 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of Explainable Recommendation
Paper and Code
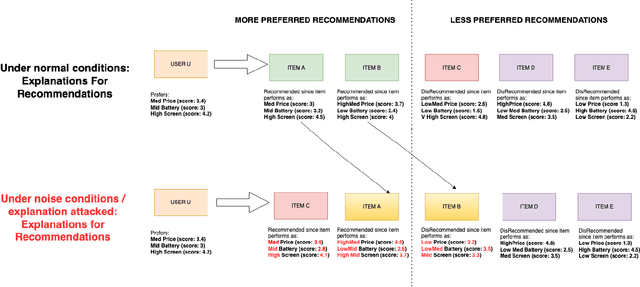

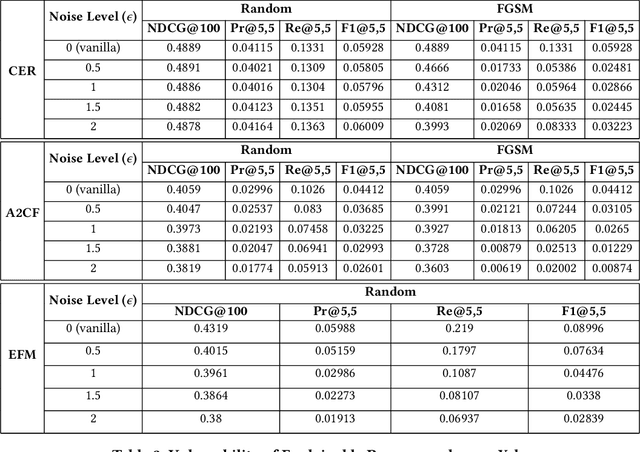
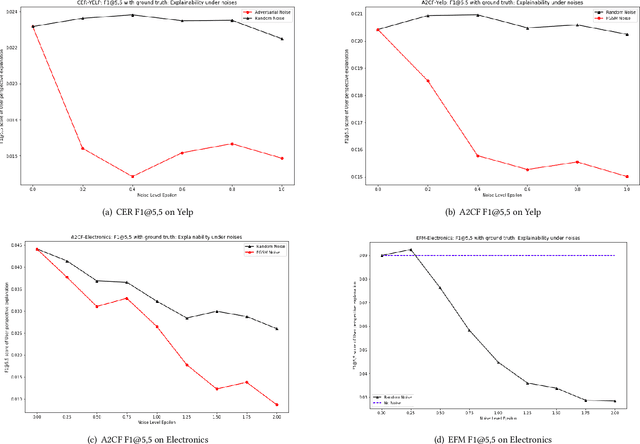
Explainable Recommendation has been gaining attention over the last few years in industry and academia. Explanations provided along with recommendations in a recommender system framework have many uses: particularly reasoning why a suggestion is provided and how well an item aligns with a user's personalized preferences. Hence, explanations can play a huge role in influencing users to purchase products. However, the reliability of the explanations under varying scenarios has not been strictly verified from an empirical perspective. Unreliable explanations can bear strong consequences such as attackers leveraging explanations for manipulating and tempting users to purchase target items that the attackers would want to promote. In this paper, we study the vulnerability of existent feature-oriented explainable recommenders, particularly analyzing their performance under different levels of external noises added into model parameters. We conducted experiments by analyzing three important state-of-the-art (SOTA) explainable recommenders when trained on two widely used e-commerce based recommendation datasets of different scales. We observe that all the explainable models are vulnerable to increased noise levels. Experimental results verify our hypothesis that the ability to explain recommendations does decrease along with increasing noise levels and particularly adversarial noise does contribute to a much stronger decrease. Our study presents an empirical verification on the topic of robust explanations in recommender systems which can be extended to different types of explainable recommenders in RS.