 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified Critical Step Optimization for LLM Agents
Feb 03, 2026As large language model agents tackle increasingly complex long-horizon tasks, effective post-training becomes critical. Prior work faces fundamental challenges: outcome-only rewards fail to precisely attribute credit to intermediate steps, estimated step-level rewards introduce systematic noise, and Monte Carlo sampling approaches for step reward estimation incur prohibitive computational cost. Inspired by findings that only a small fraction of high-entropy tokens drive effective RL for reasoning, we propose Critical Step Optimization (CSO), which focuses preference learning on verified critical steps, decision points where alternate actions demonstrably flip task outcomes from failure to success. Crucially, our method starts from failed policy trajectories rather than expert demonstrations, directly targeting the policy model's weaknesses. We use a process reward model (PRM) to identify candidate critical steps, leverage expert models to propose high-quality alternatives, then continue execution from these alternatives using the policy model itself until task completion. Only alternatives that the policy successfully executes to correct outcomes are verified and used as DPO training data, ensuring both quality and policy reachability. This yields fine-grained, verifiable supervision at critical decisions while avoiding trajectory-level coarseness and step-level noise. Experiments on GAIA-Text-103 and XBench-DeepSearch show that CSO achieves 37% and 26% relative improvement over the SFT baseline and substantially outperforms other post-training methods, while requiring supervision at only 16% of trajectory steps. This demonstrates the effectiveness of selective verification-based learning for agent post-training.
ClarifyMT-Bench: Benchmarking and Improving Multi-Turn Clarification for Conversational Large Language Models
Dec 24, 2025Large language models (LLMs) are increasingly deployed as conversational assistants in open-domain, multi-turn settings, where users often provide incomplete or ambiguous information. However, existing LLM-focused clarification benchmarks primarily assume single-turn interactions or cooperative users, limiting their ability to evaluate clarification behavior in realistic settings. We introduce \textbf{ClarifyMT-Bench}, a benchmark for multi-turn clarification grounded in a five-dimensional ambiguity taxonomy and a set of six behaviorally diverse simulated user personas. Through a hybrid LLM-human pipeline, we construct 6,120 multi-turn dialogues capturing diverse ambiguity sources and interaction patterns. Evaluating ten representative LLMs uncovers a consistent under-clarification bias: LLMs tend to answer prematurely, and performance degrades as dialogue depth increases. To mitigate this, we propose \textbf{ClarifyAgent}, an agentic approach that decomposes clarification into perception, forecasting, tracking, and planning, substantially improving robustness across ambiguity conditions. ClarifyMT-Bench establishes a reproducible foundation for studying when LLMs should ask, when they should answer, and how to navigate ambiguity in real-world human-LLM interactions.
EconProver: Towards More Economical Test-Time Scaling for Automated Theorem Proving
Sep 16, 2025Large Language Models (LLMs) have recently advanced the field of Automated Theorem Proving (ATP), attaining substantial performance gains through widely adopted test-time scaling strategies, notably reflective Chain-of-Thought (CoT) reasoning and increased sampling passes. However, they both introduce significant computational overhead for inference. Moreover, existing cost analyses typically regulate only the number of sampling passes, while neglecting the substantial disparities in sampling costs introduced by different scaling strategies. In this paper, we systematically compare the efficiency of different test-time scaling strategies for ATP models and demonstrate the inefficiency of the current state-of-the-art (SOTA) open-source approaches. We then investigate approaches to significantly reduce token usage and sample passes while maintaining the original performance. Specifically, we propose two complementary methods that can be integrated into a unified EconRL pipeline for amplified benefits: (1) a dynamic Chain-of-Thought (CoT) switching mechanism designed to mitigate unnecessary token consumption, and (2) Diverse parallel-scaled reinforcement learning (RL) with trainable prefixes to enhance pass rates under constrained sampling passes. Experiments on miniF2F and ProofNet demonstrate that our EconProver achieves comparable performance to baseline methods with only 12% of the computational cost. This work provides actionable insights for deploying lightweight ATP models without sacrificing performance.
