 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Curvature-Weighted Capacity Allocation: A Minimum Description Length Framework for Layer-Adaptive Large Language Model Optimization
Mar 01, 2026Layer-wise capacity in large language models is highly non-uniform: some layers contribute disproportionately to loss reduction while others are near-redundant. Existing methods for exploiting this non-uniformity, such as influence-function-based layer scoring, produce sensitivity estimates but offer no principled mechanism for translating them into allocation or pruning decisions under hardware constraints. We address this gap with a unified, curvature-aware framework grounded in the Minimum Description Length (MDL) principle. Our central quantity is the curvature-adjusted layer gain $ζ_k^2 = g_k^\top \widetilde{H}_{kk}^{-1} g_k$, which we show equals twice the maximal second-order reduction in empirical risk achievable by updating layer $k$ alone, and which strictly dominates gradient-norm-based scores by incorporating local curvature. Normalizing these gains into layer quality scores $q_k$, we formulate two convex MDL programs: a capacity allocation program that distributes expert slots or LoRA rank preferentially to high-curvature layers under diminishing returns, and a pruning program that concentrates sparsity on low-gain layers while protecting high-gain layers from degradation. Both programs admit unique closed-form solutions parameterized by a single dual variable, computable in $O(K \log 1/\varepsilon)$ via bisection. We prove an $O(δ^2)$ transfer regret bound showing that source-domain allocations remain near-optimal on target tasks when curvature scores drift by $δ$, with explicit constants tied to the condition number of the target program. Together, these results elevate layer-wise capacity optimization from an empirical heuristic to a theoretically grounded, computationally efficient framework with provable optimality and generalization guarantees.
Golden Layers and Where to Find Them: Improved Knowledge Editing for Large Language Models Via Layer Gradient Analysis
Feb 22, 2026Knowledge editing in Large Language Models (LLMs) aims to update the model's prediction for a specific query to a desired target while preserving its behavior on all other inputs. This process typically involves two stages: identifying the layer to edit and performing the parameter update. Intuitively, different queries may localize knowledge at different depths of the model, resulting in different sample-wise editing performance for a fixed editing layer. In this work, we hypothesize the existence of fixed golden layers that can achieve near-optimal editing performance similar to sample-wise optimal layers. To validate this hypothesis, we provide empirical evidence by comparing golden layers against ground-truth sample-wise optimal layers. Furthermore, we show that golden layers can be reliably identified using a proxy dataset and generalize effectively to unseen test set queries across datasets. Finally, we propose a novel method, namely Layer Gradient Analysis (LGA) that estimates golden layers efficiently via gradient-attribution, avoiding extensive trial-and-error across multiple editing runs. Extensive experiments on several benchmark datasets demonstrate the effectiveness and robustness of our LGA approach across different LLM types and various knowledge editing methods.
First is Not Really Better Than Last: Evaluating Layer Choice and Aggregation Strategies in Language Model Data Influence Estimation
Nov 06, 2025Identifying how training samples influence/impact Large Language Model (LLM) decision-making is essential for effectively interpreting model decisions and auditing large-scale datasets. Current training sample influence estimation methods (also known as influence functions) undertake this goal by utilizing information flow through the model via its first-order and higher-order gradient terms. However, owing to the large model sizes of today consisting of billions of parameters, these influence computations are often restricted to some subset of model layers to ensure computational feasibility. Prior seminal work by Yeh et al. (2022) in assessing which layers are best suited for computing language data influence concluded that the first (embedding) layers are the most informative for this purpose, using a hypothesis based on influence scores canceling out (i.e., the cancellation effect). In this work, we propose theoretical and empirical evidence demonstrating how the cancellation effect is unreliable, and that middle attention layers are better estimators for influence. Furthermore, we address the broader challenge of aggregating influence scores across layers, and showcase how alternatives to standard averaging (such as ranking and vote-based methods) can lead to significantly improved performance. Finally, we propose better methods for evaluating influence score efficacy in LLMs without undertaking model retraining, and propose a new metric known as the Noise Detection Rate (NDR) that exhibits strong predictive capability compared to the cancellation effect. Through extensive experiments across LLMs of varying types and scales, we concretely determine that the first (layers) are not necessarily better than the last (layers) for LLM influence estimation, contrasting with prior knowledge in the field.
LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
May 27, 2025Pretrained Large Language Models (LLMs) achieve strong performance across a wide range of tasks, yet exhibit substantial variability in the various layers' training quality with respect to specific downstream applications, limiting their downstream performance.It is therefore critical to estimate layer-wise training quality in a manner that accounts for both model architecture and training data. However, existing approaches predominantly rely on model-centric heuristics (such as spectral statistics, outlier detection, or uniform allocation) while overlooking the influence of data. To address these limitations, we propose LayerIF, a data-driven framework that leverages Influence Functions to quantify the training quality of individual layers in a principled and task-sensitive manner. By isolating each layer's gradients and measuring the sensitivity of the validation loss to training examples by computing layer-wise influences, we derive data-driven estimates of layer importance. Notably, our method produces task-specific layer importance estimates for the same LLM, revealing how layers specialize for different test-time evaluation tasks. We demonstrate the utility of our scores by leveraging them for two downstream applications: (a) expert allocation in LoRA-MoE architectures and (b) layer-wise sparsity distribution for LLM pruning. Experiments across multiple LLM architectures demonstrate that our model-agnostic, influence-guided allocation leads to consistent gains in task performance.
Unraveling Indirect In-Context Learning Using Influence Functions
Jan 01, 2025



This work introduces a novel paradigm for generalized In-Context Learning (ICL), termed Indirect In-Context Learning. In Indirect ICL, we explore demonstration selection strategies tailored for two distinct real-world scenarios: Mixture of Tasks and Noisy Demonstrations. We systematically evaluate the effectiveness of Influence Functions (IFs) as a selection tool for these settings, highlighting the potential for IFs to better capture the informativeness of examples within the demonstration pool. For the Mixture of Tasks setting, demonstrations are drawn from 28 diverse tasks, including MMLU, BigBench, StrategyQA, and CommonsenseQA. We demonstrate that combining