 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Natural Language for Multi-agent Decision-Making with Multi-agentic LLMs
Aug 10, 2025Language is a ubiquitous tool that is foundational to reasoning and collaboration, ranging from everyday interactions to sophisticated problem-solving tasks. The establishment of a common language can serve as a powerful asset in ensuring clear communication and understanding amongst agents, facilitating desired coordination and strategies. In this work, we extend the capabilities of large language models (LLMs) by integrating them with advancements in multi-agent decision-making algorithms. We propose a systematic framework for the design of multi-agentic large language models (LLMs), focusing on key integration practices. These include advanced prompt engineering techniques, the development of effective memory architectures, multi-modal information processing, and alignment strategies through fine-tuning algorithms. We evaluate these design choices through extensive ablation studies on classic game settings with significant underlying social dilemmas and game-theoretic considerations.
Identity-Focused Inference and Extraction Attacks on Diffusion Models
Oct 14, 2024The increasing reliance on diffusion models for generating synthetic images has amplified concerns about the unauthorized use of personal data, particularly facial images, in model training. In this paper, we introduce a novel identity inference framework to hold model owners accountable for including individuals' identities in their training data. Our approach moves beyond traditional membership inference attacks by focusing on identity-level inference, providing a new perspective on data privacy violations. Through comprehensive evaluations on two facial image datasets, Labeled Faces in the Wild (LFW) and CelebA, our experiments demonstrate that the proposed membership inference attack surpasses baseline methods, achieving an attack success rate of up to 89% and an AUC-ROC of 0.91, while the identity inference attack attains 92% on LDM models trained on LFW, and the data extraction attack achieves 91.6% accuracy on DDPMs, validating the effectiveness of our approach across diffusion models.
PTQ4ADM: Post-Training Quantization for Efficient Text Conditional Audio Diffusion Models
Sep 20, 2024Denoising diffusion models have emerged as state-of-the-art in generative tasks across image, audio, and video domains, producing high-quality, diverse, and contextually relevant data. However, their broader adoption is limited by high computational costs and large memory footprints. Post-training quantization (PTQ) offers a promising approach to mitigate these challenges by reducing model complexity through low-bandwidth parameters. Yet, direct application of PTQ to diffusion models can degrade synthesis quality due to accumulated quantization noise across multiple denoising steps, particularly in conditional tasks like text-to-audio synthesis. This work introduces PTQ4ADM, a novel framework for quantizing audio diffusion models(ADMs). Our key contributions include (1) a coverage-driven prompt augmentation method and (2) an activation-aware calibration set generation algorithm for text-conditional ADMs. These techniques ensure comprehensive coverage of audio aspects and modalities while preserving synthesis fidelity. We validate our approach on TANGO, Make-An-Audio, and AudioLDM models for text-conditional audio generation. Extensive experiments demonstrate PTQ4ADM's capability to reduce the model size by up to 70\% while achieving synthesis quality metrics comparable to full-precision models($<$5\% increase in FD scores). We show that specific layers in the backbone network can be quantized to 4-bit weights and 8-bit activations without significant quality loss. This work paves the way for more efficient deployment of ADMs in resource-constrained environments.
