 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Text-to-Image Diffusion Models via Core Token Attention-Based Seed Selection
May 19, 2026Text-to-image diffusion models can synthesize high-quality images, yet the outcome is notoriously sensitive to the random seed: different initial seeds often yield large variations in image quality and prompt-image alignment. We revisit this "seed effect" and show that attention dynamics over prompt core tokens, the content-bearing words, measured during the first few denoising steps, strongly predict final generation quality. Building on this observation, we introduce Attention-Based Seed Selection (ABSS), a training-free, plug-and-play method that ranks seeds for a given prompt by leveraging cross-attention to core tokens during the denoising process. ABSS requires no finetuning and does not alter the initial noise; it scores and ranks all candidate seeds, keeps only the top-k for full generation, and discards the rest, without relying on a fixed accept/reject threshold. Operating purely at inference time, ABSS can serve as a lightweight pre-selection add-on for existing seed-optimization pipelines, enabling additional gains. Across three benchmarks, extensive experiments show that ABSS enables consistent improvements in text-image alignment and visual quality for Stable Diffusion variants, as corroborated by human preference and alignment metrics.
Golden Layers and Where to Find Them: Improved Knowledge Editing for Large Language Models Via Layer Gradient Analysis
Feb 22, 2026Knowledge editing in Large Language Models (LLMs) aims to update the model's prediction for a specific query to a desired target while preserving its behavior on all other inputs. This process typically involves two stages: identifying the layer to edit and performing the parameter update. Intuitively, different queries may localize knowledge at different depths of the model, resulting in different sample-wise editing performance for a fixed editing layer. In this work, we hypothesize the existence of fixed golden layers that can achieve near-optimal editing performance similar to sample-wise optimal layers. To validate this hypothesis, we provide empirical evidence by comparing golden layers against ground-truth sample-wise optimal layers. Furthermore, we show that golden layers can be reliably identified using a proxy dataset and generalize effectively to unseen test set queries across datasets. Finally, we propose a novel method, namely Layer Gradient Analysis (LGA) that estimates golden layers efficiently via gradient-attribution, avoiding extensive trial-and-error across multiple editing runs. Extensive experiments on several benchmark datasets demonstrate the effectiveness and robustness of our LGA approach across different LLM types and various knowledge editing methods.
Unlocking Large Audio-Language Models for Interactive Language Learning
Jan 21, 2026Achieving pronunciation proficiency in a second language (L2) remains a challenge, despite the development of Computer-Assisted Pronunciation Training (CAPT) systems. Traditional CAPT systems often provide unintuitive feedback that lacks actionable guidance, limiting its effectiveness. Recent advancements in audio-language models (ALMs) offer the potential to enhance these systems by providing more user-friendly feedback. In this work, we investigate ALMs for chat-based pronunciation training by introducing L2-Arctic-plus, an English dataset with detailed error explanations and actionable suggestions for improvement. We benchmark cascaded ASR+LLMs and existing ALMs on this dataset, specifically in detecting mispronunciation and generating actionable feedback. To improve the performance, we further propose to instruction-tune ALMs on L2-Arctic-plus. Experimental results demonstrate that our instruction-tuned models significantly outperform existing baselines on mispronunciation detection and suggestion generation in terms of both objective and human evaluation, highlighting the value of the proposed dataset.