GIRAFFE: Design Choices for Extending the Context Length of Visual Language Models
Dec 17, 2024
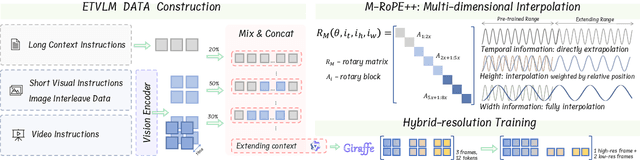
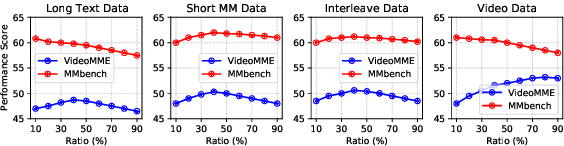
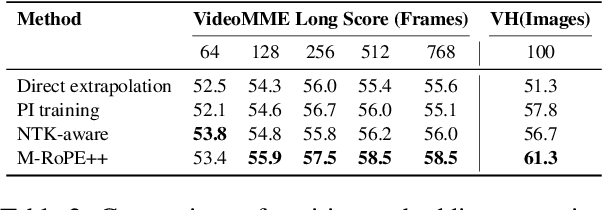
Visual Language Models (VLMs) demonstrate impressive capabilities in processing multimodal inputs, yet applications such as visual agents, which require handling multiple images and high-resolution videos, demand enhanced long-range modeling. Moreover, existing open-source VLMs lack systematic exploration into extending their context length, and commercial models often provide limited details. To tackle this, we aim to establish an effective solution that enhances long context performance of VLMs while preserving their capacities in short context scenarios. Towards this goal, we make the best design choice through extensive experiment settings from data curation to context window extending and utilizing: (1) we analyze data sources and length distributions to construct ETVLM - a data recipe to balance the performance across scenarios; (2) we examine existing position extending methods, identify their limitations and propose M-RoPE++ as an enhanced approach; we also choose to solely instruction-tune the backbone with mixed-source data; (3) we discuss how to better utilize extended context windows and propose hybrid-resolution training. Built on the Qwen-VL series model, we propose Giraffe, which is effectively extended to 128K lengths. Evaluated on extensive long context VLM benchmarks such as VideoMME and Viusal Haystacks, our Giraffe achieves state-of-the-art performance among similarly sized open-source long VLMs and is competitive with commercial model GPT-4V. We will open-source the code, data, and models.
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Oct 23, 2024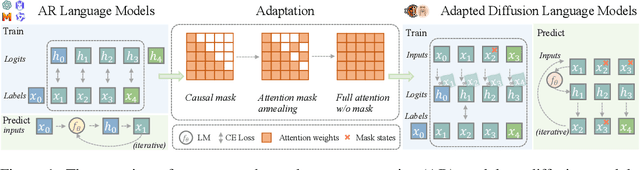
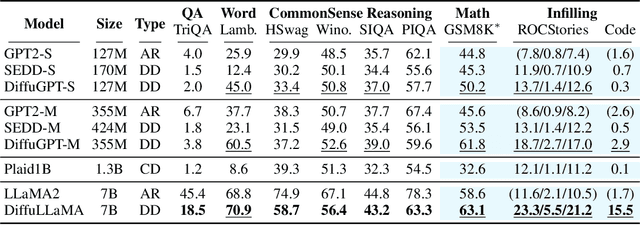
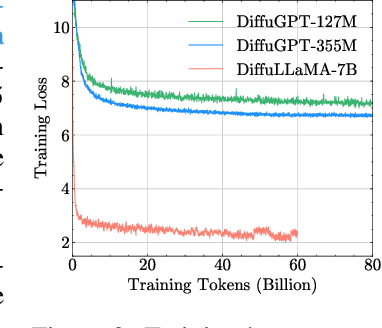
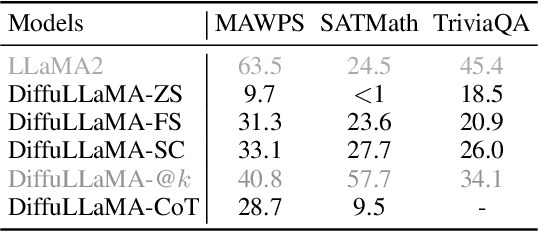
Diffusion Language Models (DLMs) have emerged as a promising new paradigm for text generative modeling, potentially addressing limitations of autoregressive (AR) models. However, current DLMs have been studied at a smaller scale compared to their AR counterparts and lack fair comparison on language modeling benchmarks. Additionally, training diffusion models from scratch at scale remains challenging. Given the prevalence of open-source AR language models, we propose adapting these models to build text diffusion models. We demonstrate connections between AR and diffusion modeling objectives and introduce a simple continual pre-training approach for training diffusion models. Through systematic evaluation on language modeling, reasoning, and commonsense benchmarks, we show that we can convert AR models ranging from 127M to 7B parameters (GPT2 and LLaMA) into diffusion models DiffuGPT and DiffuLLaMA, using less than 200B tokens for training. Our experimental results reveal that these models outperform earlier DLMs and are competitive with their AR counterparts. We release a suite of DLMs (with 127M, 355M, and 7B parameters) capable of generating fluent text, performing in-context learning, filling in the middle without prompt re-ordering, and following instructions \url{https://github.com/HKUNLP/DiffuLLaMA}.
