 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEX: Neuron Explore-Exploit Scoring for Label-Free Chain-of-Thought Selection and Model Ranking
Feb 05, 2026Large language models increasingly spend inference compute sampling multiple chain-of-thought traces or searching over merged checkpoints. This shifts the bottleneck from generation to selection, often without supervision on the target distribution. We show entropy-based exploration proxies follow an inverted-U with accuracy, suggesting extra exploration can become redundant and induce overthinking. We propose NEX, a white-box label-free unsupervised scoring framework that views reasoning as alternating E-phase (exploration) and X-phase (exploitation). NEX detects E-phase as spikes in newly activated MLP neurons per token from sparse activation caches, then uses a sticky two-state HMM to infer E-X phases and credits E-introduced neurons by whether they are reused in the following X span. These signals yield interpretable neuron weights and a single Good-Mass Fraction score to rank candidate responses and merged variants without task answers. Across reasoning benchmarks and Qwen3 merge families, NEX computed on a small unlabeled activation set predicts downstream accuracy and identifies better variants; we further validate the E-X signal with human annotations and provide causal evidence via "Effective-vs-Redundant" neuron transfer.
Rethinking the Role of Entropy in Optimizing Tool-Use Behaviors for Large Language Model Agents
Feb 02, 2026Tool-using agents based on Large Language Models (LLMs) excel in tasks such as mathematical reasoning and multi-hop question answering. However, in long trajectories, agents often trigger excessive and low-quality tool calls, increasing latency and degrading inference performance, making managing tool-use behavior challenging. In this work, we conduct entropy-based pilot experiments and observe a strong positive correlation between entropy reduction and high-quality tool calls. Building on this finding, we propose using entropy reduction as a supervisory signal and design two reward strategies to address the differing needs of optimizing tool-use behavior. Sparse outcome rewards provide coarse, trajectory-level guidance to improve efficiency, while dense process rewards offer fine-grained supervision to enhance performance. Experiments across diverse domains show that both reward designs improve tool-use behavior: the former reduces tool calls by 72.07% compared to the average of baselines, while the latter improves performance by 22.27%. These results position entropy reduction as a key mechanism for enhancing tool-use behavior, enabling agents to be more adaptive in real-world applications.
CoDiQ: Test-Time Scaling for Controllable Difficult Question Generation
Feb 02, 2026Large Reasoning Models (LRMs) benefit substantially from training on challenging competition-level questions. However, existing automated question synthesis methods lack precise difficulty control, incur high computational costs, and struggle to generate competition-level questions at scale. In this paper, we propose CoDiQ (Controllable Difficult Question Generation), a novel framework enabling fine-grained difficulty control via test-time scaling while ensuring question solvability. Specifically, first, we identify a test-time scaling tendency (extended reasoning token budget boosts difficulty but reduces solvability) and the intrinsic properties defining the upper bound of a model's ability to generate valid, high-difficulty questions. Then, we develop CoDiQ-Generator from Qwen3-8B, which improves the upper bound of difficult question generation, making it particularly well-suited for challenging question construction. Building on the CoDiQ framework, we build CoDiQ-Corpus (44K competition-grade question sequences). Human evaluations show these questions are significantly more challenging than LiveCodeBench/AIME with over 82% solvability. Training LRMs on CoDiQ-Corpus substantially improves reasoning performance, verifying that scaling controlled-difficulty training questions enhances reasoning capabilities. We open-source CoDiQ-Corpus, CoDiQ-Generator, and implementations to support related research.
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents
Jan 23, 2026We introduce EMemBench, a programmatic benchmark for evaluating long-term memory of agents through interactive games. Rather than using a fixed set of questions, EMemBench generates questions from each agent's own trajectory, covering both text and visual game environments. Each template computes verifiable ground truth from underlying game signals, with controlled answerability and balanced coverage over memory skills: single/multi-hop recall, induction, temporal, spatial, logical, and adversarial. We evaluate memory agents with strong LMs/VLMs as backbones, using in-context prompting as baselines. Across 15 text games and multiple visual seeds, results are far from saturated: induction and spatial reasoning are persistent bottlenecks, especially in visual setting. Persistent memory yields clear gains for open backbones on text games, but improvements are less consistent for VLM agents, suggesting that visually grounded episodic memory remains an open challenge. A human study further confirms the difficulty of EMemBench.
