 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topic-level Self-Correctional Approach to Mitigate Hallucinations in MLLMs
Nov 26, 2024



Aligning the behaviors of Multimodal Large Language Models (MLLMs) with human preferences is crucial for developing robust and trustworthy AI systems. While recent attempts have employed human experts or powerful auxiliary AI systems to provide more accurate preference feedback, such as determining the preferable responses from MLLMs or directly rewriting hallucination-free responses, extensive resource overhead compromise the scalability of the feedback collection. In this work, we introduce Topic-level Preference Overwriting (TPO), a self-correctional approach that guide the model itself to mitigate its own hallucination at the topic level. Through a deconfounded strategy that replaces each topic within the response with the best or worst alternatives generated by the model itself, TPO creates more contrasting pairwise preference feedback, enhancing the feedback quality without human or proprietary model intervention. Notably, the experimental results demonstrate proposed TPO achieves state-of-the-art performance in trustworthiness, significantly reducing the object hallucinations by 92% and overall hallucinations by 38%. Code, model and data will be released.
WorldSimBench: Towards Video Generation Models as World Simulators
Oct 23, 2024



Recent advancements in predictive models have demonstrated exceptional capabilities in predicting the future state of objects and scenes. However, the lack of categorization based on inherent characteristics continues to hinder the progress of predictive model development. Additionally, existing benchmarks are unable to effectively evaluate higher-capability, highly embodied predictive models from an embodied perspective. In this work, we classify the functionalities of predictive models into a hierarchy and take the first step in evaluating World Simulators by proposing a dual evaluation framework called WorldSimBench. WorldSimBench includes Explicit Perceptual Evaluation and Implicit Manipulative Evaluation, encompassing human preference assessments from the visual perspective and action-level evaluations in embodied tasks, covering three representative embodied scenarios: Open-Ended Embodied Environment, Autonomous, Driving, and Robot Manipulation. In the Explicit Perceptual Evaluation, we introduce the HF-Embodied Dataset, a video assessment dataset based on fine-grained human feedback, which we use to train a Human Preference Evaluator that aligns with human perception and explicitly assesses the visual fidelity of World Simulators. In the Implicit Manipulative Evaluation, we assess the video-action consistency of World Simulators by evaluating whether the generated situation-aware video can be accurately translated into the correct control signals in dynamic environments. Our comprehensive evaluation offers key insights that can drive further innovation in video generation models, positioning World Simulators as a pivotal advancement toward embodied artificial intelligence.
RH20T-P: A Primitive-Level Robotic Dataset Towards Composable Generalization Agents
Mar 28, 2024



The ultimate goals of robotic learning is to acquire a comprehensive and generalizable robotic system capable of performing both seen skills within the training distribution and unseen skills in novel environments. Recent progress in utilizing language models as high-level planners has demonstrated that the complexity of tasks can be reduced through decomposing them into primitive-level plans, making it possible to generalize on novel robotic tasks in a composable manner. Despite the promising future, the community is not yet adequately prepared for composable generalization agents, particularly due to the lack of primitive-level real-world robotic datasets. In this paper, we propose a primitive-level robotic dataset, namely RH20T-P, which contains about 33000 video clips covering 44 diverse and complicated robotic tasks. Each clip is manually annotated according to a set of meticulously designed primitive skills, facilitating the future development of composable generalization agents. To validate the effectiveness of RH20T-P, we also construct a potential and scalable agent based on RH20T-P, called RA-P. Equipped with two planners specialized in task decomposition and motion planning, RA-P can adapt to novel physical skills through composable generalization. Our website and videos can be found at https://sites.google.com/view/rh20t-primitive/main. Dataset and code will be made available soon.
Assessment of Multimodal Large Language Models in Alignment with Human Values
Mar 26, 2024



Large Language Models (LLMs) aim to serve as versatile assistants aligned with human values, as defined by the principles of being helpful, honest, and harmless (hhh). However, in terms of Multimodal Large Language Models (MLLMs), despite their commendable performance in perception and reasoning tasks, their alignment with human values remains largely unexplored, given the complexity of defining hhh dimensions in the visual world and the difficulty in collecting relevant data that accurately mirrors real-world situations. To address this gap, we introduce Ch3Ef, a Compreh3ensive Evaluation dataset and strategy for assessing alignment with human expectations. Ch3Ef dataset contains 1002 human-annotated data samples, covering 12 domains and 46 tasks based on the hhh principle. We also present a unified evaluation strategy supporting assessment across various scenarios and different perspectives. Based on the evaluation results, we summarize over 10 key findings that deepen the understanding of MLLM capabilities, limitations, and the dynamic relationships between evaluation levels, guiding future advancements in the field.
From GPT-4 to Gemini and Beyond: Assessing the Landscape of MLLMs on Generalizability, Trustworthiness and Causality through Four Modalities
Jan 29, 2024



