 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink3D: Thinking with Space for Spatial Reasoning
Jan 19, 2026Understanding and reasoning about the physical world requires spatial intelligence: the ability to interpret geometry, perspective, and spatial relations beyond 2D perception. While recent vision large models (VLMs) excel at visual understanding, they remain fundamentally 2D perceivers and struggle with genuine 3D reasoning. We introduce Think3D, a framework that enables VLM agents to think with 3D space. By leveraging 3D reconstruction models that recover point clouds and camera poses from images or videos, Think3D allows the agent to actively manipulate space through camera-based operations and ego/global-view switching, transforming spatial reasoning into an interactive 3D chain-of-thought process. Without additional training, Think3D significantly improves the spatial reasoning performance of advanced models such as GPT-4.1 and Gemini 2.5 Pro, yielding average gains of +7.8% on BLINK Multi-view and MindCube, and +4.7% on VSI-Bench. We further show that smaller models, which struggle with spatial exploration, benefit significantly from a reinforcement learning policy that enables the model to select informative viewpoints and operations. With RL, the benefit from tool usage increases from +0.7% to +6.8%. Our findings demonstrate that training-free, tool-augmented spatial exploration is a viable path toward more flexible and human-like 3D reasoning in multimodal agents, establishing a new dimension of multimodal intelligence. Code and weights are released at https://github.com/zhangzaibin/spagent.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024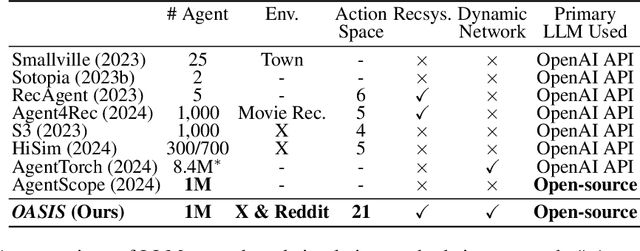
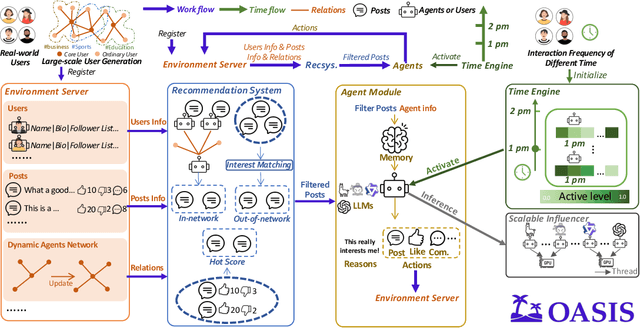

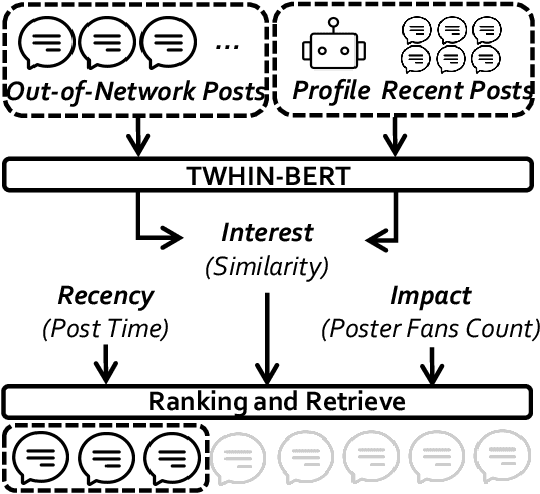
There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
AD-H: Autonomous Driving with Hierarchical Agents
Jun 05, 2024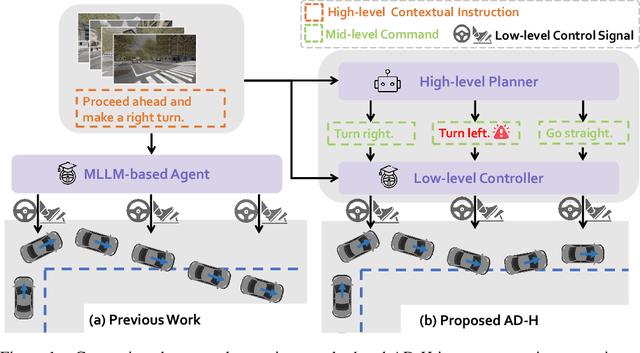

