 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisit, Extend, and Enhance Hessian-Free Influence Functions
May 25, 2024



Influence functions serve as crucial tools for assessing sample influence in model interpretation, subset training set selection, noisy label detection, and more. By employing the first-order Taylor extension, influence functions can estimate sample influence without the need for expensive model retraining. However, applying influence functions directly to deep models presents challenges, primarily due to the non-convex nature of the loss function and the large size of model parameters. This difficulty not only makes computing the inverse of the Hessian matrix costly but also renders it non-existent in some cases. Various approaches, including matrix decomposition, have been explored to expedite and approximate the inversion of the Hessian matrix, with the aim of making influence functions applicable to deep models. In this paper, we revisit a specific, albeit naive, yet effective approximation method known as TracIn. This method substitutes the inverse of the Hessian matrix with an identity matrix. We provide deeper insights into why this simple approximation method performs well. Furthermore, we extend its applications beyond measuring model utility to include considerations of fairness and robustness. Finally, we enhance TracIn through an ensemble strategy. To validate its effectiveness, we conduct experiments on synthetic data and extensive evaluations on noisy label detection, sample selection for large language model fine-tuning, and defense against adversarial attacks.
On the Inflation of KNN-Shapley Value
May 25, 2024



Shapley value-based data valuation methods, originating from cooperative game theory, quantify the usefulness of each individual sample by considering its contribution to all possible training subsets. Despite their extensive applications, these methods encounter the challenge of value inflation - while samples with negative Shapley values are detrimental, some with positive values can also be harmful. This challenge prompts two fundamental questions: the suitability of zero as a threshold for distinguishing detrimental from beneficial samples and the determination of an appropriate threshold. To address these questions, we focus on KNN-Shapley and propose Calibrated KNN-Shapley (CKNN-Shapley), which calibrates zero as the threshold to distinguish detrimental samples from beneficial ones by mitigating the negative effects of small-sized training subsets. Through extensive experiments, we demonstrate the effectiveness of CKNN-Shapley in alleviating data valuation inflation, detecting detrimental samples, and assessing data quality. We also extend our approach beyond conventional classification settings, applying it to diverse and practical scenarios such as learning with mislabeled data, online learning with stream data, and active learning for label annotation.
Multi-task Envisioning Transformer-based Autoencoder for Corporate Credit Rating Migration Early Prediction
Jul 10, 2022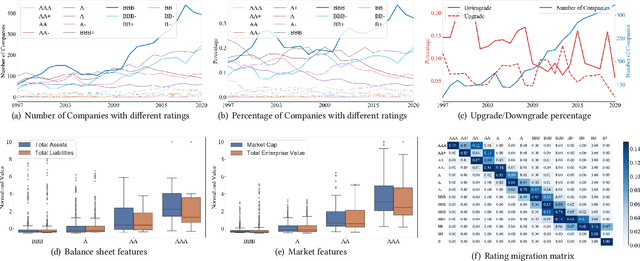

