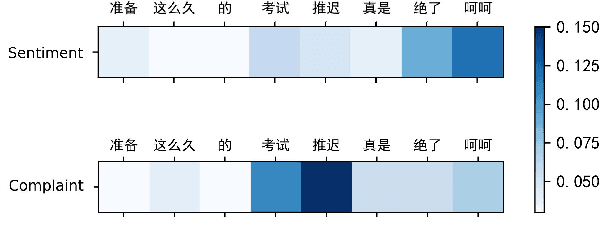
Complaining is a speech act that expresses a negative inconsistency between reality and human expectations. While prior studies mostly focus on identifying the existence or the type of complaints, in this work, we present the first study in computational linguistics of measuring the intensity of complaints from text. Analyzing complaints from such perspective is particularly useful, as complaints of certain degrees may cause severe consequences for companies or organizations. We create the first Chinese dataset containing 3,103 posts about complaints from Weibo, a popular Chinese social media platform. These posts are then annotated with complaints intensity scores using Best-Worst Scaling (BWS) method. We show that complaints intensity can be accurately estimated by computational models with the best mean square error achieving 0.11. Furthermore, we conduct a comprehensive linguistic analysis around complaints, including the connections between complaints and sentiment, and a cross-lingual comparison for complaints expressions used by Chinese and English speakers. We finally show that our complaints intensity scores can be incorporated for better estimating the popularity of posts on social media.
Doctor Recommendation in Online Health Forums via Expertise Learning
Mar 14, 2022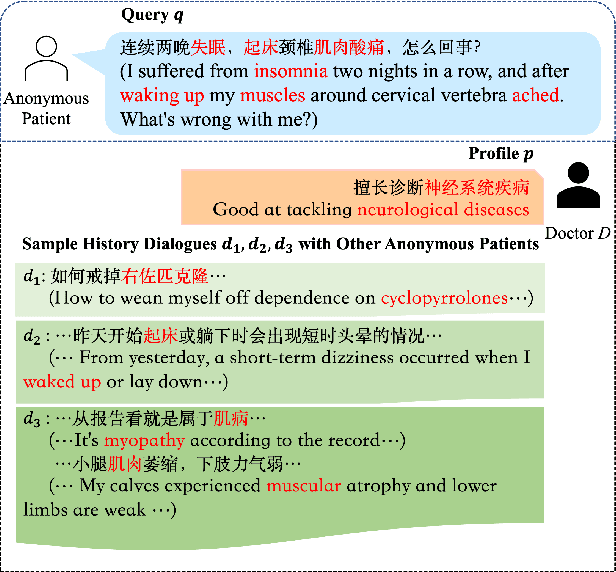
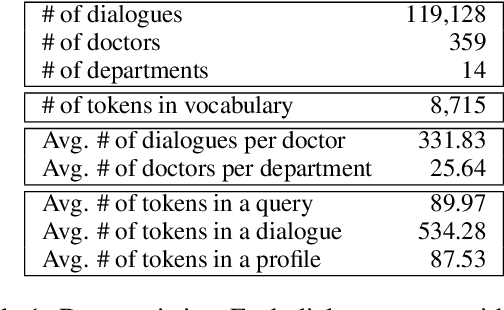
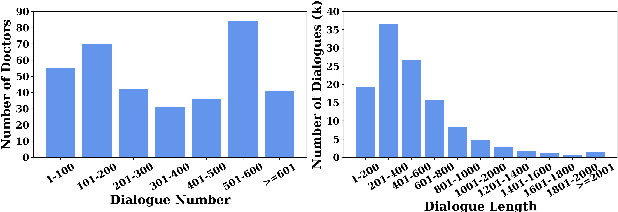
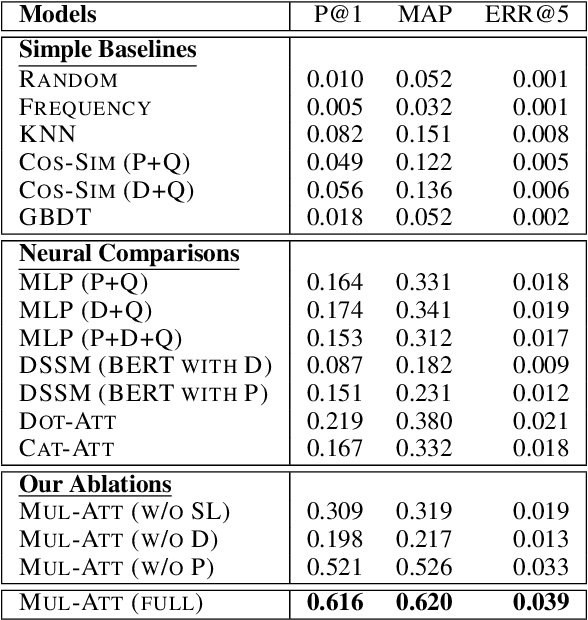
Huge volumes of patient queries are daily generated on online health forums, rendering manual doctor allocation a labor-intensive task. To better help patients, this paper studies a novel task of doctor recommendation to enable automatic pairing of a patient to a doctor with relevant expertise. While most prior work in recommendation focuses on modeling target users from their past behavior, we can only rely on the limited words in a query to infer a patient's needs for privacy reasons. For doctor modeling, we study the joint effects of their profiles and