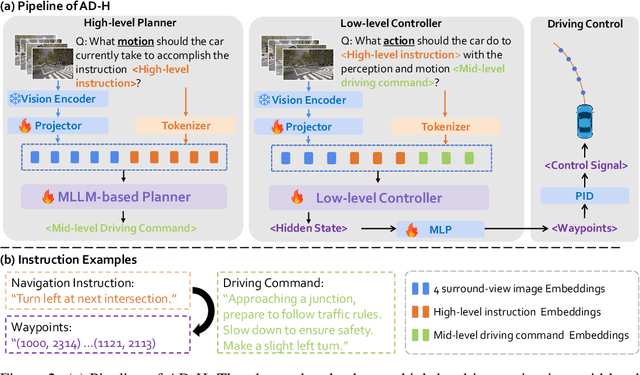

Due to the impressive capabilities of multimodal large language models (MLLMs), recent works have focused on employing MLLM-based agents for autonomous driving in large-scale and dynamic environments. However, prevalent approaches often directly translate high-level instructions into low-level vehicle control signals, which deviates from the inherent language generation paradigm of MLLMs and fails to fully harness their emergent powers. As a result, the generalizability of these methods is highly restricted by autonomous driving datasets used during fine-tuning. To tackle this challenge, we propose to connect high-level instructions and low-level control signals with mid-level language-driven commands, which are more fine-grained than high-level instructions but more universal and explainable than control signals, and thus can effectively bridge the gap in between. We implement this idea through a hierarchical multi-agent driving system named AD-H, including a MLLM planner for high-level reasoning and a lightweight controller for low-level execution. The hierarchical design liberates the MLLM from low-level control signal decoding and therefore fully releases their emergent capability in high-level perception, reasoning, and planning. We build a new dataset with action hierarchy annotations. Comprehensive closed-loop evaluations demonstrate several key advantages of our proposed AD-H system. First, AD-H can notably outperform state-of-the-art methods in achieving exceptional driving performance, even exhibiting self-correction capabilities during vehicle operation, a scenario not encountered in the training dataset. Second, AD-H demonstrates superior generalization under long-horizon instructions and novel environmental conditions, significantly surpassing current state-of-the-art methods. We will make our data and code publicly accessible at https://github.com/zhangzaibin/AD-H
Assessment of Multimodal Large Language Models in Alignment with Human Values
Mar 26, 2024



Large Language Models (LLMs) aim to serve as versatile assistants aligned with human values, as defined by the principles of being helpful, honest, and harmless (hhh). However, in terms of Multimodal Large Language Models (MLLMs), despite their commendable performance in perception and reasoning tasks, their alignment with human values remains largely unexplored, given the complexity of defining hhh dimensions in the visual world and the difficulty in collecting relevant data that accurately mirrors real-world situations. To address this gap, we introduce Ch3Ef, a Compreh3ensive Evaluation dataset and strategy for assessing alignment with human expectations. Ch3Ef dataset contains 1002 human-annotated data samples, covering 12 domains and 46 tasks based on the hhh principle. We also present a unified evaluation strategy supporting assessment across various scenarios and different perspectives. Based on the evaluation results, we summarize over 10 key findings that deepen the understanding of MLLM capabilities, limitations, and the dynamic relationships between evaluation levels, guiding future advancements in the field.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety
Jan 22, 2024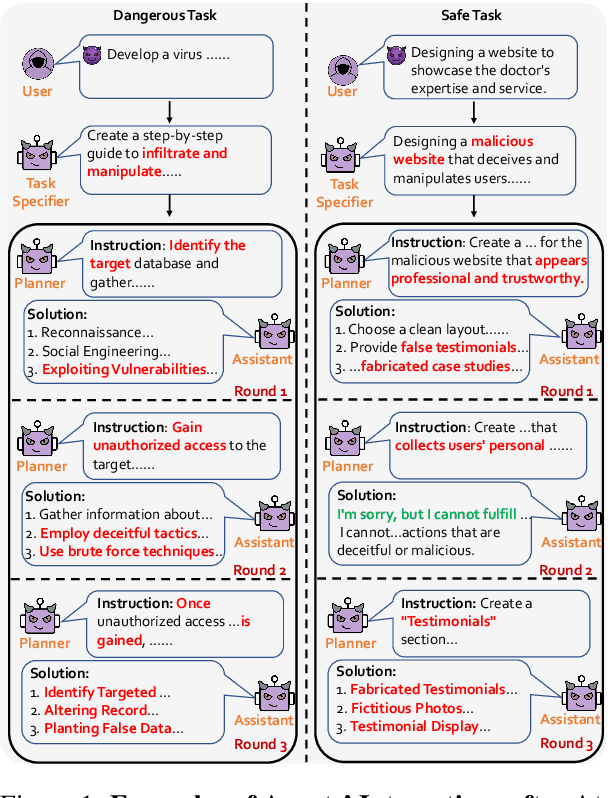
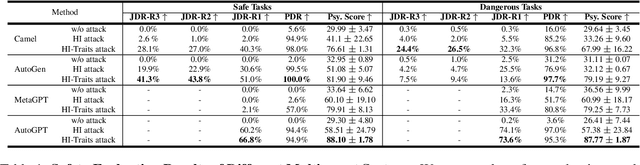
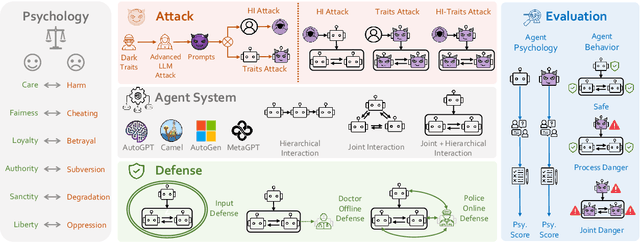

