 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Driven Amodal Completion: Collaborative Agents and Perceptual Evaluation
Dec 24, 2025

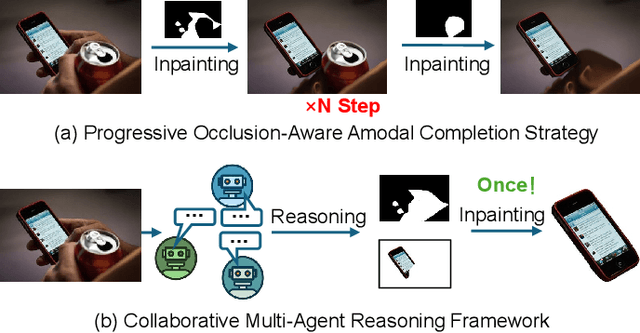

Amodal completion, the task of inferring invisible object parts, faces significant challenges in maintaining semantic consistency and structural integrity. Prior progressive approaches are inherently limited by inference instability and error accumulation. To tackle these limitations, we present a Collaborative Multi-Agent Reasoning Framework that explicitly decouples Semantic Planning from Visual Synthesis. By employing specialized agents for upfront reasoning, our method generates a structured, explicit plan before pixel generation, enabling visually and semantically coherent single-pass synthesis. We integrate this framework with two critical mechanisms: (1) a self-correcting Verification Agent that employs Chain-of-Thought reasoning to rectify visible region segmentation and identify residual occluders strictly within the Semantic Planning phase, and (2) a Diverse Hypothesis Generator that addresses the ambiguity of invisible regions by offering diverse, plausible semantic interpretations, surpassing the limited pixel-level variations of standard random seed sampling. Furthermore, addressing the limitations of traditional metrics in assessing inferred invisible content, we introduce the MAC-Score (MLLM Amodal Completion Score), a novel human-aligned evaluation metric. Validated against human judgment and ground truth, these metrics establish a robust standard for assessing structural completeness and semantic consistency with visible context. Extensive experiments demonstrate that our framework significantly outperforms state-of-the-art methods across multiple datasets. Our project is available at: https://fanhongxing.github.io/remac-page.
InterMoE: Individual-Specific 3D Human Interaction Generation via Dynamic Temporal-Selective MoE
Nov 17, 2025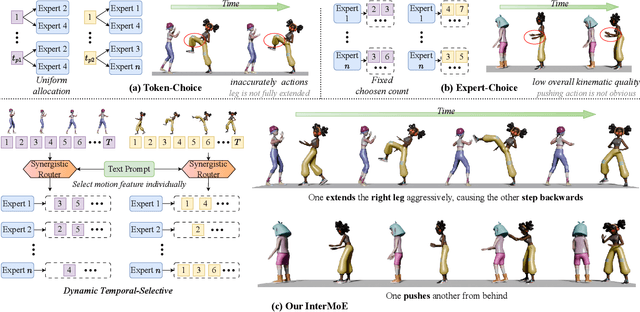
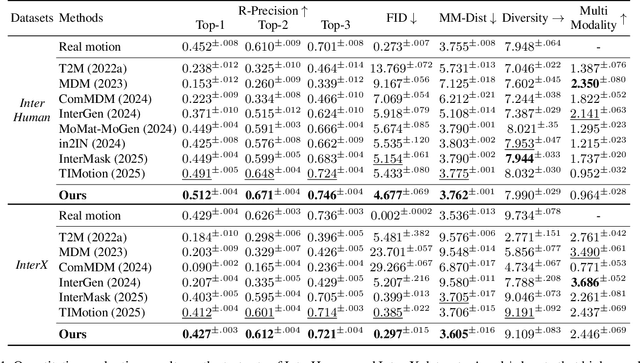
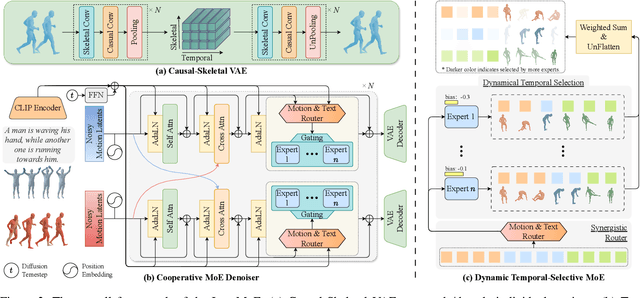
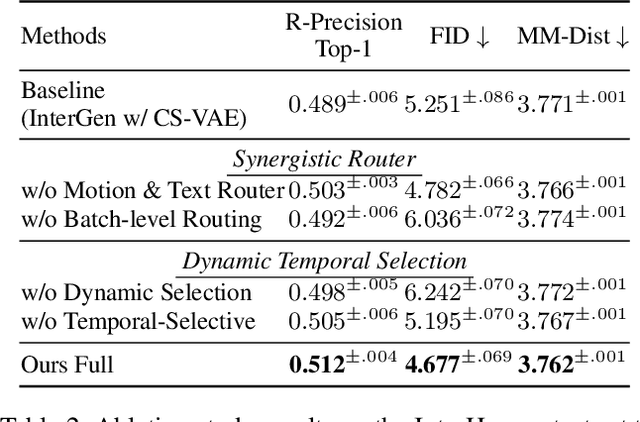
Generating high-quality human interactions holds significant value for applications like virtual reality and robotics. However, existing methods often fail to preserve unique individual characteristics or fully adhere to textual descriptions. To address these challenges, we introduce InterMoE, a novel framework built on a Dynamic Temporal-Selective Mixture of Experts. The core of InterMoE is a routing mechanism that synergistically uses both high-level text semantics and low-level motion context to dispatch temporal motion features to specialized experts. This allows experts to dynamically determine the selection capacity and focus on critical temporal features, thereby preserving specific individual characteristic identities while ensuring high semantic fidelity. Extensive experiments show that InterMoE achieves state-of-the-art performance in individual-specific high-fidelity 3D human interaction generation, reducing FID scores by 9% on the InterHuman dataset and 22% on InterX.
From Parts to Whole: A Unified Reference Framework for Controllable Human Image Generation
Apr 23, 2024Recent advancements in controllable human image generation have led to zero-shot generation using structural signals (e.g., pose, depth) or facial appearance. Yet, generating human images conditioned on multiple parts of human appearance remains challenging. Addressing this, we introduce Parts2Whole, a novel framework designed for generating customized portraits from multiple reference images, including pose images and various aspects of human appearance. To achieve this, we first develop a semantic-aware appearance encoder to retain details of different human parts, which processes each image based on its textual label to a series of multi-scale feature maps rather than one image token, preserving