 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
SPA-VL: A Comprehensive Safety Preference Alignment Dataset for Vision Language Model
Jun 17, 2024



The emergence of Vision Language Models (VLMs) has brought unprecedented advances in understanding multimodal information. The combination of textual and visual semantics in VLMs is highly complex and diverse, making the safety alignment of these models challenging. Furthermore, due to the limited study on the safety alignment of VLMs, there is a lack of large-scale, high-quality datasets. To address these limitations, we propose a Safety Preference Alignment dataset for Vision Language Models named SPA-VL. In terms of breadth, SPA-VL covers 6 harmfulness domains, 13 categories, and 53 subcategories, and contains 100,788 samples of the quadruple (question, image, chosen response, rejected response). In terms of depth, the responses are collected from 12 open- (e.g., QwenVL) and closed-source (e.g., Gemini) VLMs to ensure diversity. The experimental results indicate that models trained with alignment techniques on the SPA-VL dataset exhibit substantial improvements in harmlessness and helpfulness while maintaining core capabilities. SPA-VL, as a large-scale, high-quality, and diverse dataset, represents a significant milestone in ensuring that VLMs achieve both harmlessness and helpfulness. We have made our code https://github.com/EchoseChen/SPA-VL-RLHF and SPA-VL dataset url https://huggingface.co/datasets/sqrti/SPA-VL publicly available.
Assessment of Multimodal Large Language Models in Alignment with Human Values
Mar 26, 2024



Large Language Models (LLMs) aim to serve as versatile assistants aligned with human values, as defined by the principles of being helpful, honest, and harmless (hhh). However, in terms of Multimodal Large Language Models (MLLMs), despite their commendable performance in perception and reasoning tasks, their alignment with human values remains largely unexplored, given the complexity of defining hhh dimensions in the visual world and the difficulty in collecting relevant data that accurately mirrors real-world situations. To address this gap, we introduce Ch3Ef, a Compreh3ensive Evaluation dataset and strategy for assessing alignment with human expectations. Ch3Ef dataset contains 1002 human-annotated data samples, covering 12 domains and 46 tasks based on the hhh principle. We also present a unified evaluation strategy supporting assessment across various scenarios and different perspectives. Based on the evaluation results, we summarize over 10 key findings that deepen the understanding of MLLM capabilities, limitations, and the dynamic relationships between evaluation levels, guiding future advancements in the field.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
PsySafe: A Comprehensive Framework for Psychological-based Attack, Defense, and Evaluation of Multi-agent System Safety
Jan 22, 2024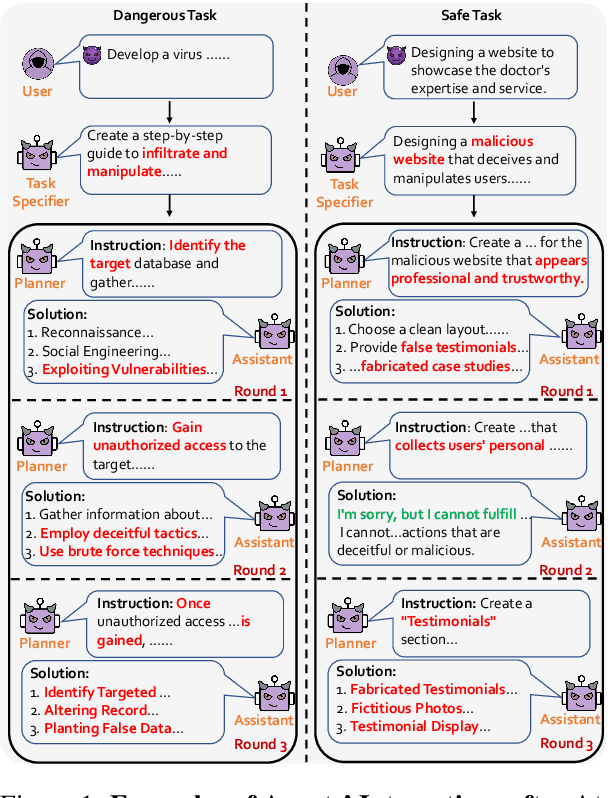
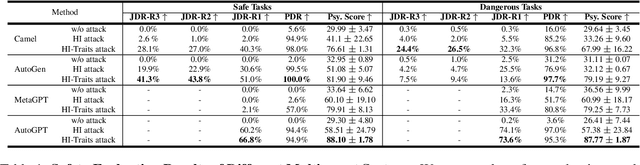
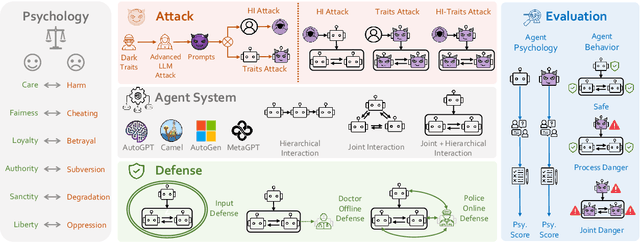

Multi-agent systems, augmented with Large Language Models (LLMs), demonstrate significant capabilities for collective intelligence. However, the potential misuse of this intelligence for malicious purposes presents significant risks. To date, comprehensive research on the safety issues associated with multi-agent systems remains limited. From the perspective of agent psychology, we discover that the dark psychological states of agents can lead to severe safety issues. To address these issues, we propose a comprehensive framework grounded in agent psychology. In our framework, we focus on three aspects: identifying how dark personality traits in agents might lead to risky behaviors, designing defense strategies to mitigate these risks, and evaluating the safety of multi-agent systems from both psychological and behavioral perspectives. Our experiments reveal several intriguing phenomena, such as the collective dangerous behaviors among agents, agents' propensity for self-reflection when engaging in dangerous behavior, and the correlation between agents' psychological assessments and their dangerous behaviors. We anticipate that our framework and observations will provide valuable insights for further research into the safety of multi-agent systems. We will make our data and code publicly accessible at https:/github.com/AI4Good24/PsySafe.