Augmented Efficiency: Reducing Memory Footprint and Accelerating Inference for 3D Semantic Segmentation through Hybrid Vision
Jul 23, 2024
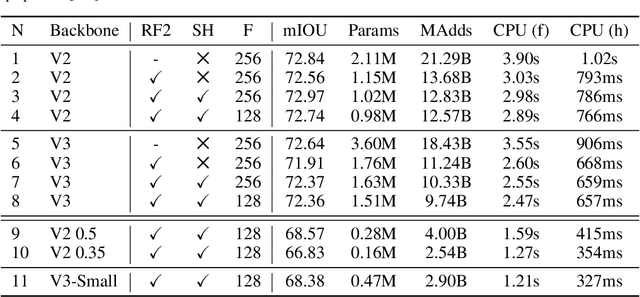
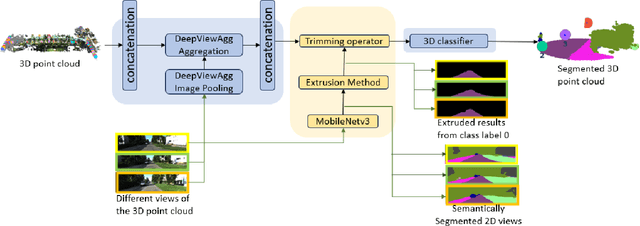

Semantic segmentation has emerged as a pivotal area of study in computer vision, offering profound implications for scene understanding and elevating human-machine interactions across various domains. While 2D semantic segmentation has witnessed significant strides in the form of lightweight, high-precision models, transitioning to 3D semantic segmentation poses distinct challenges. Our research focuses on achieving efficiency and lightweight design for 3D semantic segmentation models, similar to those achieved for 2D models. Such a design impacts applications of 3D semantic segmentation where memory and latency are of concern. This paper introduces a novel approach to 3D semantic segmentation, distinguished by incorporating a hybrid blend of 2D and 3D computer vision techniques, enabling a streamlined, efficient process. We conduct 2D semantic segmentation on RGB images linked to 3D point clouds and extend the results to 3D using an extrusion technique for specific class labels, reducing the point cloud subspace. We perform rigorous evaluations with the DeepViewAgg model on the complete point cloud as our baseline by measuring the Intersection over Union (IoU) accuracy, inference time latency, and memory consumption. This model serves as the current state-of-the-art 3D semantic segmentation model on the KITTI-360 dataset. We can achieve heightened accuracy outcomes, surpassing the baseline for 6 out of the 15 classes while maintaining a marginal 1% deviation below the baseline for the remaining class labels. Our segmentation approach demonstrates a 1.347x speedup and about a 43% reduced memory usage compared to the baseline.
FedDM: Enhancing Communication Efficiency and Handling Data Heterogeneity in Federated Diffusion Models
Jul 20, 2024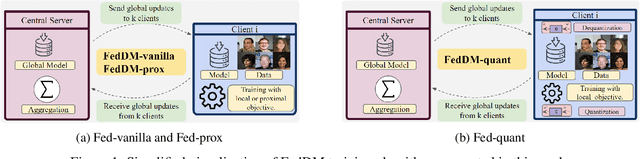
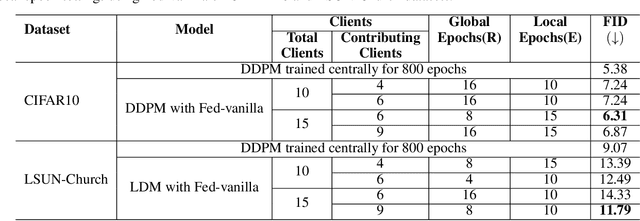

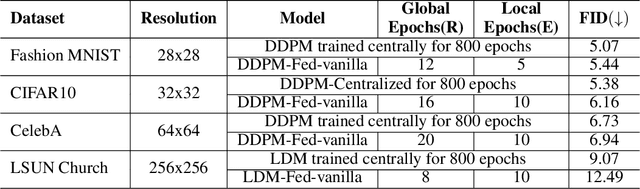
We introduce FedDM, a novel training framework designed for the federated training of diffusion models. Our theoretical analysis establishes the convergence of diffusion models when trained in a federated setting, presenting the specific conditions under which this convergence is guaranteed. We propose a suite of training algorithms that leverage the U-Net architecture as the backbone for our diffusion models. These include a basic Federated Averaging variant, FedDM-vanilla, FedDM-prox to handle data heterogeneity among clients, and FedDM-quant, which incorporates a quantization module to reduce the model update size, thereby enhancing communication efficiency across the federated network. We evaluate our algorithms on FashionMNIST (28x28 resolution), CIFAR-10 (32x32 resolution), and CelebA (64x64 resolution) for DDPMs, as well as LSUN Church Outdoors (256x256 resolution) for LDMs, focusing exclusively on the imaging modality. Our evaluation results demonstrate that FedDM algorithms maintain high generation quality across image resolutions. At the same time, the use of quantized updates and proximal terms in the local training objective significantly enhances communication efficiency (up to 4x) and model convergence, particularly in non-IID data settings, at the cost of increased FID scores (up to 1.75x).
