 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit, Extend, and Enhance Hessian-Free Influence Functions
May 25, 2024



Influence functions serve as crucial tools for assessing sample influence in model interpretation, subset training set selection, noisy label detection, and more. By employing the first-order Taylor extension, influence functions can estimate sample influence without the need for expensive model retraining. However, applying influence functions directly to deep models presents challenges, primarily due to the non-convex nature of the loss function and the large size of model parameters. This difficulty not only makes computing the inverse of the Hessian matrix costly but also renders it non-existent in some cases. Various approaches, including matrix decomposition, have been explored to expedite and approximate the inversion of the Hessian matrix, with the aim of making influence functions applicable to deep models. In this paper, we revisit a specific, albeit naive, yet effective approximation method known as TracIn. This method substitutes the inverse of the Hessian matrix with an identity matrix. We provide deeper insights into why this simple approximation method performs well. Furthermore, we extend its applications beyond measuring model utility to include considerations of fairness and robustness. Finally, we enhance TracIn through an ensemble strategy. To validate its effectiveness, we conduct experiments on synthetic data and extensive evaluations on noisy label detection, sample selection for large language model fine-tuning, and defense against adversarial attacks.
On the Inflation of KNN-Shapley Value
May 25, 2024



Shapley value-based data valuation methods, originating from cooperative game theory, quantify the usefulness of each individual sample by considering its contribution to all possible training subsets. Despite their extensive applications, these methods encounter the challenge of value inflation - while samples with negative Shapley values are detrimental, some with positive values can also be harmful. This challenge prompts two fundamental questions: the suitability of zero as a threshold for distinguishing detrimental from beneficial samples and the determination of an appropriate threshold. To address these questions, we focus on KNN-Shapley and propose Calibrated KNN-Shapley (CKNN-Shapley), which calibrates zero as the threshold to distinguish detrimental samples from beneficial ones by mitigating the negative effects of small-sized training subsets. Through extensive experiments, we demonstrate the effectiveness of CKNN-Shapley in alleviating data valuation inflation, detecting detrimental samples, and assessing data quality. We also extend our approach beyond conventional classification settings, applying it to diverse and practical scenarios such as learning with mislabeled data, online learning with stream data, and active learning for label annotation.
TCTN: A 3D-Temporal Convolutional Transformer Network for Spatiotemporal Predictive Learning
Dec 02, 2021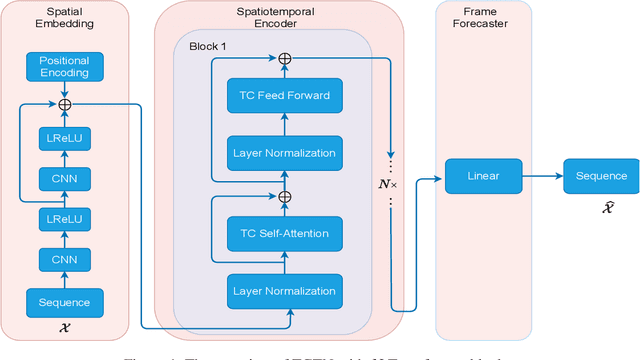
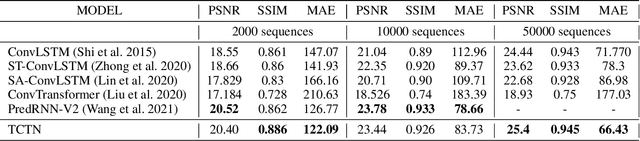
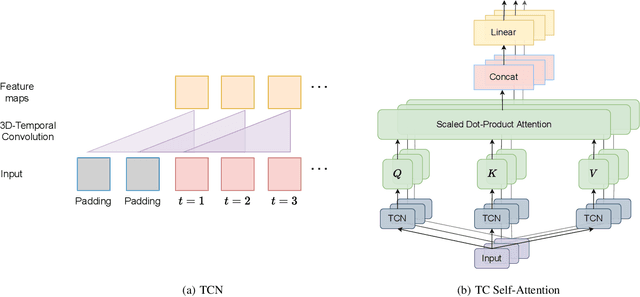
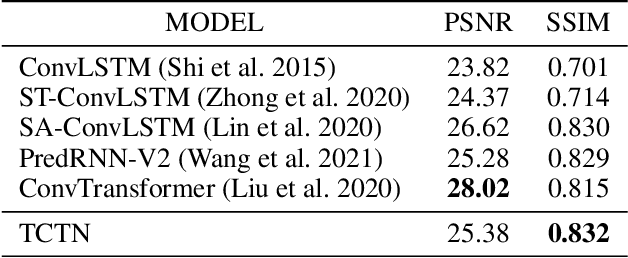
Spatiotemporal predictive learning is to generate future frames given a sequence of historical frames. Conventional algorithms are mostly based on recurrent neural networks (RNNs). However, RNN suffers from heavy computational burden such as time and long back-propagation process due to the seriality of recurrent structure. Recently, Transformer-based methods have also been investigated in the form of encoder-decoder or plain encoder, but the encoder-decoder form requires too deep networks and the plain encoder is lack of short-term dependencies. To tackle these problems, we propose an algorithm named 3D-temporal convolutional transformer (TCTN), where a transformer-based encoder with temporal convolutional layers is employed to capture short-term and long-term dependencies. Our proposed algorithm can be easy to implement and trained much faster compared with RNN-based methods thanks to the parallel mechanism of Transformer. To validate our algorithm, we conduct experiments on the MovingMNIST and KTH dataset, and show that TCTN outperforms state-of-the-art (SOTA) methods in both performance and training speed.