 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCTN: A 3D-Temporal Convolutional Transformer Network for Spatiotemporal Predictive Learning
Paper and Code
Dec 02, 2021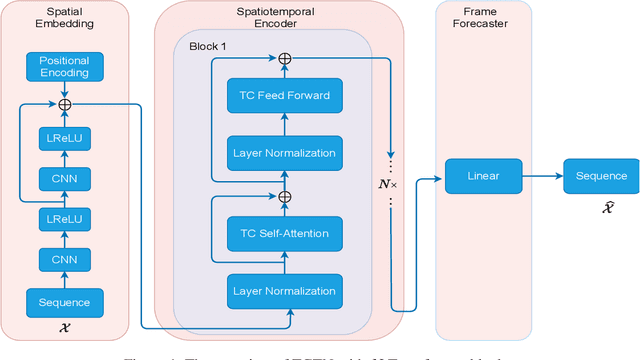
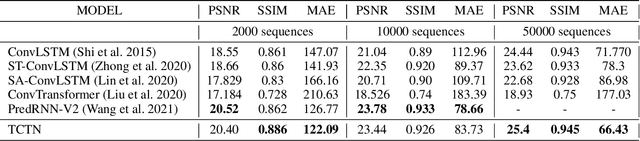
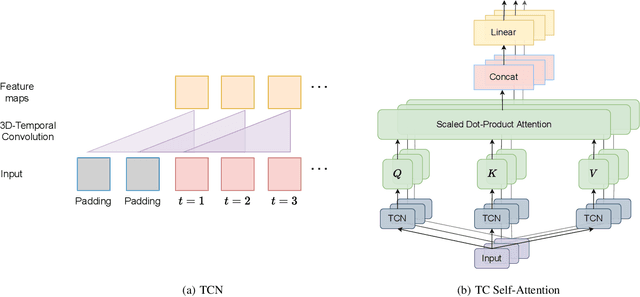
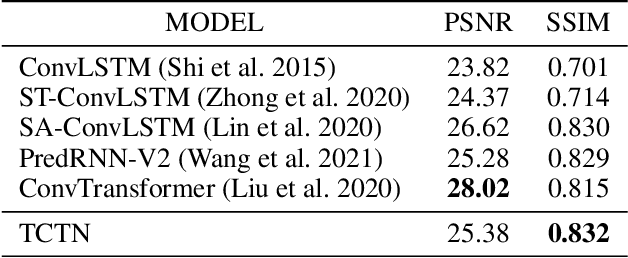
Spatiotemporal predictive learning is to generate future frames given a sequence of historical frames. Conventional algorithms are mostly based on recurrent neural networks (RNNs). However, RNN suffers from heavy computational burden such as time and long back-propagation process due to the seriality of recurrent structure. Recently, Transformer-based methods have also been investigated in the form of encoder-decoder or plain encoder, but the encoder-decoder form requires too deep networks and the plain encoder is lack of short-term dependencies. To tackle these problems, we propose an algorithm named 3D-temporal convolutional transformer (TCTN), where a transformer-based encoder with temporal convolutional layers is employed to capture short-term and long-term dependencies. Our proposed algorithm can be easy to implement and trained much faster compared with RNN-based methods thanks to the parallel mechanism of Transformer. To validate our algorithm, we conduct experiments on the MovingMNIST and KTH dataset, and show that TCTN outperforms state-of-the-art (SOTA) methods in both performance and training speed.