 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Explainable Recommendation
May 03, 2024Explainable Recommender Systems is an important field of study which provides reasons behind the suggested recommendations. Explanations with recommender systems are useful for developers while debugging anomalies within the system and for consumers while interpreting the model's effectiveness in capturing their true preferences towards items. However, most of the existing state-of-the-art (SOTA) explainable recommenders could not retain their explanation capability under noisy circumstances and moreover are not generalizable across different datasets. The robustness of the explanations must be ensured so that certain malicious attackers do not manipulate any high-stake decision scenarios to their advantage, which could cause severe consequences affecting large groups of interest. In this work, we present a general framework for feature-aware explainable recommenders that can withstand external attacks and provide robust and generalized explanations. This paper presents a novel framework which could be utilized as an additional defense tool, preserving the global explainability when subject to model-based white box attacks. Our framework is simple to implement and supports different methods regardless of the internal model structure and intrinsic utility within any model. We experimented our framework on two architecturally different feature-based SOTA explainable algorithms by training them on three popular e-commerce datasets of increasing scales. We noticed that both the algorithms displayed an overall improvement in the quality and robustness of the global explainability under normal as well as noisy environments across all the datasets, indicating the flexibility and mutability of our framework.
Stability of Explainable Recommendation
May 03, 2024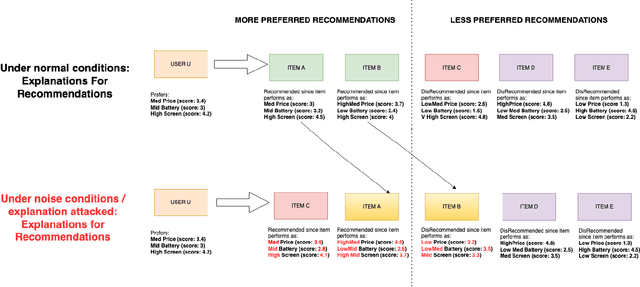

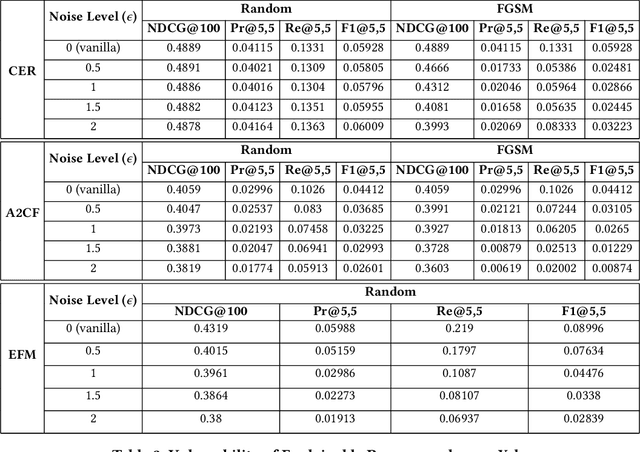
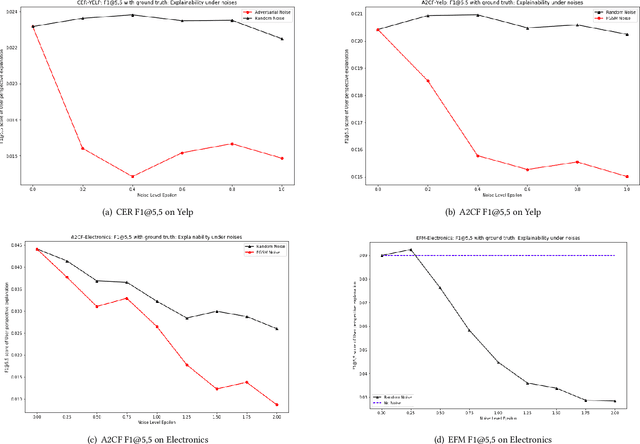
Explainable Recommendation has been gaining attention over the last few years in industry and academia. Explanations provided along with recommendations in a recommender system framework have many uses: particularly reasoning why a suggestion is provided and how well an item aligns with a user's personalized preferences. Hence, explanations can play a huge role in influencing users to purchase products. However, the reliability of the explanations under varying scenarios has not been strictly verified from an empirical perspective. Unreliable explanations can bear strong consequences such as attackers leveraging explanations for manipulating and tempting users to purchase target items that the attackers would want to promote. In this paper, we study the vulnerability of existent feature-oriented explainable recommenders, particularly analyzing their performance under different levels of external noises added into model parameters. We conducted experiments by analyzing three important state-of-the-art (SOTA) explainable recommenders when trained on two widely used e-commerce based recommendation datasets of different scales. We observe that all the explainable models are vulnerable to increased noise levels. Experimental results verify our hypothesis that the ability to explain recommendations does decrease along with increasing noise levels and particularly adversarial noise does contribute to a much stronger decrease. Our study presents an empirical verification on the topic of robust explanations in recommender systems which can be extended to different types of explainable recommenders in RS.