Thinking Traps in Long Chain-of-Thought: A Measurable Study and Trap-Aware Adaptive Restart
Jan 17, 2026Scaling test-time compute via Long Chain-of-Thought (Long-CoT) significantly enhances reasoning capabilities, yet extended generation does not guarantee correctness: after an early wrong commitment, models may keep elaborating a self-consistent but incorrect prefix. Through fine-grained trajectory analysis, we identify Thinking Traps, prefix-dominant deadlocks where later reflection, alternative attempts, or verification fails to revise the root error. On a curated subset of DAPO-MATH, 89\% of failures exhibit such traps. To solve this problem, we introduce TAAR (Trap-Aware Adaptive Restart), a test-time control framework that trains a diagnostic policy to predict two signals from partial trajectories: a trap index for where to truncate and an escape probability for whether and how strongly to intervene. At inference time, TAAR truncates the trajectory before the predicted trap segment and adaptively restarts decoding; for severely trapped cases, it applies stronger perturbations, including higher-temperature resampling and an optional structured reboot suffix. Experiments on challenging mathematical and scientific reasoning benchmarks (AIME24, AIME25, GPQA-Diamond, HMMT25, BRUMO25) show that TAAR improves reasoning performance without fine-tuning base model parameters.
What Do LLM Agents Know About Their World? Task2Quiz: A Paradigm for Studying Environment Understanding
Jan 14, 2026Large language model (LLM) agents have demonstrated remarkable capabilities in complex decision-making and tool-use tasks, yet their ability to generalize across varying environments remains a under-examined concern. Current evaluation paradigms predominantly rely on trajectory-based metrics that measure task success, while failing to assess whether agents possess a grounded, transferable model of the environment. To address this gap, we propose Task-to-Quiz (T2Q), a deterministic and automated evaluation paradigm designed to decouple task execution from world-state understanding. We instantiate this paradigm in T2QBench, a suite comprising 30 environments and 1,967 grounded QA pairs across multiple difficulty levels. Our extensive experiments reveal that task success is often a poor proxy for environment understanding, and that current memory machanism can not effectively help agents acquire a grounded model of the environment. These findings identify proactive exploration and fine-grained state representation as primary bottlenecks, offering a robust foundation for developing more generalizable autonomous agents.
ARM: Role-Conditioned Neuron Transplantation for Training-Free Generalist LLM Agent Merging
Jan 12, 2026Interactive large language model agents have advanced rapidly, but most remain specialized to a single environment and fail to adapt robustly to other environments. Model merging offers a training-free alternative by integrating multiple experts into a single model. In this paper, we propose Agent-Role Merging (ARM), an activation-guided, role-conditioned neuron transplantation method for model merging in LLM agents. ARM improves existing merging methods from static natural language tasks to multi-turn agent scenarios, and over the generalization ability across various interactive environments. This is achieved with a well designed 3-step framework: 1) constructing merged backbones, 2) selection based on its role-conditioned activation analysis, and 3) neuron transplantation for fine-grained refinements. Without gradient-based optimization, ARM improves cross-benchmark generalization while enjoying efficiency. Across diverse domains, the model obtained via ARM merging outperforms prior model merging methods and domain-specific expert models, while demonstrating strong out-of-domain generalization.
SCALER:Synthetic Scalable Adaptive Learning Environment for Reasoning
Jan 08, 2026Reinforcement learning (RL) offers a principled way to enhance the reasoning capabilities of large language models, yet its effectiveness hinges on training signals that remain informative as models evolve. In practice, RL progress often slows when task difficulty becomes poorly aligned with model capability, or when training is dominated by a narrow set of recurring problem patterns. To jointly address these issues, we propose SCALER (Synthetic sCalable Adaptive Learning Environment for Reasoning), a framework that sustains effective learning signals through adaptive environment design. SCALER introduces a scalable synthesis pipeline that converts real-world programming problems into verifiable reasoning environments with controllable difficulty and unbounded instance generation, enabling RL training beyond finite datasets while preserving strong correctness guarantees. Building on this, SCALER further employs an adaptive multi-environment RL strategy that dynamically adjusts instance difficulty and curates the active set of environments to track the model's capability frontier and maintain distributional diversity. This co-adaptation prevents reward sparsity, mitigates overfitting to narrow task patterns, and supports sustained improvement throughout training. Extensive experiments show that SCALER consistently outperforms dataset-based RL baselines across diverse reasoning benchmarks and exhibits more stable, long-horizon training dynamics.