BertScore-Recall (BSR) with an IF surrogate model can significantly improve performance, leading to average absolute accuracy gains of 0.37\% and 1.45\% for 3-shot and 5-shot setups when compared to traditional ICL metrics. In the Noisy Demonstrations setting, we examine scenarios where demonstrations might be mislabeled. Our experiments show that reweighting traditional ICL selectors (BSR and Cosine Similarity) with IF-based selectors boosts accuracy by an average of 2.90\% for Cosine Similarity and 2.94\% for BSR on noisy GLUE benchmarks. In sum, we propose a robust framework for demonstration selection that generalizes beyond traditional ICL, offering valuable insights into the role of IFs for Indirect ICL.
Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Jun 06, 2024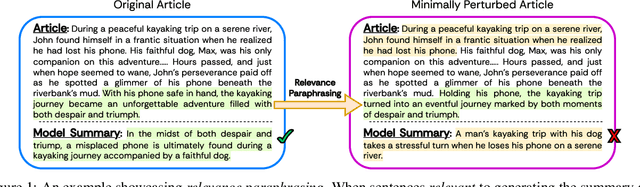
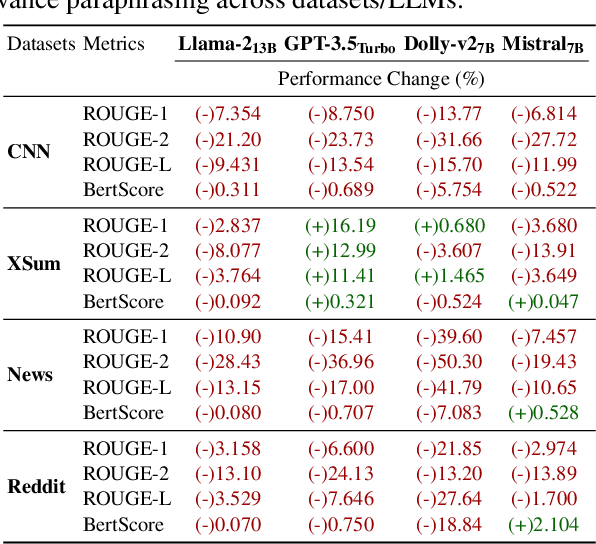
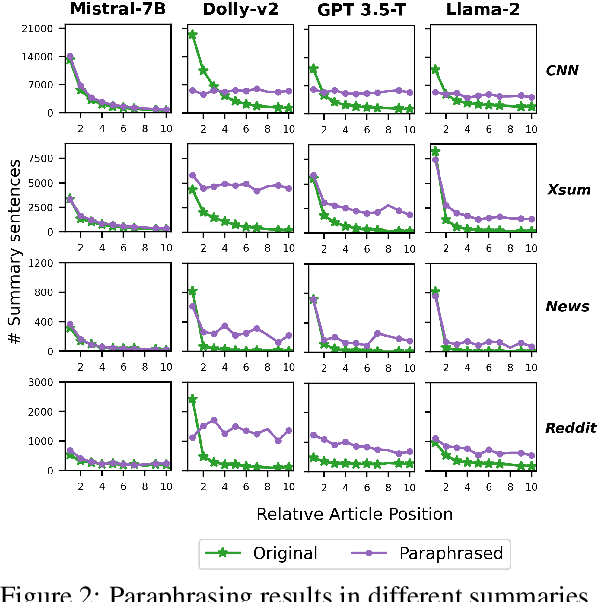
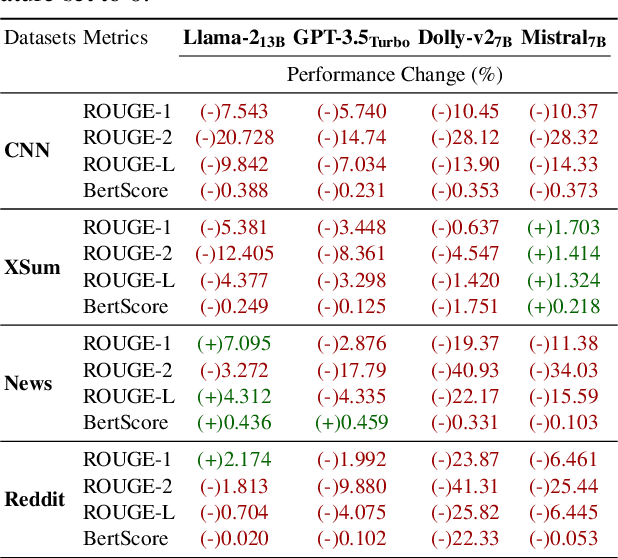
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.
Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions
May 06, 2024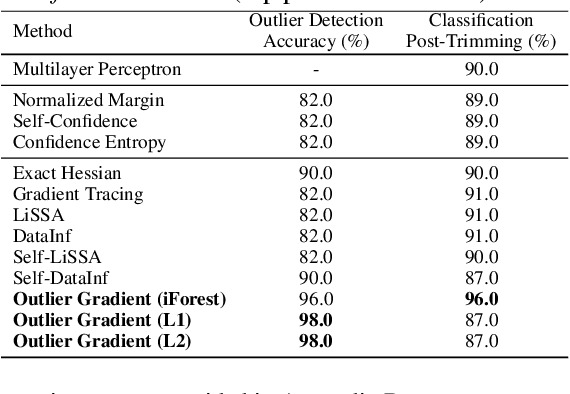
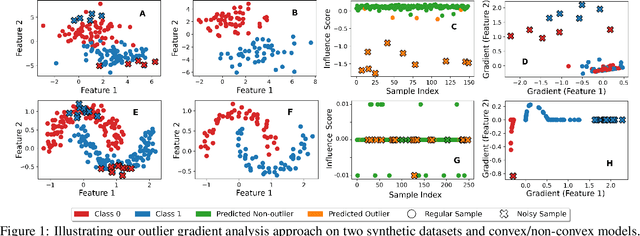
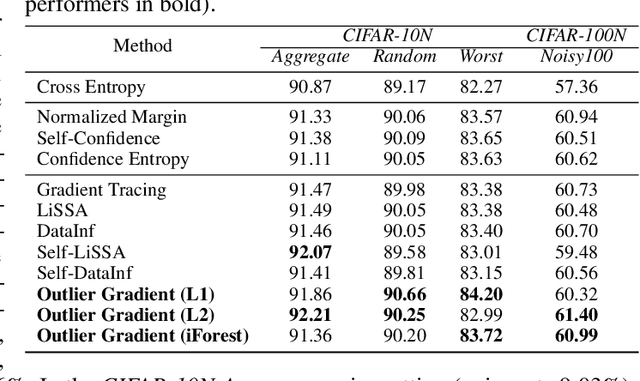

Influence functions offer a robust framework for assessing the impact of each training data sample on model predictions, serving as a prominent tool in data-centric learning. Despite their widespread use in various tasks, the strong convexity assumption on the model and the computational cost associated with calculating the inverse of the Hessian matrix pose constraints, particularly when analyzing large deep models. This paper focuses on a classical data-centric scenario--trimming detrimental samples--and addresses both challenges within a unified framework. Specifically, we establish an equivalence transformation between identifying detrimental training samples via influence functions and outlier gradient detection. This transformation not only presents a straightforward and Hessian-free formulation but also provides profound insights into the role of the gradient in sample impact. Moreover, it relaxes the convexity assumption of influence functions, extending their applicability to non-convex deep models. Through systematic empirical evaluations, we first validate the correctness of our proposed outlier gradient analysis on synthetic datasets and then demonstrate its effectiveness in detecting mislabeled samples in vision models, selecting data samples for improving performance of transformer models for natural language processing, and identifying influential samples for fine-tuned Large Language Models.
