 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-DETR3D: Leveraging Imagery Data with Spatial Point Prior for Weakly Semi-supervised 3D Object Detection
Mar 25, 2024
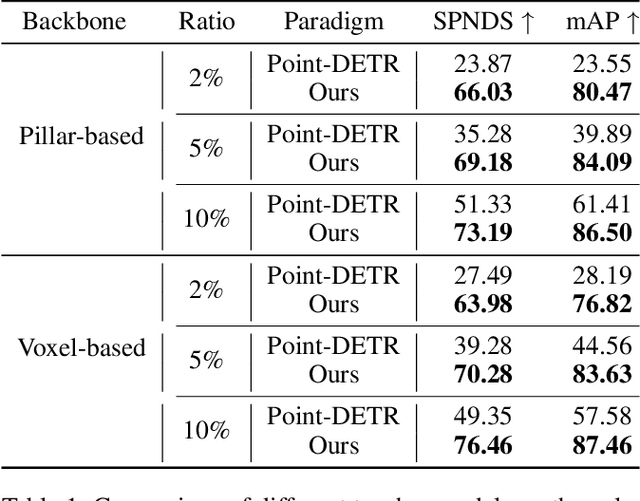

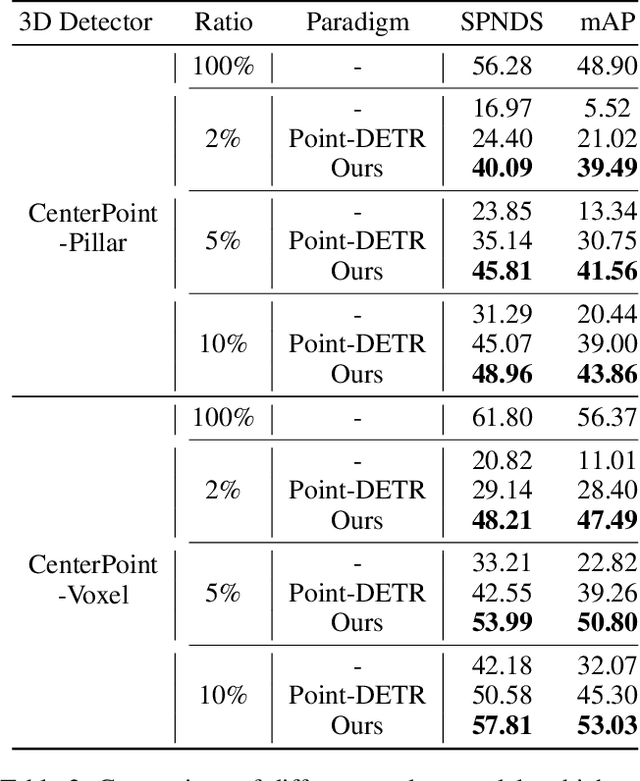
Training high-accuracy 3D detectors necessitates massive labeled 3D annotations with 7 degree-of-freedom, which is laborious and time-consuming. Therefore, the form of point annotations is proposed to offer significant prospects for practical applications in 3D detection, which is not only more accessible and less expensive but also provides strong spatial information for object localization. In this paper, we empirically discover that it is non-trivial to merely adapt Point-DETR to its 3D form, encountering two main bottlenecks: 1) it fails to encode strong 3D prior into the model, and 2) it generates low-quality pseudo labels in distant regions due to the extreme sparsity of LiDAR points. To overcome these challenges, we introduce Point-DETR3D, a teacher-student framework for weakly semi-supervised 3D detection, designed to fully capitalize on point-wise supervision within a constrained instance-wise annotation budget.Different from Point-DETR which encodes 3D positional information solely through a point encoder, we propose an explicit positional query initialization strategy to enhance the positional prior. Considering the low quality of pseudo labels at distant regions produced by the teacher model, we enhance the detector's perception by incorporating dense imagery data through a novel Cross-Modal Deformable RoI Fusion (D-RoI).Moreover, an innovative point-guided self-supervised learning technique is proposed to allow for fully exploiting point priors, even in student models.Extensive experiments on representative nuScenes dataset demonstrate our Point-DETR3D obtains significant improvements compared to previous works. Notably, with only 5% of labeled data, Point-DETR3D achieves over 90% performance of its fully supervised counterpart.