 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Focused Inference and Extraction Attacks on Diffusion Models
Oct 14, 2024The increasing reliance on diffusion models for generating synthetic images has amplified concerns about the unauthorized use of personal data, particularly facial images, in model training. In this paper, we introduce a novel identity inference framework to hold model owners accountable for including individuals' identities in their training data. Our approach moves beyond traditional membership inference attacks by focusing on identity-level inference, providing a new perspective on data privacy violations. Through comprehensive evaluations on two facial image datasets, Labeled Faces in the Wild (LFW) and CelebA, our experiments demonstrate that the proposed membership inference attack surpasses baseline methods, achieving an attack success rate of up to 89% and an AUC-ROC of 0.91, while the identity inference attack attains 92% on LDM models trained on LFW, and the data extraction attack achieves 91.6% accuracy on DDPMs, validating the effectiveness of our approach across diffusion models.
PTQ4ADM: Post-Training Quantization for Efficient Text Conditional Audio Diffusion Models
Sep 20, 2024Denoising diffusion models have emerged as state-of-the-art in generative tasks across image, audio, and video domains, producing high-quality, diverse, and contextually relevant data. However, their broader adoption is limited by high computational costs and large memory footprints. Post-training quantization (PTQ) offers a promising approach to mitigate these challenges by reducing model complexity through low-bandwidth parameters. Yet, direct application of PTQ to diffusion models can degrade synthesis quality due to accumulated quantization noise across multiple denoising steps, particularly in conditional tasks like text-to-audio synthesis. This work introduces PTQ4ADM, a novel framework for quantizing audio diffusion models(ADMs). Our key contributions include (1) a coverage-driven prompt augmentation method and (2) an activation-aware calibration set generation algorithm for text-conditional ADMs. These techniques ensure comprehensive coverage of audio aspects and modalities while preserving synthesis fidelity. We validate our approach on TANGO, Make-An-Audio, and AudioLDM models for text-conditional audio generation. Extensive experiments demonstrate PTQ4ADM's capability to reduce the model size by up to 70\% while achieving synthesis quality metrics comparable to full-precision models($<$5\% increase in FD scores). We show that specific layers in the backbone network can be quantized to 4-bit weights and 8-bit activations without significant quality loss. This work paves the way for more efficient deployment of ADMs in resource-constrained environments.
Augmented Efficiency: Reducing Memory Footprint and Accelerating Inference for 3D Semantic Segmentation through Hybrid Vision
Jul 23, 2024
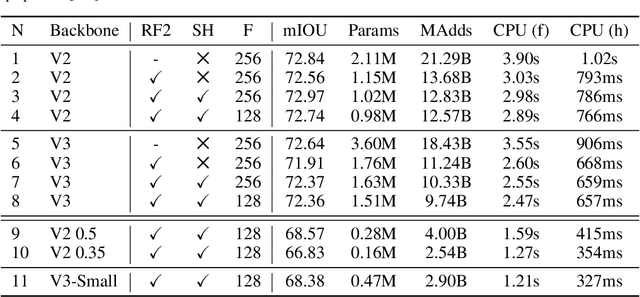
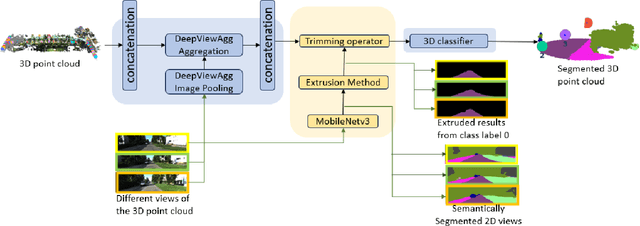

Semantic segmentation has emerged as a pivotal area of study in computer vision, offering profound implications for scene understanding and elevating human-machine interactions across various domains. While 2D semantic segmentation has witnessed significant strides in the form of lightweight, high-precision models, transitioning to 3D semantic segmentation poses distinct challenges. Our research focuses on achieving efficiency and lightweight design for 3D semantic segmentation models, similar to those achieved for 2D models. Such a design impacts applications of 3D semantic segmentation where memory and latency are of concern. This paper introduces a novel approach to 3D semantic segmentation, distinguished by incorporating a hybrid blend of 2D and 3D computer vision techniques, enabling a streamlined, efficient process. We conduct 2D semantic segmentation on RGB images linked to 3D point clouds and extend the results to 3D using an extrusion technique for specific class labels, reducing the point cloud subspace. We perform rigorous evaluations with the DeepViewAgg model on the complete point cloud as our baseline by measuring the Intersection over Union (IoU) accuracy, inference time latency, and memory consumption. This model serves as the current state-of-the-art 3D semantic segmentation model on the KITTI-360 dataset. We can achieve heightened accuracy outcomes, surpassing the baseline for 6 out of the 15 classes while maintaining a marginal 1% deviation below the baseline for the remaining class labels. Our segmentation approach demonstrates a 1.347x speedup and about a 43% reduced memory usage compared to the baseline.
FedDM: Enhancing Communication Efficiency and Handling Data Heterogeneity in Federated Diffusion Models
Jul 20, 2024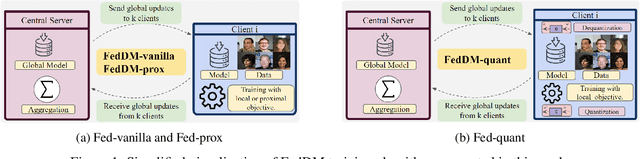
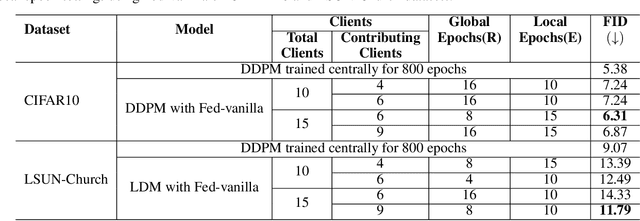

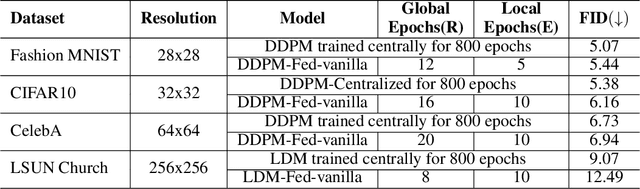
We introduce FedDM, a novel training framework designed for the federated training of diffusion models. Our theoretical analysis establishes the convergence of diffusion models when trained in a federated setting, presenting the specific conditions under which this convergence is guaranteed. We propose a suite of training algorithms that leverage the U-Net architecture as the backbone for our diffusion models. These include a basic Federated Averaging variant, FedDM-vanilla, FedDM-prox to handle data heterogeneity among clients, and FedDM-quant, which incorporates a quantization module to reduce the model update size, thereby enhancing communication efficiency across the federated network. We evaluate our algorithms on FashionMNIST (28x28 resolution), CIFAR-10 (32x32 resolution), and CelebA (64x64 resolution) for DDPMs, as well as LSUN Church Outdoors (256x256 resolution) for LDMs, focusing exclusively on the imaging modality. Our evaluation results demonstrate that FedDM algorithms maintain high generation quality across image resolutions. At the same time, the use of quantized updates and proximal terms in the local training objective significantly enhances communication efficiency (up to 4x) and model convergence, particularly in non-IID data settings, at the cost of increased FID scores (up to 1.75x).