Incentivizing News Consumption on Social Media Platforms Using Large Language Models and Realistic Bot Accounts
Mar 30, 2024
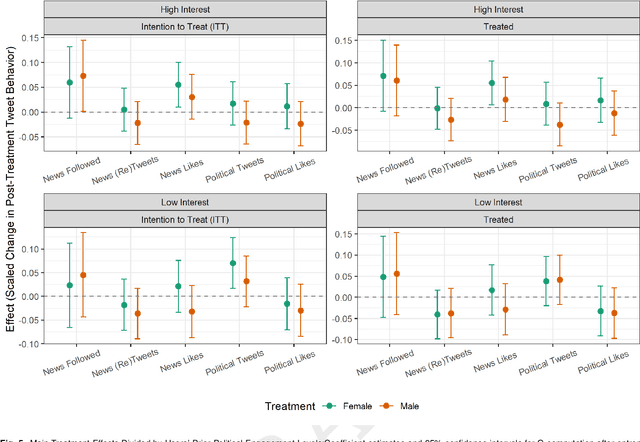
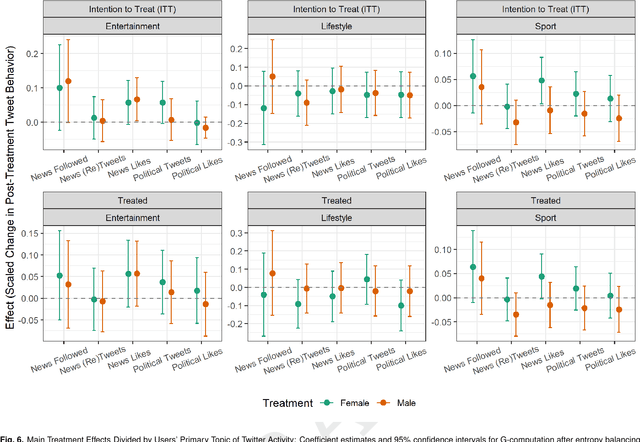
Polarization, declining trust, and wavering support for democratic norms are pressing threats to U.S. democracy. Exposure to verified and quality news may lower individual susceptibility to these threats and make citizens more resilient to misinformation, populism, and hyperpartisan rhetoric. This project examines how to enhance users' exposure to and engagement with verified and ideologically balanced news in an ecologically valid setting. We rely on a large-scale two-week long field experiment (from 1/19/2023 to 2/3/2023) on 28,457 Twitter users. We created 28 bots utilizing GPT-2 that replied to users tweeting about sports, entertainment, or lifestyle with a contextual reply containing two hardcoded elements: a URL to the topic-relevant section of quality news organization and an encouragement to follow its Twitter account. To further test differential effects by gender of the bots, treated users were randomly assigned to receive responses by bots presented as female or male. We examine whether our over-time intervention enhances the following of news media organization, the sharing and the liking of news content and the tweeting about politics and the liking of political content. We find that the treated users followed more news accounts and the users in the female bot treatment were more likely to like news content than the control. Most of these results, however, were small in magnitude and confined to the already politically interested Twitter users, as indicated by their pre-treatment tweeting about politics. These findings have implications for social media and news organizations, and also offer direction for future work on how Large Language Models and other computational interventions can effectively enhance individual on-platform engagement with quality news and public affairs.