GAN based Data Augmentation to Resolve Class Imbalance
Jun 12, 2022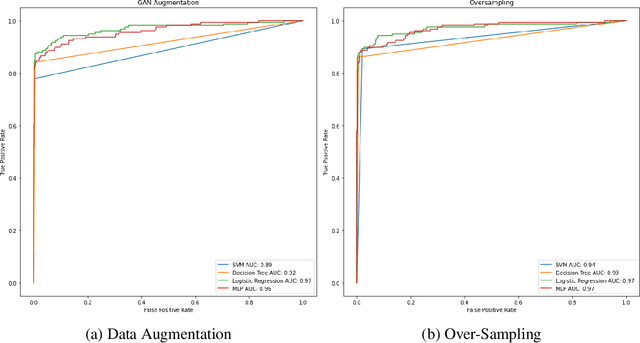
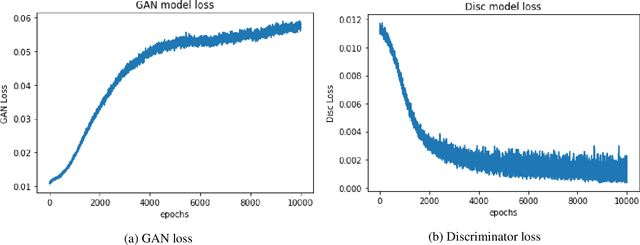

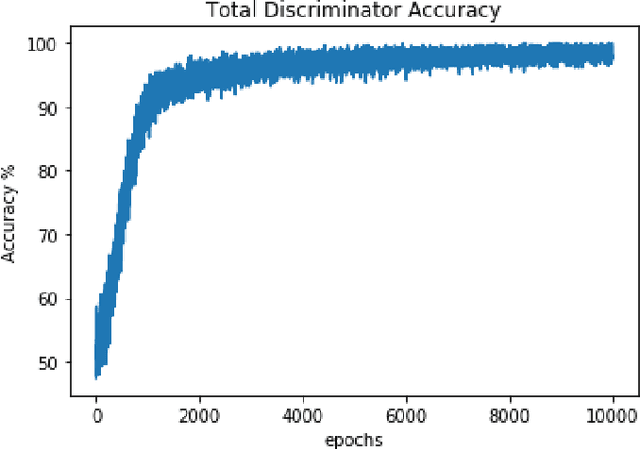
The number of credit card fraud has been growing as technology grows and people can take advantage of it. Therefore, it is very important to implement a robust and effective method to detect such frauds. The machine learning algorithms are appropriate for these tasks since they try to maximize the accuracy of predictions and hence can be relied upon. However, there is an impending flaw where in machine learning models may not perform well due to the presence of an imbalance across classes distribution within the sample set. So, in many related tasks, the datasets have a very small number of observed fraud cases (sometimes around 1 percent positive fraud instances found). Therefore, this imbalance presence may impact any learning model's behavior by predicting all labels as the majority class, hence allowing no scope for generalization in the predictions made by the model. We trained Generative Adversarial Network(GAN) to generate a large number of convincing (and reliable) synthetic examples of the minority class that can be used to alleviate the class imbalance within the training set and hence generalize the learning of the data more effectively.
