 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Nov 06, 2025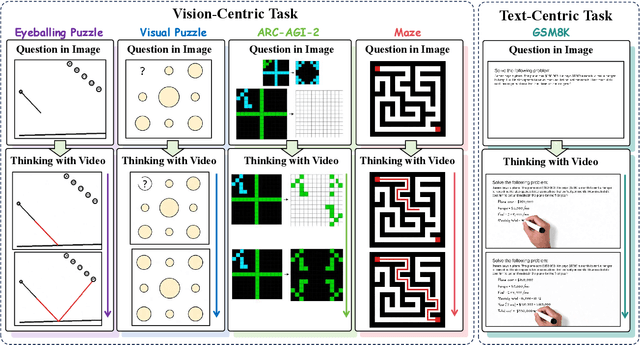
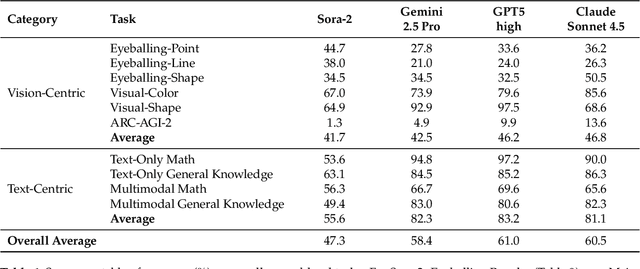
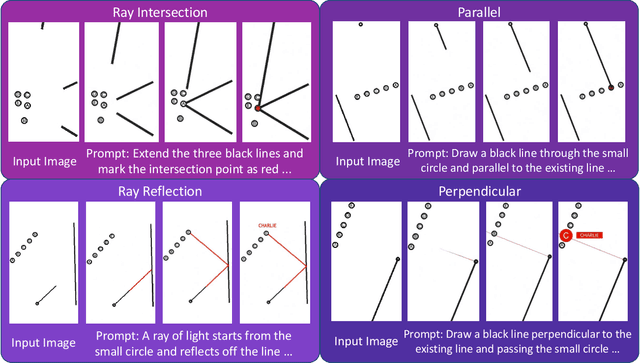
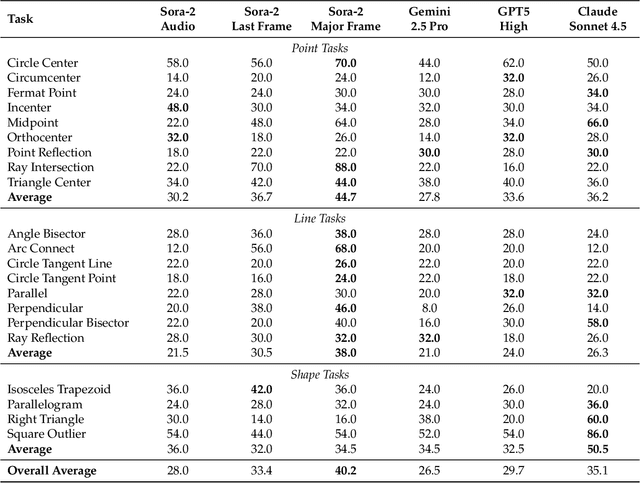
"Thinking with Text" and "Thinking with Images" paradigm significantly improve the reasoning ability of large language models (LLMs) and Vision Language Models (VLMs). However, these paradigms have inherent limitations. (1) Images capture only single moments and fail to represent dynamic processes or continuous changes, and (2) The separation of text and vision as distinct modalities, hindering unified multimodal understanding and generation. To overcome these limitations, we introduce "Thinking with Video", a new paradigm that leverages video generation models, such as Sora-2, to bridge visual and textual reasoning in a unified temporal framework. To support this exploration, we developed the Video Thinking Benchmark (VideoThinkBench). VideoThinkBench encompasses two task categories: (1) vision-centric tasks (e.g., Eyeballing Puzzles), and (2) text-centric tasks (e.g., subsets of GSM8K, MMMU). Our evaluation establishes Sora-2 as a capable reasoner. On vision-centric tasks, Sora-2 is generally comparable to state-of-the-art (SOTA) VLMs, and even surpasses VLMs on several tasks, such as Eyeballing Games. On text-centric tasks, Sora-2 achieves 92% accuracy on MATH, and 75.53% accuracy on MMMU. Furthermore, we systematically analyse the source of these abilities. We also find that self-consistency and in-context learning can improve Sora-2's performance. In summary, our findings demonstrate that the video generation model is the potential unified multimodal understanding and generation model, positions "thinking with video" as a unified multimodal reasoning paradigm.