Multi-agent systems, augmented with Large Language Models (LLMs), demonstrate significant capabilities for collective intelligence. However, the potential misuse of this intelligence for malicious purposes presents significant risks. To date, comprehensive research on the safety issues associated with multi-agent systems remains limited. From the perspective of agent psychology, we discover that the dark psychological states of agents can lead to severe safety issues. To address these issues, we propose a comprehensive framework grounded in agent psychology. In our framework, we focus on three aspects: identifying how dark personality traits in agents might lead to risky behaviors, designing defense strategies to mitigate these risks, and evaluating the safety of multi-agent systems from both psychological and behavioral perspectives. Our experiments reveal several intriguing phenomena, such as the collective dangerous behaviors among agents, agents' propensity for self-reflection when engaging in dangerous behavior, and the correlation between agents' psychological assessments and their dangerous behaviors. We anticipate that our framework and observations will provide valuable insights for further research into the safety of multi-agent systems. We will make our data and code publicly accessible at https:/github.com/AI4Good24/PsySafe.
BEV-IO: Enhancing Bird's-Eye-View 3D Detection with Instance Occupancy
May 26, 2023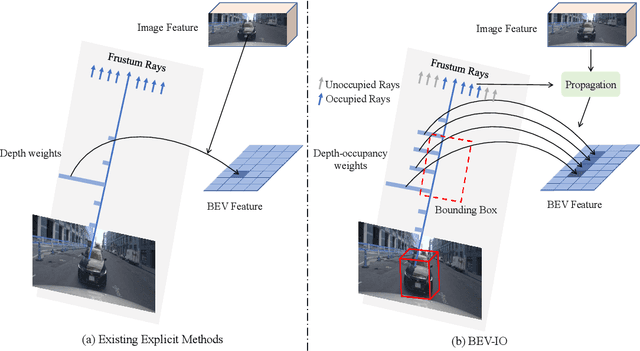
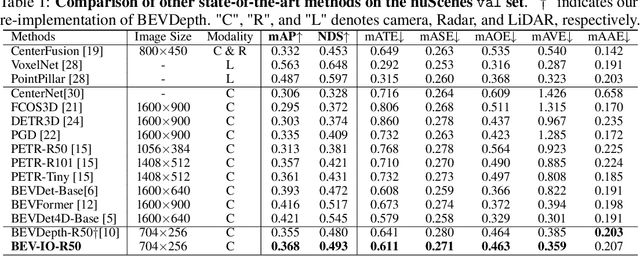
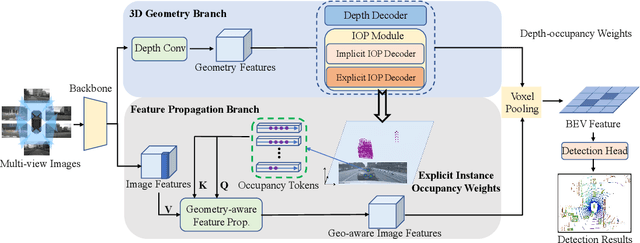

A popular approach for constructing bird's-eye-view (BEV) representation in 3D detection is to lift 2D image features onto the viewing frustum space based on explicitly predicted depth distribution. However, depth distribution can only characterize the 3D geometry of visible object surfaces but fails to capture their internal space and overall geometric structure, leading to sparse and unsatisfactory 3D representations. To mitigate this issue, we present BEV-IO, a new 3D detection paradigm to enhance BEV representation with instance occupancy information. At the core of our method is the newly-designed instance occupancy prediction (IOP) module, which aims to infer point-level occupancy status for each instance in the frustum space. To ensure training efficiency while maintaining representational flexibility, it is trained using the combination of both explicit and implicit supervision. With the predicted occupancy, we further design a geometry-aware feature propagation mechanism (GFP), which performs self-attention based on occupancy distribution along each ray in frustum and is able to enforce instance-level feature consistency. By integrating the IOP module with GFP mechanism, our BEV-IO detector is able to render highly informative 3D scene structures with more comprehensive BEV representations. Experimental results demonstrate that BEV-IO can outperform state-of-the-art methods while only adding a negligible increase in parameters (0.2%) and computational overhead (0.24%in GFLOPs).