Assessing LLMs for Zero-shot Abstractive Summarization Through the Lens of Relevance Paraphrasing
Jun 06, 2024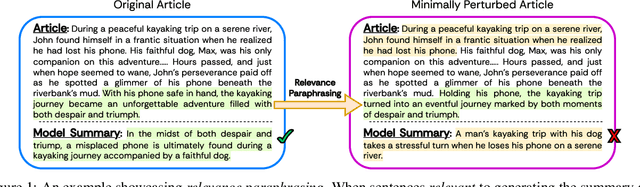
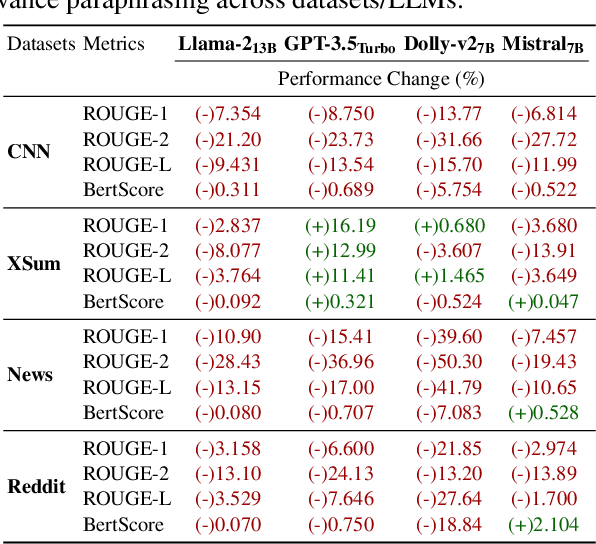
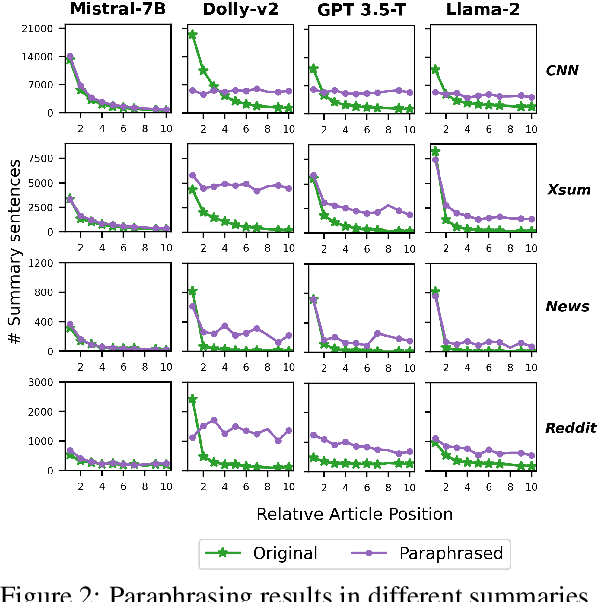
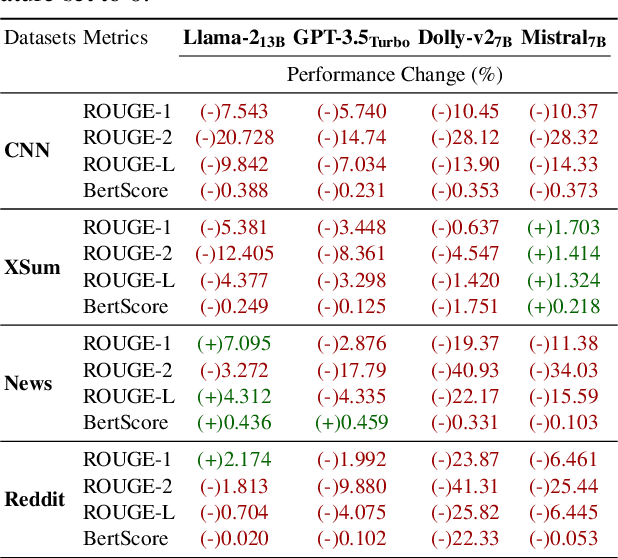
Large Language Models (LLMs) have achieved state-of-the-art performance at zero-shot generation of abstractive summaries for given articles. However, little is known about the robustness of such a process of zero-shot summarization. To bridge this gap, we propose relevance paraphrasing, a simple strategy that can be used to measure the robustness of LLMs as summarizers. The relevance paraphrasing approach identifies the most relevant sentences that contribute to generating an ideal summary, and then paraphrases these inputs to obtain a minimally perturbed dataset. Then, by evaluating model performance for summarization on both the original and perturbed datasets, we can assess the LLM's one aspect of robustness. We conduct extensive experiments with relevance paraphrasing on 4 diverse datasets, as well as 4 LLMs of different sizes (GPT-3.5-Turbo, Llama-2-13B, Mistral-7B, and Dolly-v2-7B). Our results indicate that LLMs are not consistent summarizers for the minimally perturbed articles, necessitating further improvements.
Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Jun 05, 2024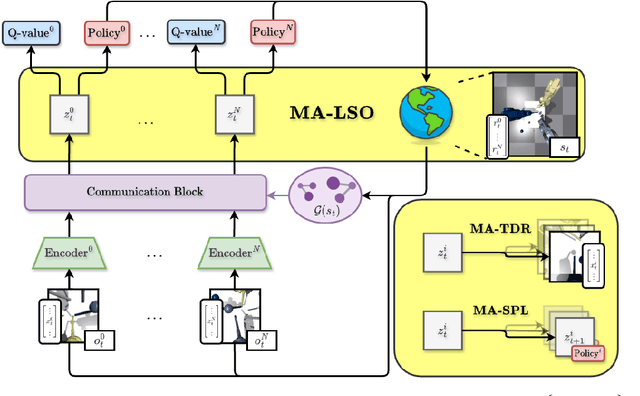
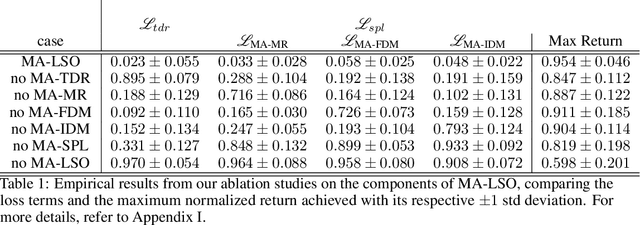
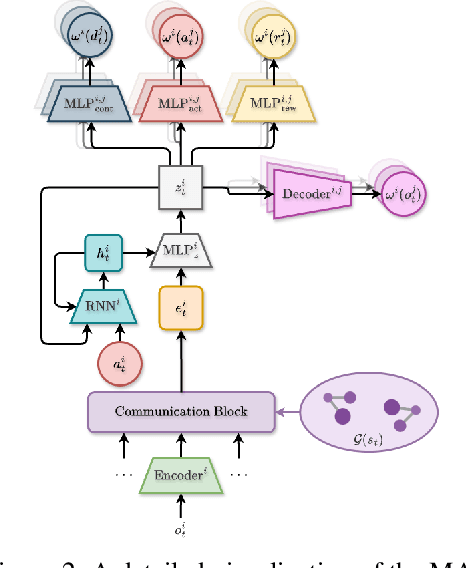
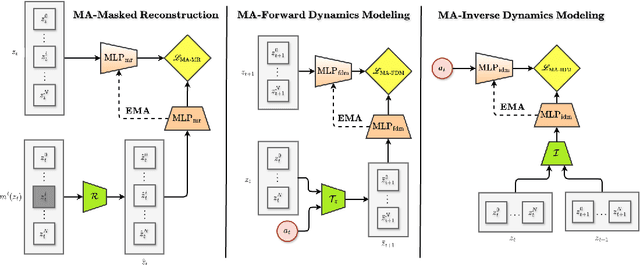
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions
May 06, 2024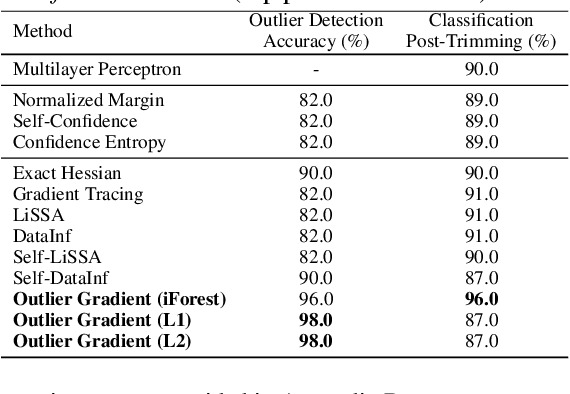
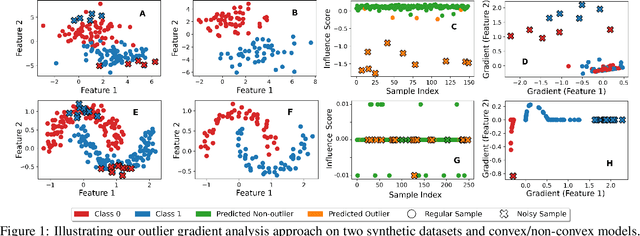
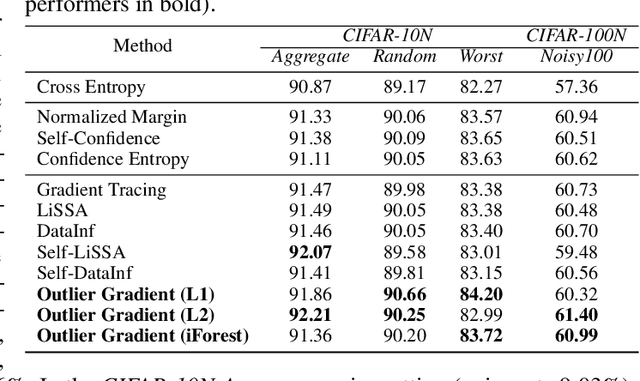

Influence functions offer a robust framework for assessing the impact of each training data sample on model predictions, serving as a prominent tool in data-centric learning. Despite their widespread use in various tasks, the strong convexity assumption on the model and the computational cost associated with calculating the inverse of the Hessian matrix pose constraints, particularly when analyzing large deep models. This paper focuses on a classical data-centric scenario--trimming detrimental samples--and addresses both challenges within a unified framework. Specifically, we establish an equivalence transformation between identifying detrimental training samples via influence functions and outlier gradient detection. This transformation not only presents a straightforward and Hessian-free formulation but also provides profound insights into the role of the gradient in sample impact. Moreover, it relaxes the convexity assumption of influence functions, extending their applicability to non-convex deep models. Through systematic empirical evaluations, we first validate the correctness of our proposed outlier gradient analysis on synthetic datasets and then demonstrate its effectiveness in detecting mislabeled samples in vision models, selecting data samples for improving performance of transformer models for natural language processing, and identifying influential samples for fine-tuned Large Language Models.
Robust Explainable Recommendation
May 03, 2024Explainable Recommender Systems is an important field of study which provides reasons behind the suggested recommendations. Explanations with recommender systems are useful for developers while debugging anomalies within the system and for consumers while interpreting the model's effectiveness in capturing their true preferences towards items. However, most of the existing state-of-the-art (SOTA) explainable recommenders could not retain their explanation capability under noisy circumstances and moreover are not generalizable across different datasets. The robustness of the explanations must be ensured so that certain malicious attackers do not manipulate any high-stake decision scenarios to their advantage, which could cause severe consequences affecting large groups of interest. In this work, we present a general framework for feature-aware explainable recommenders that can withstand external attacks and provide robust and generalized explanations. This paper presents a novel framework which could be utilized as an additional defense tool, preserving the global explainability when subject to model-based white box attacks. Our framework is simple to implement and supports different methods regardless of the internal model structure and intrinsic utility within any model. We experimented our framework on two architecturally different feature-based SOTA explainable algorithms by training them on three popular e-commerce datasets of increasing scales. We noticed that both the algorithms displayed an overall improvement in the quality and robustness of the global explainability under normal as well as noisy environments across all the datasets, indicating the flexibility and mutability of our framework.