previous dialogues with other patients and explore their interactions via self-learning. The learned doctor embeddings are further employed to estimate their capabilities of handling a patient query with a multi-head attention mechanism. For experiments, a large-scale dataset is collected from Chunyu Yisheng, a Chinese online health forum, where our model exhibits the state-of-the-art results, outperforming baselines only consider profiles and past dialogues to characterize a doctor.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021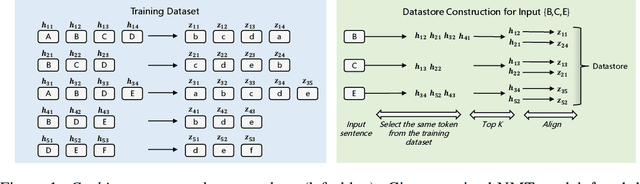


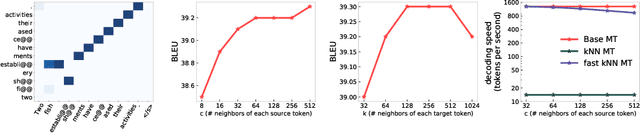
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.
GNN-LM: Language Modeling based on Global Contexts via GNN
Oct 17, 2021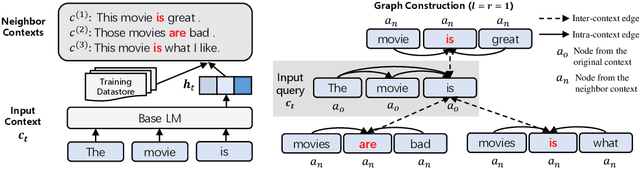
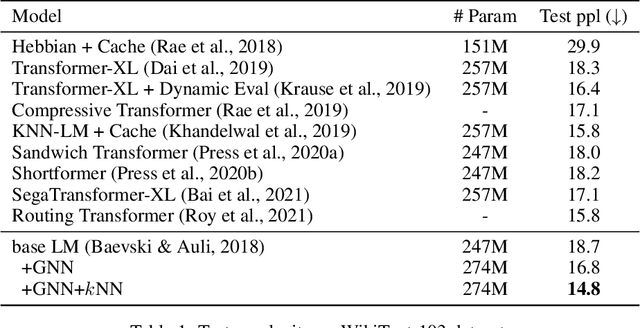
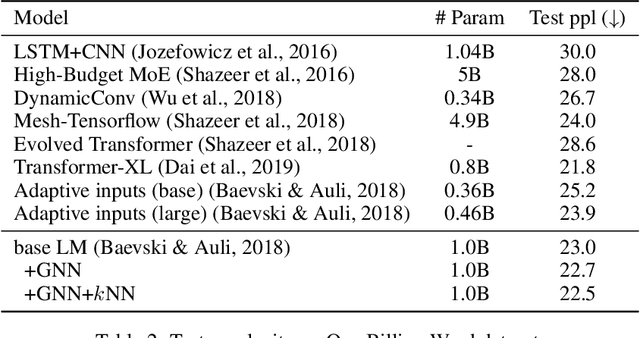
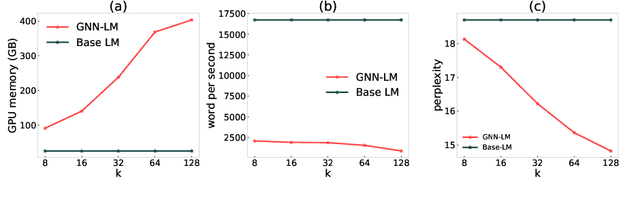
Inspired by the notion that ``{\it to copy is easier than to memorize}``, in this work, we introduce GNN-LM, which extends the vanilla neural language model (LM) by allowing to reference similar contexts in the entire training corpus. We build a directed heterogeneous graph between an input context and its semantically related neighbors selected from the training corpus, where nodes are tokens in the input context and retrieved neighbor contexts, and edges represent connections between nodes. Graph neural networks (GNNs) are constructed upon the graph to aggregate information from similar contexts to decode the token. This learning paradigm provides direct access to the reference contexts and helps improve a model's generalization ability. We conduct comprehensive experiments to validate the effectiveness of the GNN-LM: GNN-LM achieves a new state-of-the-art perplexity of 14.8 on WikiText-103 (a 4.5 point improvement over its counterpart of the vanilla LM model) and shows substantial improvement on One Billion Word and Enwiki8 datasets against strong baselines. In-depth ablation studies are performed to understand the mechanics of GNN-LM.