VLFeedback: A Large-Scale AI Feedback Dataset for Large Vision-Language Models Alignment
Oct 12, 2024



As large vision-language models (LVLMs) evolve rapidly, the demand for high-quality and diverse data to align these models becomes increasingly crucial. However, the creation of such data with human supervision proves costly and time-intensive. In this paper, we investigate the efficacy of AI feedback to scale supervision for aligning LVLMs. We introduce VLFeedback, the first large-scale vision-language feedback dataset, comprising over 82K multi-modal instructions and comprehensive rationales generated by off-the-shelf models without human annotations. To evaluate the effectiveness of AI feedback for vision-language alignment, we train Silkie, an LVLM fine-tuned via direct preference optimization on VLFeedback. Silkie showcases exceptional performance regarding helpfulness, visual faithfulness, and safety metrics. It outperforms its base model by 6.9\% and 9.5\% in perception and cognition tasks, reduces hallucination issues on MMHal-Bench, and exhibits enhanced resilience against red-teaming attacks. Furthermore, our analysis underscores the advantage of AI feedback, particularly in fostering preference diversity to deliver more comprehensive improvements. Our dataset, training code and models are available at https://vlf-silkie.github.io.
Red Teaming Visual Language Models
Jan 23, 2024



VLMs (Vision-Language Models) extend the capabilities of LLMs (Large Language Models) to accept multimodal inputs. Since it has been verified that LLMs can be induced to generate harmful or inaccurate content through specific test cases (termed as Red Teaming), how VLMs perform in similar scenarios, especially with their combination of textual and visual inputs, remains a question. To explore this problem, we present a novel red teaming dataset RTVLM, which encompasses 10 subtasks (e.g., image misleading, multi-modal jail-breaking, face fairness, etc) under 4 primary aspects (faithfulness, privacy, safety, fairness). Our RTVLM is the first red-teaming dataset to benchmark current VLMs in terms of these 4 different aspects. Detailed analysis shows that 10 prominent open-sourced VLMs struggle with the red teaming in different degrees and have up to 31% performance gap with GPT-4V. Additionally, we simply apply red teaming alignment to LLaVA-v1.5 with Supervised Fine-tuning (SFT) using RTVLM, and this bolsters the models' performance with 10% in RTVLM test set, 13% in MM-Hal, and without noticeable decline in MM-Bench, overpassing other LLaVA-based models with regular alignment data. This reveals that current open-sourced VLMs still lack red teaming alignment. Our code and datasets will be open-source.