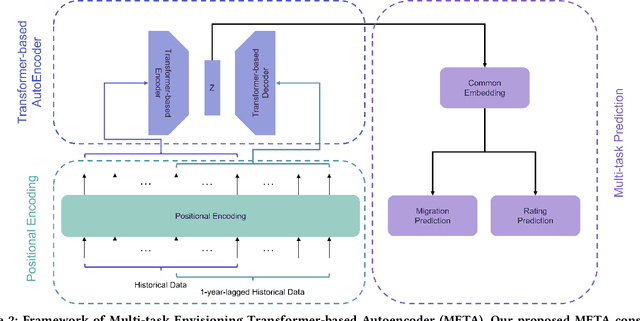
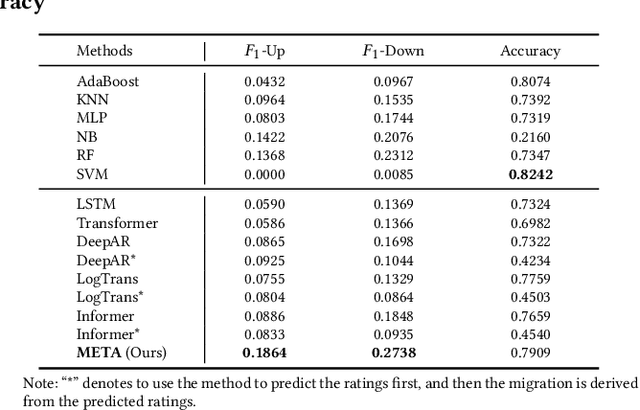
Corporate credit ratings issued by third-party rating agencies are quantified assessments of a company's creditworthiness. Credit Ratings highly correlate to the likelihood of a company defaulting on its debt obligations. These ratings play critical roles in investment decision-making as one of the key risk factors. They are also central to the regulatory framework such as BASEL II in calculating necessary capital for financial institutions. Being able to predict rating changes will greatly benefit both investors and regulators alike. In this paper, we consider the corporate credit rating migration early prediction problem, which predicts the credit rating of an issuer will be upgraded, unchanged, or downgraded after 12 months based on its latest financial reporting information at the time. We investigate the effectiveness of different standard machine learning algorithms and conclude these models deliver inferior performance. As part of our contribution, we propose a new Multi-task Envisioning Transformer-based Autoencoder (META) model to tackle this challenging problem. META consists of Positional Encoding, Transformer-based Autoencoder, and Multi-task Prediction to learn effective representations for both migration prediction and rating prediction. This enables META to better explore the historical data in the training stage for one-year later prediction. Experimental results show that META outperforms all baseline models.
Label-invariant Augmentation for Semi-Supervised Graph Classification
May 19, 2022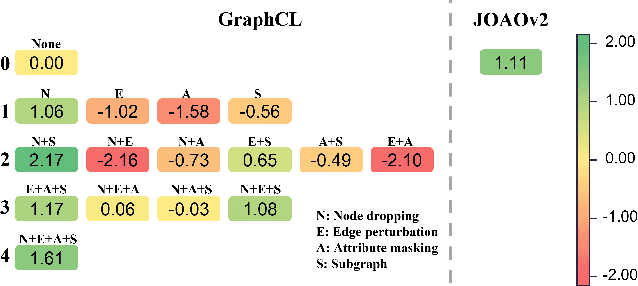
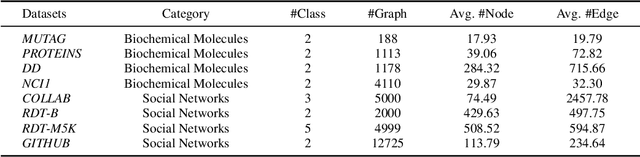
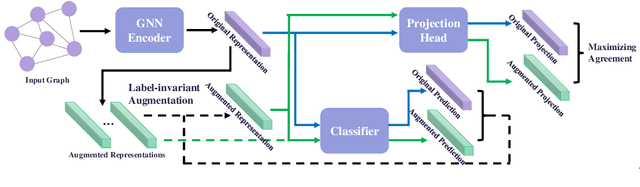
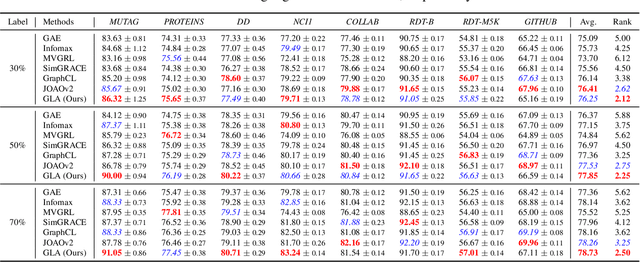
Recently, contrastiveness-based augmentation surges a new climax in the computer vision domain, where some operations, including rotation, crop, and flip, combined with dedicated algorithms, dramatically increase the model generalization and robustness. Following this trend, some pioneering attempts employ the similar idea to graph data. Nevertheless, unlike images, it is much more difficult to design reasonable augmentations without changing the nature of graphs. Although exciting, the current graph contrastive learning does not achieve as promising performance as visual contrastive learning. We conjecture the current performance of graph contrastive learning might be limited by the violation of the label-invariant augmentation assumption. In light of this, we propose a label-invariant augmentation for graph-structured data to address this challenge. Different from the node/edge modification and subgraph extraction, we conduct the augmentation in the representation space and generate the augmented samples in the most difficult direction while keeping the label of augmented data the same as the original samples. In the semi-supervised scenario, we demonstrate our proposed method outperforms the classical graph neural network based methods and recent graph contrastive learning on eight benchmark graph-structured data, followed by several in-depth experiments to further explore the label-invariant augmentation in several aspects.