Code2Logic: Game-Code-Driven Data Synthesis for Enhancing VLMs General Reasoning
May 20, 2025Visual-language Chain-of-Thought (CoT) data resources are relatively scarce compared to text-only counterparts, limiting the improvement of reasoning capabilities in Vision Language Models (VLMs). However, high-quality vision-language reasoning data is expensive and labor-intensive to annotate. To address this issue, we leverage a promising resource: game code, which naturally contains logical structures and state transition processes. Therefore, we propose Code2Logic, a novel game-code-driven approach for multimodal reasoning data synthesis. Our approach leverages Large Language Models (LLMs) to adapt game code, enabling automatic acquisition of reasoning processes and results through code execution. Using the Code2Logic approach, we developed the GameQA dataset to train and evaluate VLMs. GameQA is cost-effective and scalable to produce, challenging for state-of-the-art models, and diverse with 30 games and 158 tasks. Surprisingly, despite training solely on game data, VLMs demonstrated out of domain generalization, specifically Qwen2.5-VL-7B improving performance by 2.33\% across 7 diverse vision-language benchmarks. Our code and dataset are available at https://github.com/tongjingqi/Code2Logic.
RMB: Comprehensively Benchmarking Reward Models in LLM Alignment
Oct 13, 2024



Reward models (RMs) guide the alignment of large language models (LLMs), steering them toward behaviors preferred by humans. Evaluating RMs is the key to better aligning LLMs. However, the current evaluation of RMs may not directly correspond to their alignment performance due to the limited distribution of evaluation data and evaluation methods that are not closely related to alignment objectives. To address these limitations, we propose RMB, a comprehensive RM benchmark that covers over 49 real-world scenarios and includes both pairwise and Best-of-N (BoN) evaluations to better reflect the effectiveness of RMs in guiding alignment optimization. We demonstrate a positive correlation between our benchmark and the downstream alignment task performance. Based on our benchmark, we conduct extensive analysis on the state-of-the-art RMs, revealing their generalization defects that were not discovered by previous benchmarks, and highlighting the potential of generative RMs. Furthermore, we delve into open questions in reward models, specifically examining the effectiveness of majority voting for the evaluation of reward models and analyzing the impact factors of generative RMs, including the influence of evaluation criteria and instructing methods. Our evaluation code and datasets are available at https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark.
Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning
May 05, 2024Human cognition exhibits systematic compositionality, the algebraic ability to generate infinite novel combinations from finite learned components, which is the key to understanding and reasoning about complex logic. In this work, we investigate the compositionality of large language models (LLMs) in mathematical reasoning. Specifically, we construct a new dataset \textsc{MathTrap}\footnotemark[3] by introducing carefully designed logical traps into the problem descriptions of MATH and GSM8k. Since problems with logical flaws are quite rare in the real world, these represent ``unseen'' cases to LLMs. Solving these requires the models to systematically compose (1) the mathematical knowledge involved in the original problems with (2) knowledge related to the introduced traps. Our experiments show that while LLMs possess both components of requisite knowledge, they do not \textbf{spontaneously} combine them to handle these novel cases. We explore several methods to mitigate this deficiency, such as natural language prompts, few-shot demonstrations, and fine-tuning. We find that LLMs' performance can be \textbf{passively} improved through the above external intervention. Overall, systematic compositionality remains an open challenge for large language models.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.