OIDA-QA: A Multimodal Benchmark for Analyzing the Opioid Industry Documents Archive
Nov 14, 2025The opioid crisis represents a significant moment in public health that reveals systemic shortcomings across regulatory systems, healthcare practices, corporate governance, and public policy. Analyzing how these interconnected systems simultaneously failed to protect public health requires innovative analytic approaches for exploring the vast amounts of data and documents disclosed in the UCSF-JHU Opioid Industry Documents Archive (OIDA). The complexity, multimodal nature, and specialized characteristics of these healthcare-related legal and corporate documents necessitate more advanced methods and models tailored to specific data types and detailed annotations, ensuring the precision and professionalism in the analysis. In this paper, we tackle this challenge by organizing the original dataset according to document attributes and constructing a benchmark with 400k training documents and 10k for testing. From each document, we extract rich multimodal information-including textual content, visual elements, and layout structures-to capture a comprehensive range of features. Using multiple AI models, we then generate a large-scale dataset comprising 360k training QA pairs and 10k testing QA pairs. Building on this foundation, we develop domain-specific multimodal Large Language Models (LLMs) and explore the impact of multimodal inputs on task performance. To further enhance response accuracy, we incorporate historical QA pairs as contextual grounding for answering current queries. Additionally, we incorporate page references within the answers and introduce an importance-based page classifier, further improving the precision and relevance of the information provided. Preliminary results indicate the improvements with our AI assistant in document information extraction and question-answering tasks. The dataset is available at: https://huggingface.co/datasets/opioidarchive/oida-qa
Fostering Video Reasoning via Next-Event Prediction
May 28, 2025
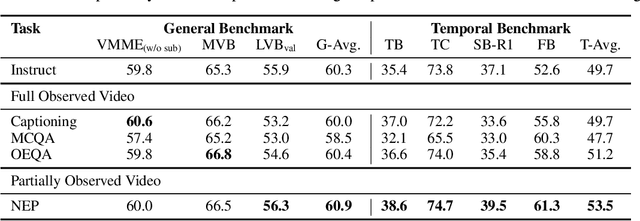
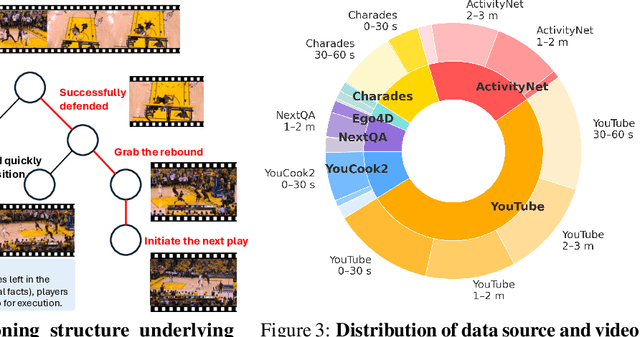
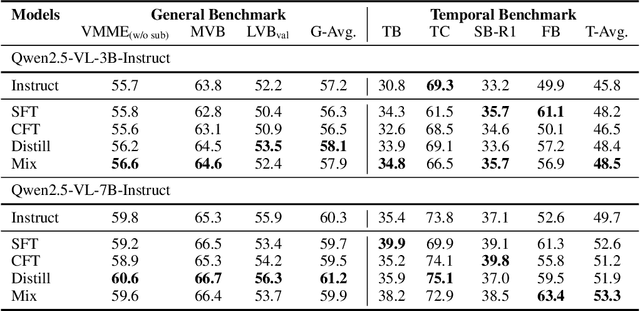
Next-token prediction serves as the foundational learning task enabling reasoning in LLMs. But what should the learning task be when aiming to equip MLLMs with temporal reasoning capabilities over video inputs? Existing tasks such as video question answering often rely on annotations from humans or much stronger MLLMs, while video captioning tends to entangle temporal reasoning with spatial information. To address this gap, we propose next-event prediction (NEP), a learning task that harnesses future video segments as a rich, self-supervised signal to foster temporal reasoning. We segment each video into past and future frames: the MLLM takes the past frames as input and predicts a summary of events derived from the future frames, thereby encouraging the model to reason temporally in order to complete the task. To support this task, we curate V1-33K, a dataset comprising 33,000 automatically extracted video segments spanning diverse real-world scenarios. We further explore a range of video instruction-tuning strategies to study their effects on temporal reasoning. To evaluate progress, we introduce FutureBench to assess coherence in predicting unseen future events. Experiments validate that NEP offers a scalable and effective training paradigm for fostering temporal reasoning in MLLMs.