Semantic Motion Correction Via Iterative Nonlinear Optimization and Animation
Mar 28, 2022

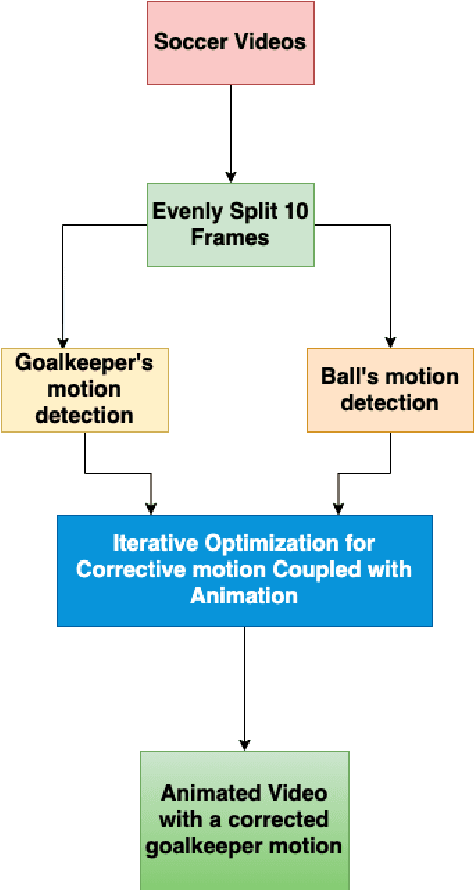
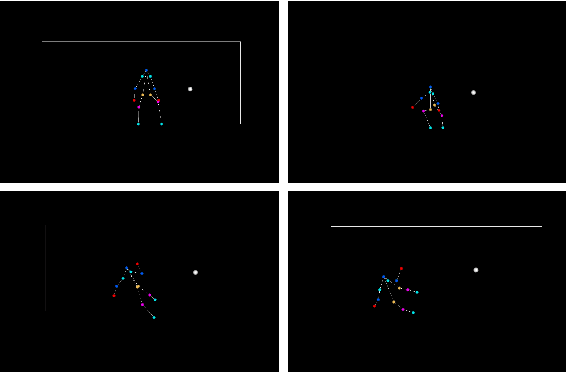
Here, we present an end-to-end method to create 2D animation for a goalkeeper attempting to block a penalty kick, and then correct that motion using an iterative nonlinear optimization scheme. The input is a raw video that is fed into pose and object detection networks to find the skeleton of the goalkeeper and the ball. The output is a set of key frames of the skeleton associated with the corrected motion so that if the goalkeeper missed the ball, the animation will show then successfully deflecting it. Our method is robust enough correct different kinds of mistakes the goalkeeper can make, such as not lunging far enough or jumping to the incorrect side. Our method is also meant to be semantically similar to the goalkeeper's original motion, which helps keep our animation grounded with respect to actual human behavior.
A Deep Learning Technique using a Sequence of Follow Up X-Rays for Disease classification
Mar 28, 2022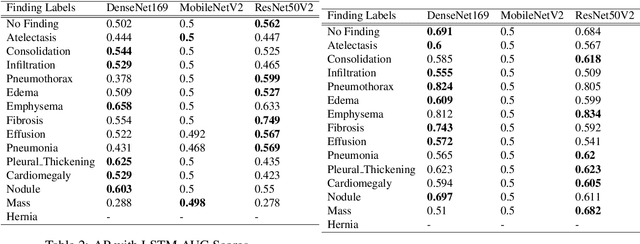
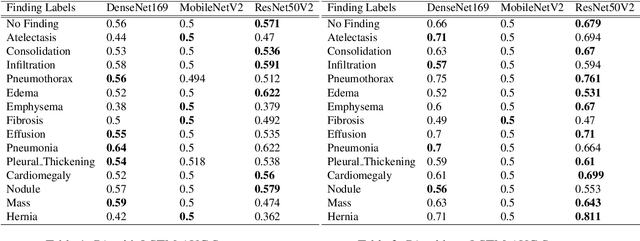
The ability to predict lung and heart based diseases using deep learning techniques is central to many researchers, particularly in the medical field around the world. In this paper, we present a unique outlook of a very familiar problem of disease classification using X-rays. We present a hypothesis that X-rays of patients included with the follow up history of their most recent three chest X-ray images would perform better in disease classification in comparison to one chest X-ray image input using an internal CNN to perform feature extraction. We have discovered that our generic deep learning architecture which we propose for solving this problem performs well with 3 input X ray images provided per sample for each patient. In this paper, we have also established that without additional layers before the output classification, the CNN models will improve the performance of predicting the disease labels for each patient. We have provided our results in ROC curves and AUROC scores. We define a fresh approach of collecting three X-ray images for training deep learning models, which we have concluded has clearly improved the performance of the models. We have shown that ResNet, in general, has a better result than any other CNN model used in the feature extraction phase. With our original approach to data pre-processing, image training, and pre-trained models, we believe that the current research will assist many medical institutions around the world, and this will improve the prediction of patients' symptoms and diagnose them with more accurate cure.