Multi-modal Large Language Models (MLLMs) have shown impressive abilities in generating reasonable responses with respect to multi-modal contents. However, there is still a wide gap between the performance of recent MLLM-based applications and the expectation of the broad public, even though the most powerful OpenAI's GPT-4 and Google's Gemini have been deployed. This paper strives to enhance understanding of the gap through the lens of a qualitative study on the generalizability, trustworthiness, and causal reasoning capabilities of recent proprietary and open-source MLLMs across four modalities: ie, text, code, image, and video, ultimately aiming to improve the transparency of MLLMs. We believe these properties are several representative factors that define the reliability of MLLMs, in supporting various downstream applications. To be specific, we evaluate the closed-source GPT-4 and Gemini and 6 open-source LLMs and MLLMs. Overall we evaluate 230 manually designed cases, where the qualitative results are then summarized into 12 scores (ie, 4 modalities times 3 properties). In total, we uncover 14 empirical findings that are useful to understand the capabilities and limitations of both proprietary and open-source MLLMs, towards more reliable downstream multi-modal applications.
ChEF: A Comprehensive Evaluation Framework for Standardized Assessment of Multimodal Large Language Models
Nov 05, 2023Multimodal Large Language Models (MLLMs) have shown impressive abilities in interacting with visual content with myriad potential downstream tasks. However, even though a list of benchmarks has been proposed, the capabilities and limitations of MLLMs are still not comprehensively understood, due to a lack of a standardized and holistic evaluation framework. To this end, we present the first Comprehensive Evaluation Framework (ChEF) that can holistically profile each MLLM and fairly compare different MLLMs. First, we structure ChEF as four modular components, i.e., Scenario as scalable multimodal datasets, Instruction as flexible instruction retrieving formulae, Inferencer as reliable question answering strategies, and Metric as indicative task-specific score functions. Based on them, ChEF facilitates versatile evaluations in a standardized framework, and new evaluations can be built by designing new Recipes (systematic selection of these four components). Notably, current MLLM benchmarks can be readily summarized as recipes of ChEF. Second, we introduce 6 new recipes to quantify competent MLLMs' desired capabilities (or called desiderata, i.e., calibration, in-context learning, instruction following, language performance, hallucination, and robustness) as reliable agents that can perform real-world multimodal interactions. Third, we conduct a large-scale evaluation of 9 prominent MLLMs on 9 scenarios and 6 desiderata. Our evaluation summarized over 20 valuable observations concerning the generalizability of MLLMs across various scenarios and the composite capability of MLLMs required for multimodal interactions. We will publicly release all the detailed implementations for further analysis, as well as an easy-to-use modular toolkit for the integration of new recipes and models, so that ChEF can be a growing evaluation framework for the MLLM community.
LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
Jun 18, 2023
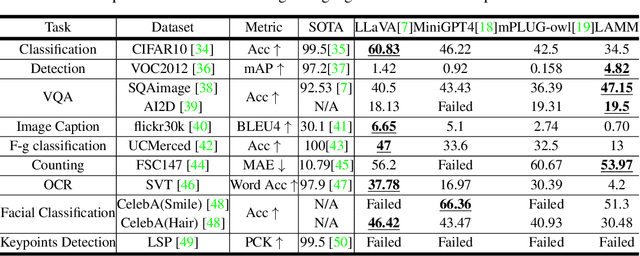
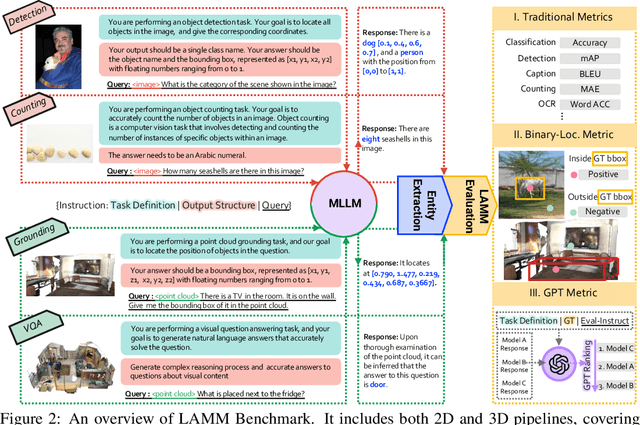
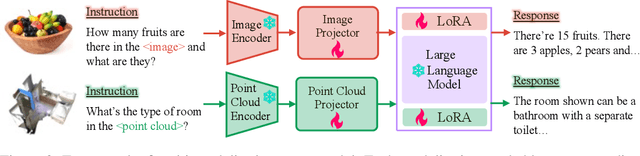
Large language models have become a potential pathway toward achieving artificial general intelligence. Recent works on multi-modal large language models have demonstrated their effectiveness in handling visual modalities. In this work, we extend the research of MLLMs to point clouds and present the LAMM-Dataset and LAMM-Benchmark for 2D image and 3D point cloud understanding. We also establish an extensible framework to facilitate the extension of MLLMs to additional modalities. Our main contribution is three-fold: 1) We present the LAMM-Dataset and LAMM-Benchmark, which cover almost all high-level vision tasks for 2D and 3D vision. Extensive experiments validate the effectiveness of our dataset and benchmark. 2) We demonstrate the detailed methods of constructing instruction-tuning datasets and benchmarks for MLLMs, which will enable future research on MLLMs to scale up and extend to other domains, tasks, and modalities faster. 3) We provide a primary but potential MLLM training framework optimized for modalities' extension. We also provide baseline models, comprehensive experimental observations, and analysis to accelerate future research. Codes and datasets are now available at https://github.com/OpenLAMM/LAMM.