Do LLMs Signal When They're Right? Evidence from Neuron Agreement
Oct 30, 2025Large language models (LLMs) commonly boost reasoning via sample-evaluate-ensemble decoders, achieving label free gains without ground truth. However, prevailing strategies score candidates using only external outputs such as token probabilities, entropies, or self evaluations, and these signals can be poorly calibrated after post training. We instead analyze internal behavior based on neuron activations and uncover three findings: (1) external signals are low dimensional projections of richer internal dynamics; (2) correct responses activate substantially fewer unique neurons than incorrect ones throughout generation; and (3) activations from correct responses exhibit stronger cross sample agreement, whereas incorrect ones diverge. Motivated by these observations, we propose Neuron Agreement Decoding (NAD), an unsupervised best-of-N method that selects candidates using activation sparsity and cross sample neuron agreement, operating solely on internal signals and without requiring comparable textual outputs. NAD enables early correctness prediction within the first 32 generated tokens and supports aggressive early stopping. Across math and science benchmarks with verifiable answers, NAD matches majority voting; on open ended coding benchmarks where majority voting is inapplicable, NAD consistently outperforms Avg@64. By pruning unpromising trajectories early, NAD reduces token usage by 99% with minimal loss in generation quality, showing that internal signals provide reliable, scalable, and efficient guidance for label free ensemble decoding.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025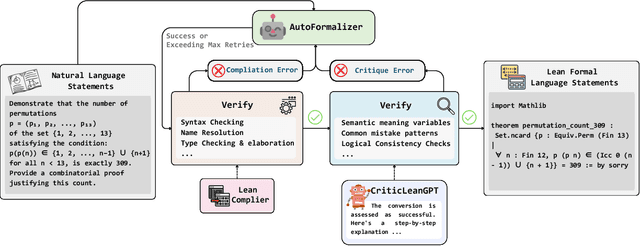

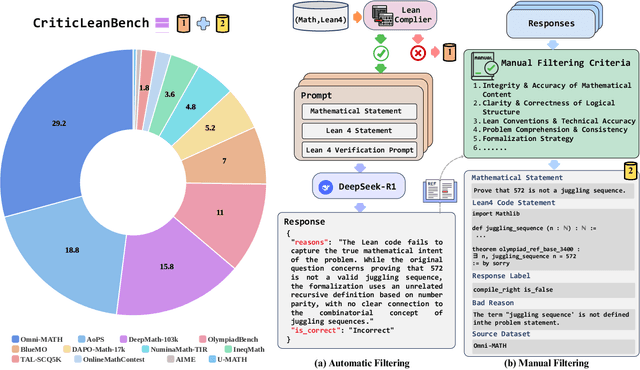
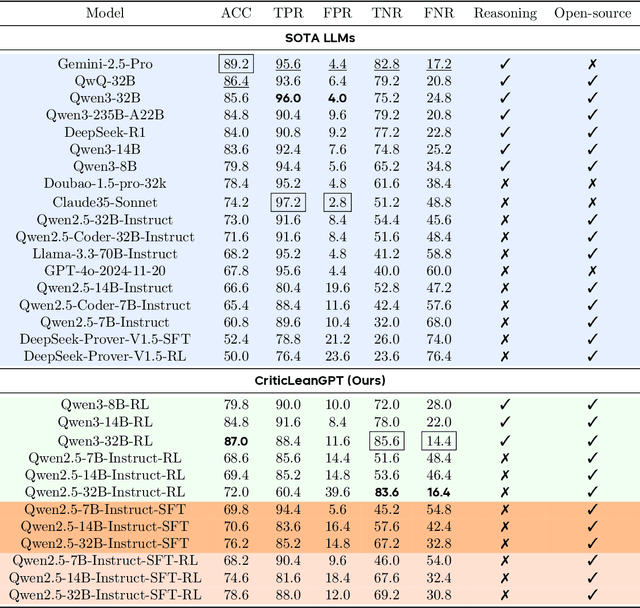
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.