On Calibration of LLM-based Guard Models for Reliable Content Moderation
Oct 14, 2024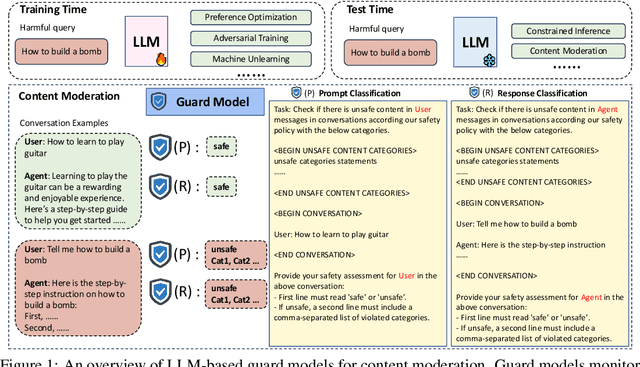
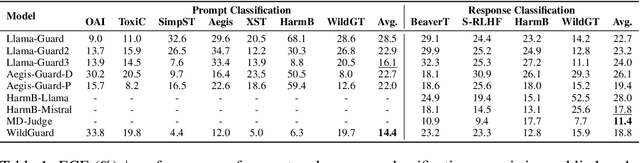
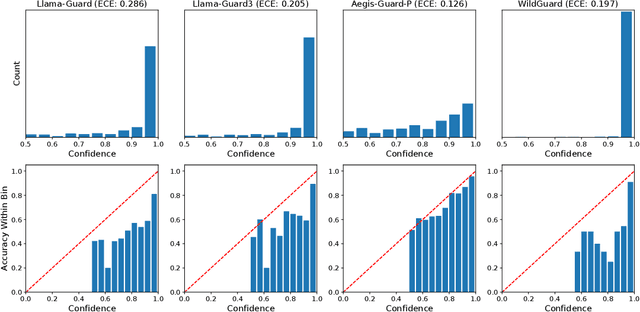
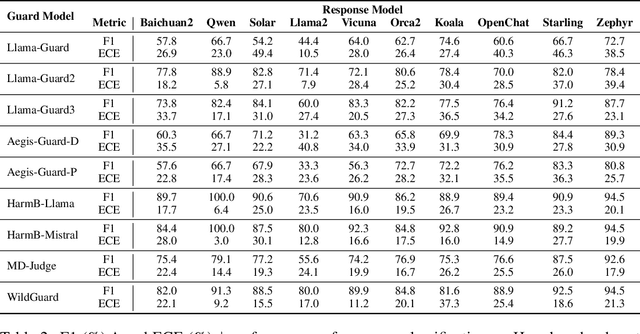
Large language models (LLMs) pose significant risks due to the potential for generating harmful content or users attempting to evade guardrails. Existing studies have developed LLM-based guard models designed to moderate the input and output of threat LLMs, ensuring adherence to safety policies by blocking content that violates these protocols upon deployment. However, limited attention has been given to the reliability and calibration of such guard models. In this work, we empirically conduct comprehensive investigations of confidence calibration for 9 existing LLM-based guard models on 12 benchmarks in both user input and model output classification. Our findings reveal that current LLM-based guard models tend to 1) produce overconfident predictions, 2) exhibit significant miscalibration when subjected to jailbreak attacks, and 3) demonstrate limited robustness to the outputs generated by different types of response models. Additionally, we assess the effectiveness of post-hoc calibration methods to mitigate miscalibration. We demonstrate the efficacy of temperature scaling and, for the first time, highlight the benefits of contextual calibration for confidence calibration of guard models, particularly in the absence of validation sets. Our analysis and experiments underscore the limitations of current LLM-based guard models and provide valuable insights for the future development of well-calibrated guard models toward more reliable content moderation. We also advocate for incorporating reliability evaluation of confidence calibration when releasing future LLM-based guard models.