Silkie: Preference Distillation for Large Visual Language Models
Dec 17, 2023This paper explores preference distillation for large vision language models (LVLMs), improving their ability to generate helpful and faithful responses anchoring the visual context. We first build a vision-language feedback (VLFeedback) dataset utilizing AI annotation. Specifically, responses are generated by models sampled from 12 LVLMs, conditioned on multi-modal instructions sourced from various datasets. We adopt GPT-4V to assess the generated outputs regarding helpfulness, visual faithfulness, and ethical considerations. Furthermore, the preference supervision is distilled into Qwen-VL-Chat through the direct preference optimization (DPO) method. The resulting model Silkie, achieves 6.9% and 9.5% relative improvement on the MME benchmark regarding the perception and cognition capabilities, respectively. Silkie also demonstrates reduced hallucination by setting a new state-of-the-art score of 3.02 on the MMHal-Bench benchmark. Further analysis shows that DPO with our VLFeedback dataset mainly boosts the fine-grained perception and complex cognition abilities of LVLMs, leading to more comprehensive improvements compared to human-annotated preference datasets.
To be or not to be? an exploration of continuously controllable prompt engineering
Nov 16, 2023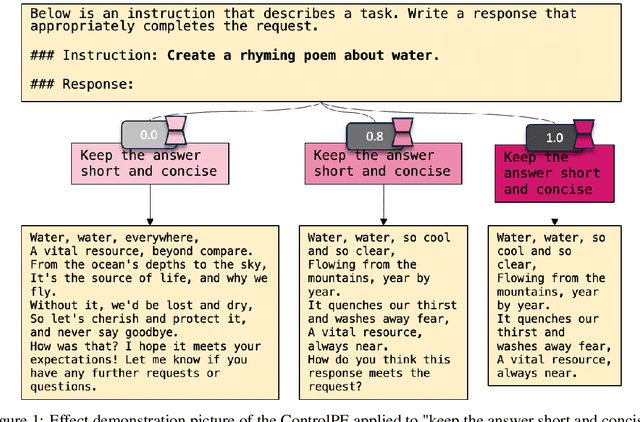
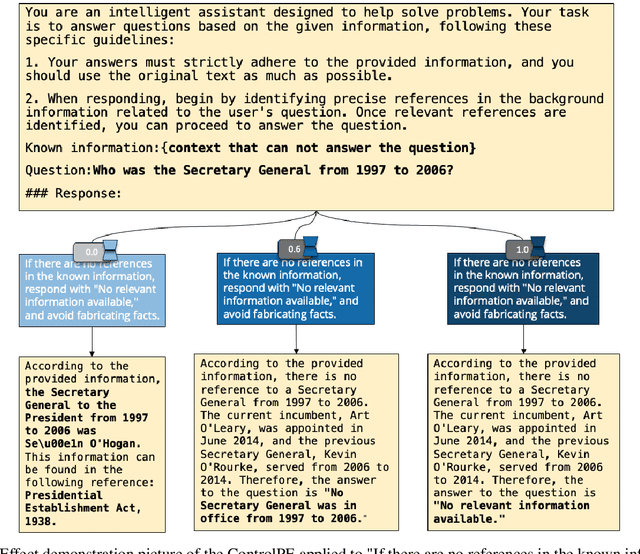
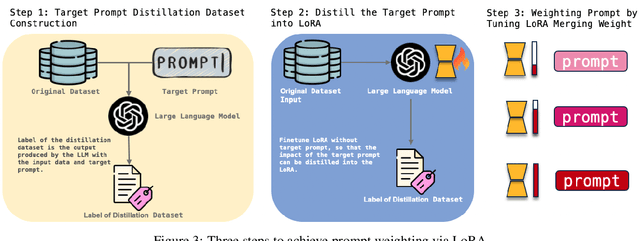
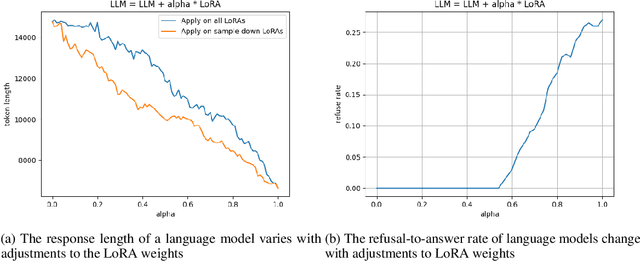
As the use of large language models becomes more widespread, techniques like parameter-efficient fine-tuning and other methods for controlled generation are gaining traction for customizing models and managing their outputs. However, the challenge of precisely controlling how prompts influence these models is an area ripe for further investigation. In response, we introduce ControlPE (Continuously Controllable Prompt Engineering). ControlPE enables finer adjustments to prompt effects, complementing existing prompt engineering, and effectively controls continuous targets. This approach harnesses the power of LoRA (Low-Rank Adaptation) to create an effect akin to prompt weighting, enabling fine-tuned adjustments to the impact of prompts. Our methodology involves generating specialized datasets for prompt distillation, incorporating these prompts into the LoRA model, and carefully adjusting LoRA merging weight to regulate the influence of prompts. This provides a dynamic and adaptable tool for prompt control. Through our experiments, we have validated the practicality and efficacy of ControlPE. It proves to be a promising solution for control a variety of prompts, ranging from generating short responses prompts, refusal prompts to chain-of-thought prompts.