Revisiting Zero-Shot Abstractive Summarization in the Era of Large Language Models from the Perspective of Position Bias
Jan 03, 2024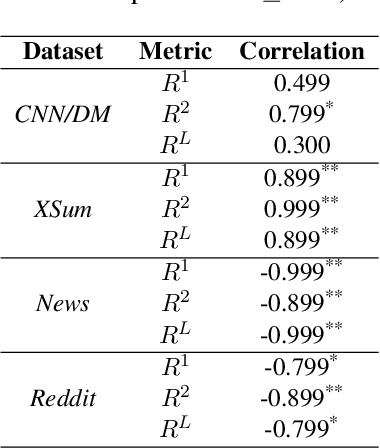
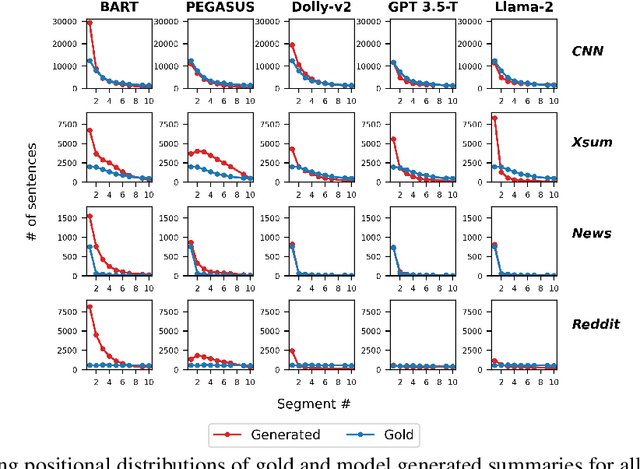
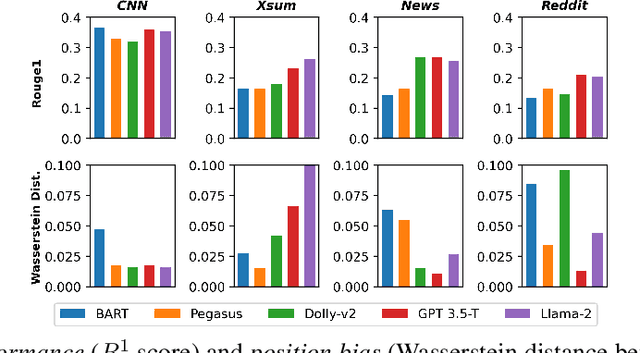
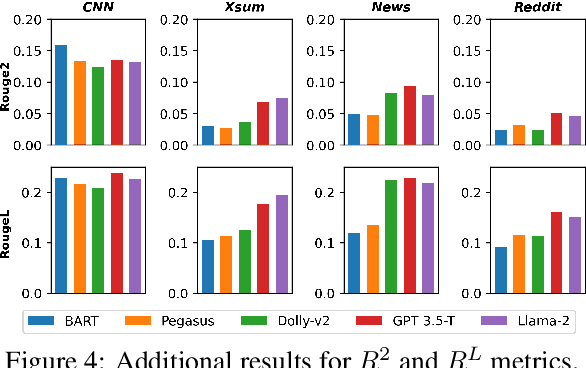
We characterize and study zero-shot abstractive summarization in Large Language Models (LLMs) by measuring position bias, which we propose as a general formulation of the more restrictive lead bias phenomenon studied previously in the literature. Position bias captures the tendency of a model unfairly prioritizing information from certain parts of the input text over others, leading to undesirable behavior. Through numerous experiments on four diverse real-world datasets, we study position bias in multiple LLM models such as GPT 3.5-Turbo, Llama-2, and Dolly-v2, as well as state-of-the-art pretrained encoder-decoder abstractive summarization models such as Pegasus and BART. Our findings lead to novel insights and discussion on performance and position bias of models for zero-shot summarization tasks.