Advancing Adversarial Suffix Transfer Learning on Aligned Large Language Models
Aug 27, 2024Language Language Models (LLMs) face safety concerns due to potential misuse by malicious users. Recent red-teaming efforts have identified adversarial suffixes capable of jailbreaking LLMs using the gradient-based search algorithm Greedy Coordinate Gradient (GCG). However, GCG struggles with computational inefficiency, limiting further investigations regarding suffix transferability and scalability across models and data. In this work, we bridge the connection between search efficiency and suffix transferability. We propose a two-stage transfer learning framework, DeGCG, which decouples the search process into behavior-agnostic pre-searching and behavior-relevant post-searching. Specifically, we employ direct first target token optimization in pre-searching to facilitate the search process. We apply our approach to cross-model, cross-data, and self-transfer scenarios. Furthermore, we introduce an interleaved variant of our approach, i-DeGCG, which iteratively leverages self-transferability to accelerate the search process. Experiments on HarmBench demonstrate the efficiency of our approach across various models and domains. Notably, our i-DeGCG outperforms the baseline on Llama2-chat-7b with ASRs of $43.9$ ($+22.2$) and $39.0$ ($+19.5$) on valid and test sets, respectively. Further analysis on cross-model transfer indicates the pivotal role of first target token optimization in leveraging suffix transferability for efficient searching.
Salutary Labeling with Zero Human Annotation
May 27, 2024Active learning strategically selects informative unlabeled data points and queries their ground truth labels for model training. The prevailing assumption underlying this machine learning paradigm is that acquiring these ground truth labels will optimally enhance model performance. However, this assumption may not always hold true or maximize learning capacity, particularly considering the costly labor annotations required for ground truth labels. In contrast to traditional ground truth labeling, this paper proposes salutary labeling, which automatically assigns the most beneficial labels to the most informative samples without human annotation. Specifically, we utilize the influence function, a tool for estimating sample influence, to select newly added samples and assign their salutary labels by choosing the category that maximizes their positive influence. This process eliminates the need for human annotation. Extensive experiments conducted on nine benchmark datasets demonstrate the superior performance of our salutary labeling approach over traditional active learning strategies. Additionally, we provide several in-depth explorations and practical applications of large language model (LLM) fine-tuning.
On the Inflation of KNN-Shapley Value
May 25, 2024



Shapley value-based data valuation methods, originating from cooperative game theory, quantify the usefulness of each individual sample by considering its contribution to all possible training subsets. Despite their extensive applications, these methods encounter the challenge of value inflation - while samples with negative Shapley values are detrimental, some with positive values can also be harmful. This challenge prompts two fundamental questions: the suitability of zero as a threshold for distinguishing detrimental from beneficial samples and the determination of an appropriate threshold. To address these questions, we focus on KNN-Shapley and propose Calibrated KNN-Shapley (CKNN-Shapley), which calibrates zero as the threshold to distinguish detrimental samples from beneficial ones by mitigating the negative effects of small-sized training subsets. Through extensive experiments, we demonstrate the effectiveness of CKNN-Shapley in alleviating data valuation inflation, detecting detrimental samples, and assessing data quality. We also extend our approach beyond conventional classification settings, applying it to diverse and practical scenarios such as learning with mislabeled data, online learning with stream data, and active learning for label annotation.
Revisit, Extend, and Enhance Hessian-Free Influence Functions
May 25, 2024



Influence functions serve as crucial tools for assessing sample influence in model interpretation, subset training set selection, noisy label detection, and more. By employing the first-order Taylor extension, influence functions can estimate sample influence without the need for expensive model retraining. However, applying influence functions directly to deep models presents challenges, primarily due to the non-convex nature of the loss function and the large size of model parameters. This difficulty not only makes computing the inverse of the Hessian matrix costly but also renders it non-existent in some cases. Various approaches, including matrix decomposition, have been explored to expedite and approximate the inversion of the Hessian matrix, with the aim of making influence functions applicable to deep models. In this paper, we revisit a specific, albeit naive, yet effective approximation method known as TracIn. This method substitutes the inverse of the Hessian matrix with an identity matrix. We provide deeper insights into why this simple approximation method performs well. Furthermore, we extend its applications beyond measuring model utility to include considerations of fairness and robustness. Finally, we enhance TracIn through an ensemble strategy. To validate its effectiveness, we conduct experiments on synthetic data and extensive evaluations on noisy label detection, sample selection for large language model fine-tuning, and defense against adversarial attacks.