 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
MSTFormer: Motion Inspired Spatial-temporal Transformer with Dynamic-aware Attention for long-term Vessel Trajectory Prediction
Mar 21, 2023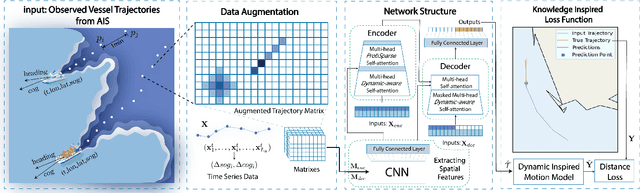

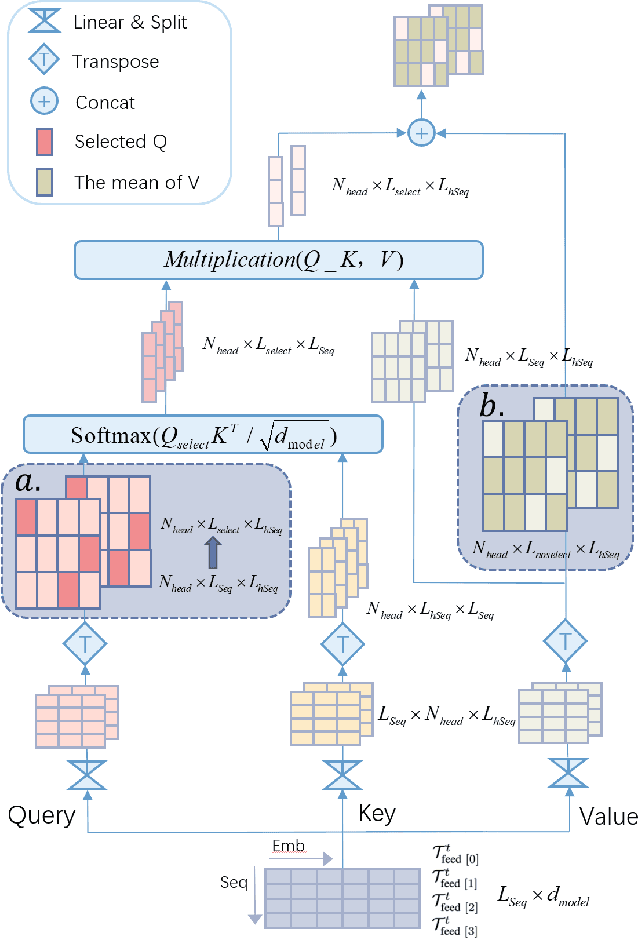
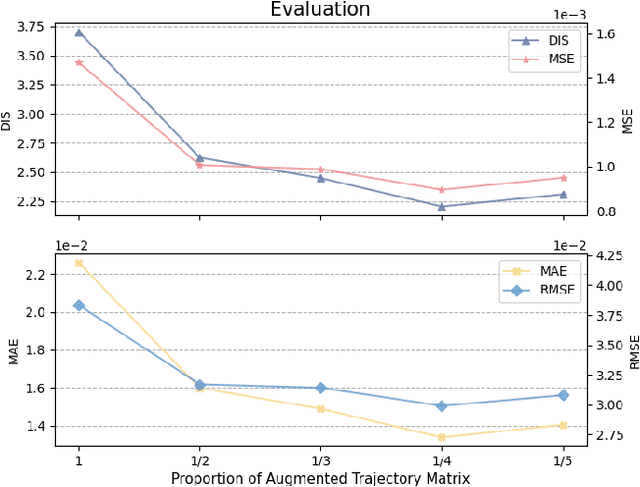
Incorporating the dynamics knowledge into the model is critical for achieving accurate trajectory prediction while considering the spatial and temporal characteristics of the vessel. However, existing methods rarely consider the underlying dynamics knowledge and directly use machine learning algorithms to predict the trajectories. Intuitively, the vessel's motions are following the laws of dynamics, e.g., the speed of a vessel decreases when turning a corner. Yet, it is challenging to combine dynamic knowledge and neural networks due to their inherent heterogeneity. Against this background, we propose MSTFormer, a motion inspired vessel trajectory prediction method based on Transformer. The contribution of this work is threefold. First, we design a data augmentation method to describe the spatial features and motion features of the trajectory. Second, we propose a Multi-headed Dynamic-aware Self-attention mechanism to focus on trajectory points with frequent motion transformations. Finally, we construct a knowledge-inspired loss function to further boost the performance of the model. Experimental results on real-world datasets show that our strategy not only effectively improves long-term predictive capability but also outperforms backbones on cornering data.The ablation analysis further confirms the efficacy of the proposed method. To the best of our knowledge, MSTFormer is the first neural network model for trajectory prediction fused with vessel motion dynamics, providing a worthwhile direction for future research.The source code is available at https://github.com/simple316/MSTFormer.
Word-Free Spoken Language Understanding for Mandarin-Chinese
Jul 01, 2021
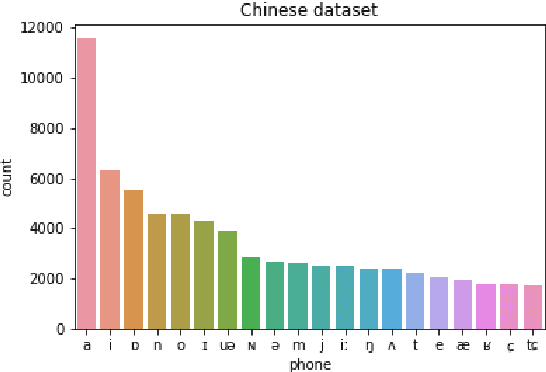
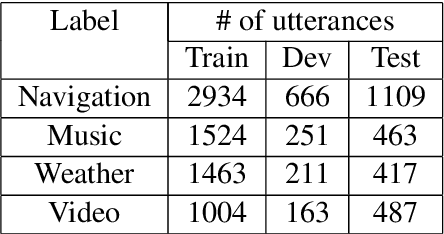
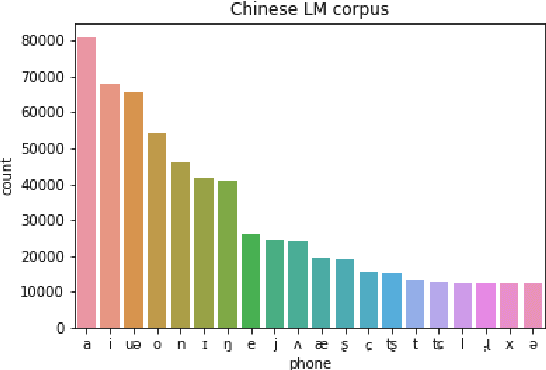
Spoken dialogue systems such as Siri and Alexa provide great convenience to people's everyday life. However, current spoken language understanding (SLU) pipelines largely depend on automatic speech recognition (ASR) modules, which require a large amount of language-specific training data. In this paper, we propose a Transformer-based SLU system that works directly on phones. This acoustic-based SLU system consists of only two blocks and does not require the presence of ASR module. The first block is a universal phone recognition system, and the second block is a Transformer-based language model for phones. We verify the effectiveness of the system on an intent classification dataset in Mandarin Chinese.
Fake News Detection with Different Models
Feb 15, 2020This is a paper for exploring various different models aiming at developing fake news detection models and we had used certain machine learning algorithms and we had used pretrained algorithms such as TFIDF and CV and W2V as features for processing textual data.