 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Efficiency: Reducing Memory Footprint and Accelerating Inference for 3D Semantic Segmentation through Hybrid Vision
Paper and Code
Jul 23, 2024
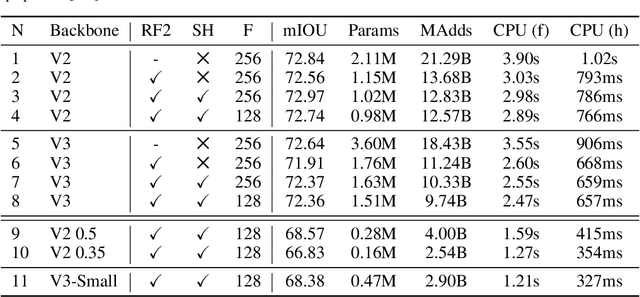
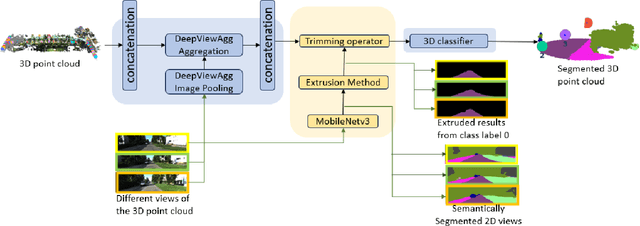

Semantic segmentation has emerged as a pivotal area of study in computer vision, offering profound implications for scene understanding and elevating human-machine interactions across various domains. While 2D semantic segmentation has witnessed significant strides in the form of lightweight, high-precision models, transitioning to 3D semantic segmentation poses distinct challenges. Our research focuses on achieving efficiency and lightweight design for 3D semantic segmentation models, similar to those achieved for 2D models. Such a design impacts applications of 3D semantic segmentation where memory and latency are of concern. This paper introduces a novel approach to 3D semantic segmentation, distinguished by incorporating a hybrid blend of 2D and 3D computer vision techniques, enabling a streamlined, efficient process. We conduct 2D semantic segmentation on RGB images linked to 3D point clouds and extend the results to 3D using an extrusion technique for specific class labels, reducing the point cloud subspace. We perform rigorous evaluations with the DeepViewAgg model on the complete point cloud as our baseline by measuring the Intersection over Union (IoU) accuracy, inference time latency, and memory consumption. This model serves as the current state-of-the-art 3D semantic segmentation model on the KITTI-360 dataset. We can achieve heightened accuracy outcomes, surpassing the baseline for 6 out of the 15 classes while maintaining a marginal 1% deviation below the baseline for the remaining class labels. Our segmentation approach demonstrates a 1.347x speedup and about a 43% reduced memory usage compared to the baseline.