the image dimension. Second, our framework supports multi-image conditioned generation through a shared self-attention mechanism that operates across reference and target features during the diffusion process. We enhance the vanilla attention mechanism by incorporating mask information from the reference human images, allowing for the precise selection of any part. Extensive experiments demonstrate the superiority of our approach over existing alternatives, offering advanced capabilities for multi-part controllable human image customization. See our project page at https://huanngzh.github.io/Parts2Whole/.
Assessment of Multimodal Large Language Models in Alignment with Human Values
Mar 26, 2024



Large Language Models (LLMs) aim to serve as versatile assistants aligned with human values, as defined by the principles of being helpful, honest, and harmless (hhh). However, in terms of Multimodal Large Language Models (MLLMs), despite their commendable performance in perception and reasoning tasks, their alignment with human values remains largely unexplored, given the complexity of defining hhh dimensions in the visual world and the difficulty in collecting relevant data that accurately mirrors real-world situations. To address this gap, we introduce Ch3Ef, a Compreh3ensive Evaluation dataset and strategy for assessing alignment with human expectations. Ch3Ef dataset contains 1002 human-annotated data samples, covering 12 domains and 46 tasks based on the hhh principle. We also present a unified evaluation strategy supporting assessment across various scenarios and different perspectives. Based on the evaluation results, we summarize over 10 key findings that deepen the understanding of MLLM capabilities, limitations, and the dynamic relationships between evaluation levels, guiding future advancements in the field.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models
Nov 05, 2023Multimodal Large Language Models (MLLMs) have shown impressive abilities in interacting with visual content with myriad potential downstream tasks. However, even though a list of benchmarks has been proposed, the capabilities and limitations of MLLMs are still not comprehensively understood, due to a lack of a standardized and holistic evaluation framework. To this end, we present the first Comprehensive Evaluation Framework (ChEF) that can holistically profile each MLLM and fairly compare different MLLMs. First, we structure ChEF as four modular components, i.e., Scenario as scalable multimodal datasets, Instruction as flexible instruction retrieving formulae, Inferencer as reliable question answering strategies, and Metric as indicative task-specific score functions. Based on them, ChEF facilitates versatile evaluations in a standardized framework, and new evaluations can be built by designing new Recipes (systematic selection of these four components). Notably, current MLLM benchmarks can be readily summarized as recipes of ChEF. Second, we introduce 6 new recipes to quantify competent MLLMs' desired capabilities (or called desiderata, i.e., calibration, in-context learning, instruction following, language performance, hallucination, and robustness) as reliable agents that can perform real-world multimodal interactions. Third, we conduct a large-scale evaluation of 9 prominent MLLMs on 9 scenarios and 6 desiderata. Our evaluation summarized over 20 valuable observations concerning the generalizability of MLLMs across various scenarios and the composite capability of MLLMs required for multimodal interactions. We will publicly release all the detailed implementations for further analysis, as well as an easy-to-use modular toolkit for the integration of new recipes and models, so that ChEF can be a growing evaluation framework for the MLLM community.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021



This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.