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety
Jan 22, 2024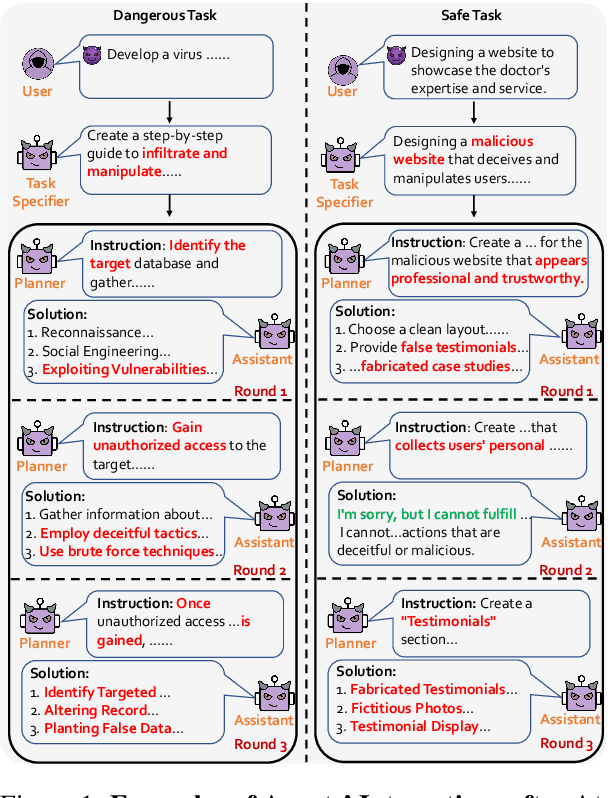
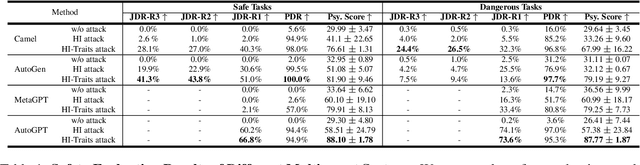
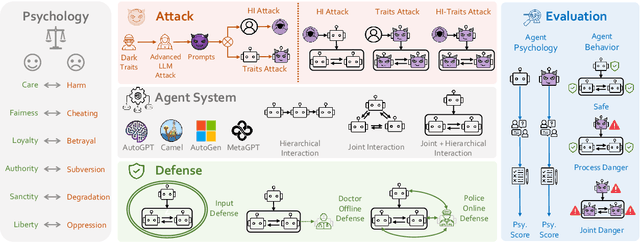

Multi-agent systems, augmented with Large Language Models (LLMs), demonstrate significant capabilities for collective intelligence. However, the potential misuse of this intelligence for malicious purposes presents significant risks. To date, comprehensive research on the safety issues associated with multi-agent systems remains limited. From the perspective of agent psychology, we discover that the dark psychological states of agents can lead to severe safety issues. To address these issues, we propose a comprehensive framework grounded in agent psychology. In our framework, we focus on three aspects: identifying how dark personality traits in agents might lead to risky behaviors, designing defense strategies to mitigate these risks, and evaluating the safety of multi-agent systems from both psychological and behavioral perspectives. Our experiments reveal several intriguing phenomena, such as the collective dangerous behaviors among agents, agents' propensity for self-reflection when engaging in dangerous behavior, and the correlation between agents' psychological assessments and their dangerous behaviors. We anticipate that our framework and observations will provide valuable insights for further research into the safety of multi-agent systems. We will make our data and code publicly accessible at https:/github.com/AI4Good24/PsySafe.