Text Classification for Task-based Source Code Related Questions
Oct 31, 2021There is a key demand to automatically generate code for small tasks for developers. Websites such as StackOverflow provide a simplistic way by offering solutions in small snippets which provide a complete answer to whatever task question the developer wants to code. Natural Language Processing and particularly Question-Answering Systems are very helpful in resolving and working on these tasks. In this paper, we develop a two-fold deep learning model: Seq2Seq and a binary classifier that takes in the intent (which is in natural language) and code snippets in Python. We train both the intent and the code utterances in the Seq2Seq model, where we decided to compare the effect of the hidden layer embedding from the encoder for representing the intent and similarly, using the decoder's hidden layer embeddings for the code sequence. Then we combine both these embeddings and then train a simple binary neural network classifier model for predicting if the intent is correctly answered by the predicted code sequence from the seq2seq model. We find that the hidden state layer's embeddings perform slightly better than regular standard embeddings from a constructed vocabulary. We experimented with our tests on the CoNaLa dataset in addition to the StaQC database consisting of simple task-code snippet-based pairs. We empirically establish that using additional pre-trained embeddings for code snippets in Python is less context-based in comparison to using hidden state context vectors from seq2seq models.
Sentiment Analysis in Drug Reviews using Supervised Machine Learning Algorithms
Mar 21, 2020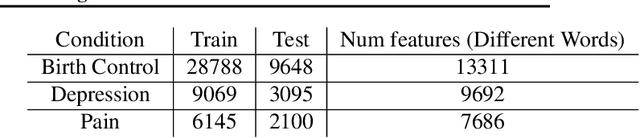
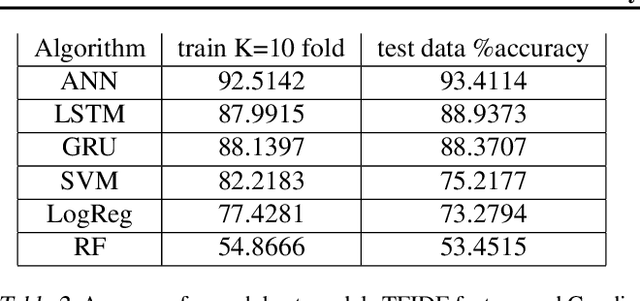
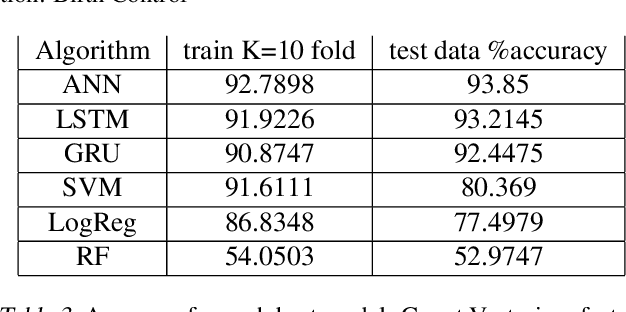

Sentiment Analysis is an important algorithm in Natural Language Processing which is used to detect sentiment within some text. In our project, we had chosen to work on analyzing reviews of various drugs which have been reviewed in form of texts and have also been given a rating on a scale from 1-10. We had obtained this data set from the UCI machine learning repository which had 2 data sets: train and test (split as 75-25\%). We had split the number rating for the drug into three classes in general: positive (7-10), negative (1-4) or neutral(4-7). There are multiple reviews for the drugs that belong to a similar condition and we decided to investigate how the reviews for different conditions use different words impact the ratings of the drugs. Our intention was mainly to implement supervised machine learning classification algorithms that predict the class of the rating using the textual review. We had primarily implemented different embeddings such as Term Frequency Inverse Document Frequency (TFIDF) and the Count Vectors (CV). We had trained models on the most popular conditions such as "Birth Control", "Depression" and "Pain" within the data set and obtained good results while predicting the test data sets.
Fake News Detection with Different Models
Feb 15, 2020This is a paper for exploring various different models aiming at developing fake news detection models and we had used certain machine learning algorithms and we had used pretrained algorithms such as TFIDF and CV and W2V as features for processing textual data.