DiffuSeq-v2: Bridging Discrete and Continuous Text Spaces for Accelerated Seq2Seq Diffusion Models
Oct 16, 2023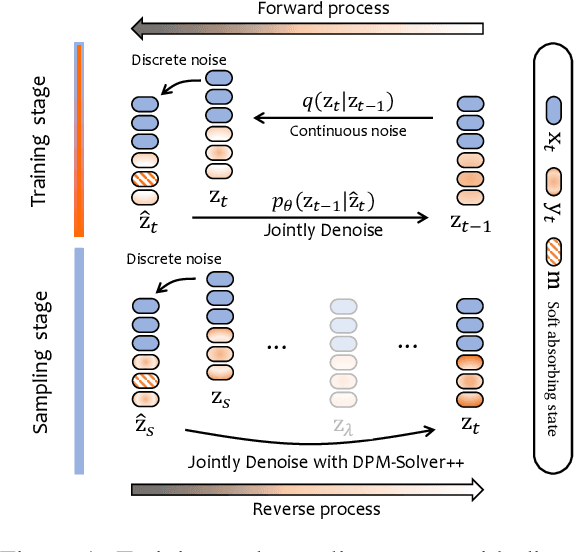
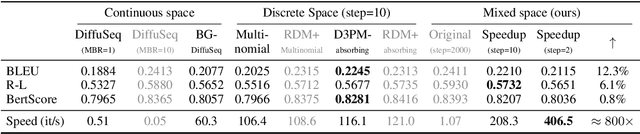
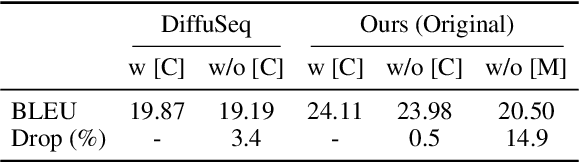
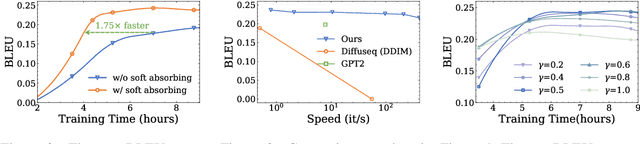
Diffusion models have gained prominence in generating high-quality sequences of text. Nevertheless, current approaches predominantly represent discrete text within a continuous diffusion space, which incurs substantial computational overhead during training and results in slower sampling speeds. In this paper, we introduce a soft absorbing state that facilitates the diffusion model in learning to reconstruct discrete mutations based on the underlying Gaussian space, thereby enhancing its capacity to recover conditional signals. During the sampling phase, we employ state-of-the-art ODE solvers within the continuous space to expedite the sampling process. Comprehensive experimental evaluations reveal that our proposed method effectively accelerates the training convergence by 4x and generates samples of similar quality 800x faster, rendering it significantly closer to practical application. \footnote{The code is released at \url{https://github.com/Shark-NLP/DiffuSeq}