Stability of Explainable Recommendation
May 03, 2024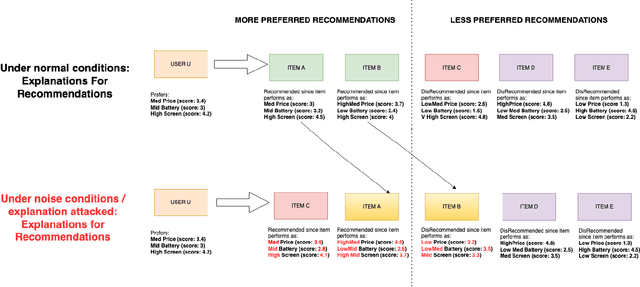

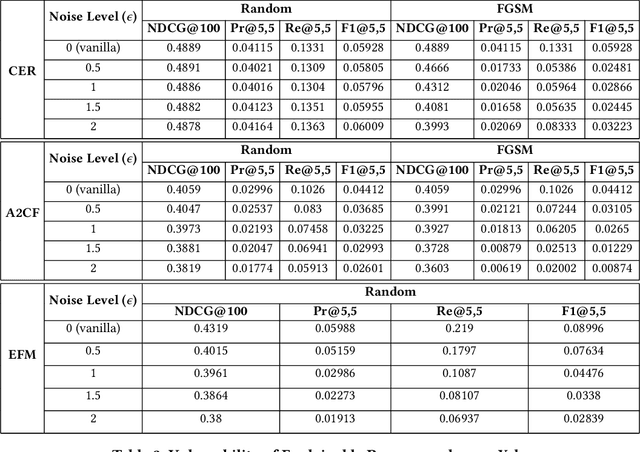
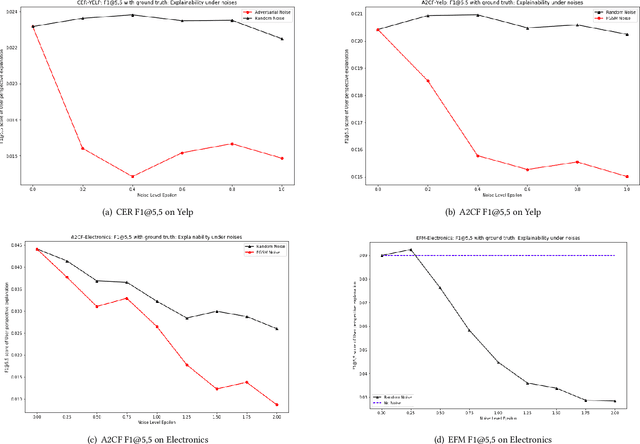
Explainable Recommendation has been gaining attention over the last few years in industry and academia. Explanations provided along with recommendations in a recommender system framework have many uses: particularly reasoning why a suggestion is provided and how well an item aligns with a user's personalized preferences. Hence, explanations can play a huge role in influencing users to purchase products. However, the reliability of the explanations under varying scenarios has not been strictly verified from an empirical perspective. Unreliable explanations can bear strong consequences such as attackers leveraging explanations for manipulating and tempting users to purchase target items that the attackers would want to promote. In this paper, we study the vulnerability of existent feature-oriented explainable recommenders, particularly analyzing their performance under different levels of external noises added into model parameters. We conducted experiments by analyzing three important state-of-the-art (SOTA) explainable recommenders when trained on two widely used e-commerce based recommendation datasets of different scales. We observe that all the explainable models are vulnerable to increased noise levels. Experimental results verify our hypothesis that the ability to explain recommendations does decrease along with increasing noise levels and particularly adversarial noise does contribute to a much stronger decrease. Our study presents an empirical verification on the topic of robust explanations in recommender systems which can be extended to different types of explainable recommenders in RS.