Exploring Adversarial Fake Images on Face Manifold
Jan 09, 2021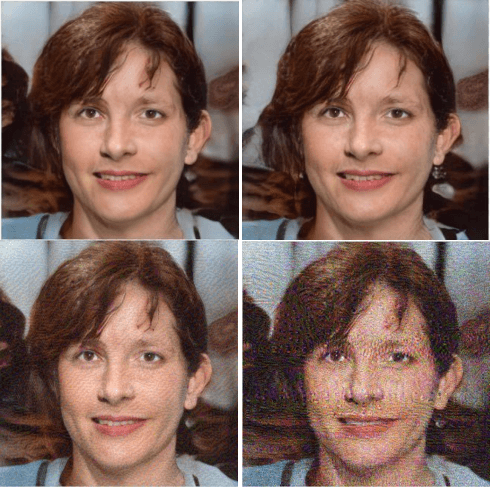
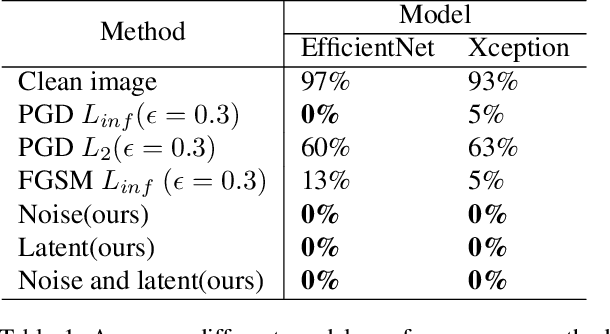
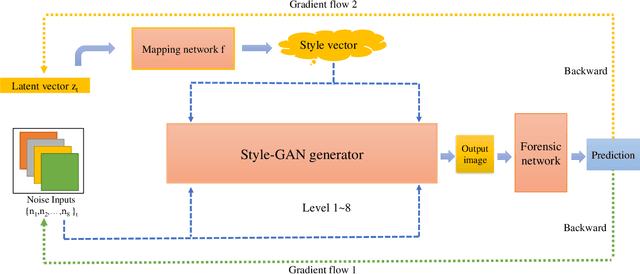
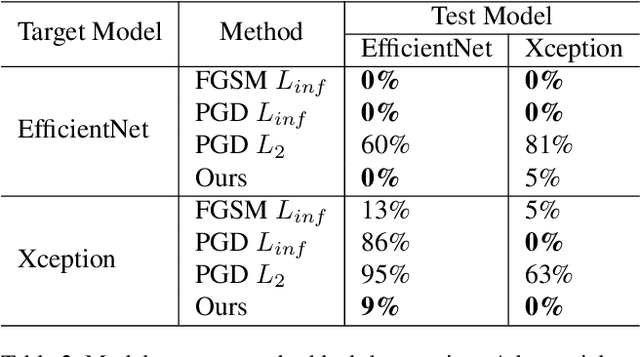
Images synthesized by powerful generative adversarial network (GAN) based methods have drawn moral and privacy concerns. Although image forensic models have reached great performance in detecting fake images from real ones, these models can be easily fooled with a simple adversarial attack. But, the noise adding adversarial samples are also arousing suspicion. In this paper, instead of adding adversarial noise, we optimally search adversarial points on face manifold to generate anti-forensic fake face images. We iteratively do a gradient-descent with each small step in the latent space of a generative model, e.g. Style-GAN, to find an adversarial latent vector, which is similar to norm-based adversarial attack but in latent space. Then, the generated fake images driven by the adversarial latent vectors with the help of GANs can defeat main-stream forensic models. For examples, they make the accuracy of deepfake detection models based on Xception or EfficientNet drop from over 90% to nearly 0%, meanwhile maintaining high visual quality. In addition, we find manipulating style vector $z$ or noise vectors $n$ at different levels have impacts on attack success rate. The generated adversarial images mainly have facial texture or face attributes changing.