 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo be or not to be? an exploration of continuously controllable prompt engineering
Paper and Code
Nov 16, 2023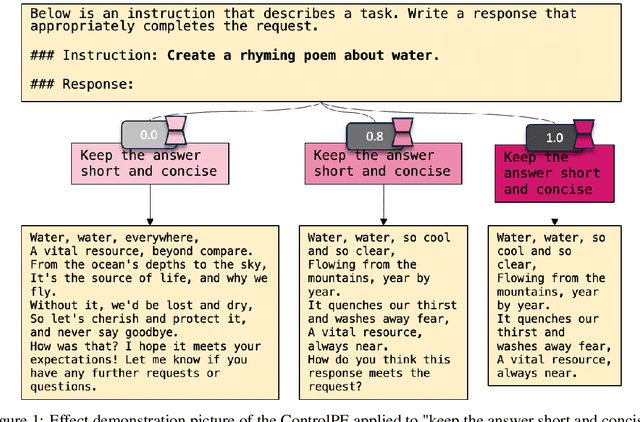
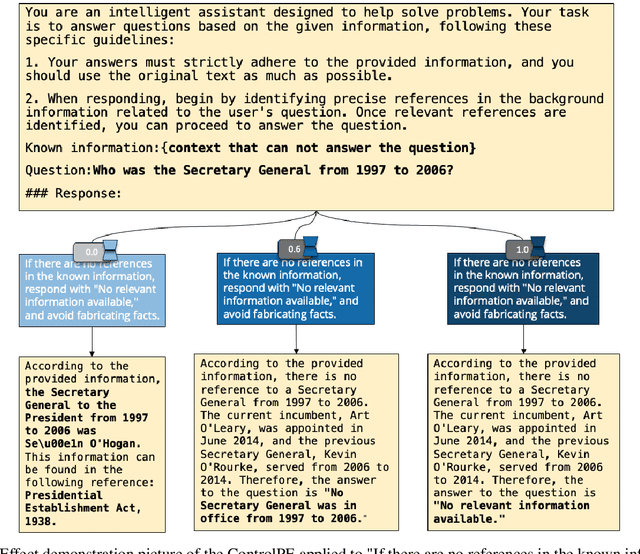
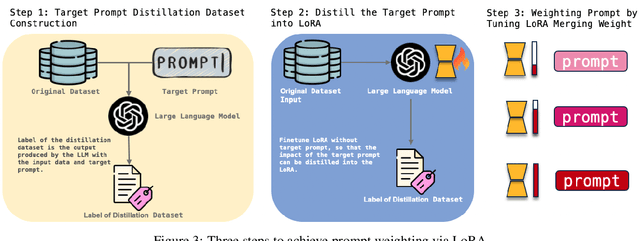
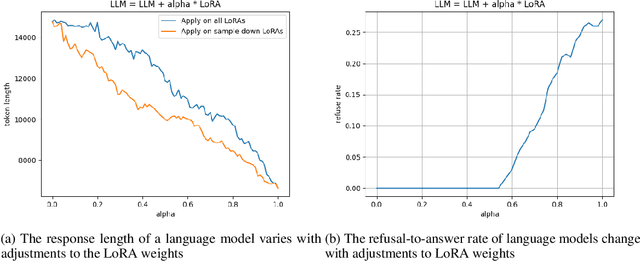
As the use of large language models becomes more widespread, techniques like parameter-efficient fine-tuning and other methods for controlled generation are gaining traction for customizing models and managing their outputs. However, the challenge of precisely controlling how prompts influence these models is an area ripe for further investigation. In response, we introduce ControlPE (Continuously Controllable Prompt Engineering). ControlPE enables finer adjustments to prompt effects, complementing existing prompt engineering, and effectively controls continuous targets. This approach harnesses the power of LoRA (Low-Rank Adaptation) to create an effect akin to prompt weighting, enabling fine-tuned adjustments to the impact of prompts. Our methodology involves generating specialized datasets for prompt distillation, incorporating these prompts into the LoRA model, and carefully adjusting LoRA merging weight to regulate the influence of prompts. This provides a dynamic and adaptable tool for prompt control. Through our experiments, we have validated the practicality and efficacy of ControlPE. It proves to be a promising solution for control a variety of prompts, ranging from generating short responses prompts, refusal prompts to chain-of-thought prompts.