 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are We? Systematic Evaluation of LLMs vs. Human Experts in Mathematical Contest in Modeling
Apr 06, 2026Large language models (LLMs) have achieved strong performance on reasoning benchmarks, yet their ability to solve real-world problems requiring end-to-end workflows remains unclear. Mathematical modeling competitions provide a stringent testbed for evaluating such end-to-end problem-solving capability. We propose a problem-oriented, stage-wise evaluation framework that assesses LLM performance across modeling stages using expert-verified criteria. We validate the framework's reliability by comparing automatic scores with independent human expert judgments on problems from the China Postgraduate Mathematical Contest in Modeling, demonstrating substantially stronger alignment than existing evaluation schemes. Using this framework, we reveal a comprehension-execution gap in state-of-the-art LLMs: while they perform well in early stages such as problem identification and formulation, they exhibit persistent deficiencies in execution-oriented stages including model solving, code implementation, and result analysis. These gaps persist even with increased model scale. We further trace these failures to insufficient specification, missing verification, and lack of validation, with errors propagating across stages without correction. Our findings suggest that bridging this gap requires approaches beyond model scaling, offering insights for applying LLMs to complex real-world problem solving.
Consistent Client Simulation for Motivational Interviewing-based Counseling
Feb 05, 2025Simulating human clients in mental health counseling is crucial for training and evaluating counselors (both human or simulated) in a scalable manner. Nevertheless, past research on client simulation did not focus on complex conversation tasks such as mental health counseling. In these tasks, the challenge is to ensure that the client's actions (i.e., interactions with the counselor) are consistent with with its stipulated profiles and negative behavior settings. In this paper, we propose a novel framework that supports consistent client simulation for mental health counseling. Our framework tracks the mental state of a simulated client, controls its state transitions, and generates for each state behaviors consistent with the client's motivation, beliefs, preferred plan to change, and receptivity. By varying the client profile and receptivity, we demonstrate that consistent simulated clients for different counseling scenarios can be effectively created. Both our automatic and expert evaluations on the generated counseling sessions also show that our client simulation method achieves higher consistency than previous methods.
CAMI: A Counselor Agent Supporting Motivational Interviewing through State Inference and Topic Exploration
Feb 05, 2025Conversational counselor agents have become essential tools for addressing the rising demand for scalable and accessible mental health support. This paper introduces CAMI, a novel automated counselor agent grounded in Motivational Interviewing (MI) -- a client-centered counseling approach designed to address ambivalence and facilitate behavior change. CAMI employs a novel STAR framework, consisting of client's state inference, motivation topic exploration, and response generation modules, leveraging large language models (LLMs). These components work together to evoke change talk, aligning with MI principles and improving counseling outcomes for clients from diverse backgrounds. We evaluate CAMI's performance through both automated and manual evaluations, utilizing simulated clients to assess MI skill competency, client's state inference accuracy, topic exploration proficiency, and overall counseling success. Results show that CAMI not only outperforms several state-of-the-art methods but also shows more realistic counselor-like behavior. Additionally, our ablation study underscores the critical roles of state inference and topic exploration in achieving this performance.
EvoWiki: Evaluating LLMs on Evolving Knowledge
Dec 18, 2024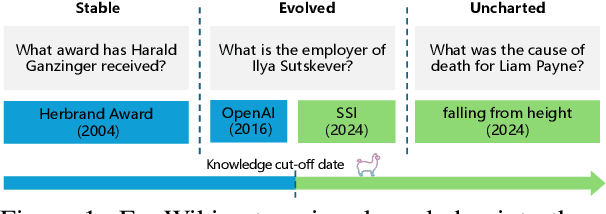
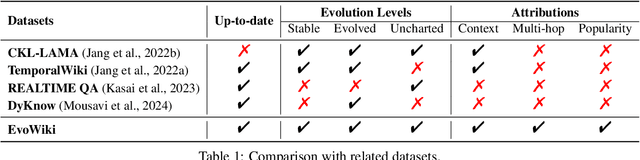
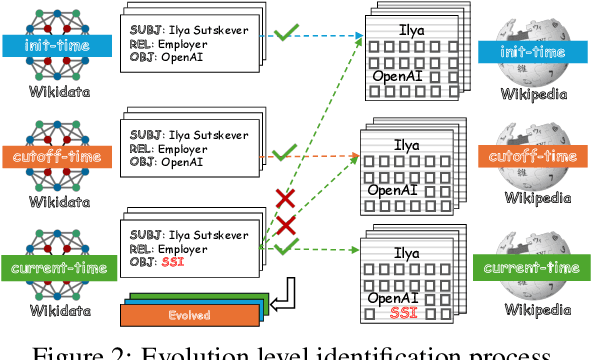
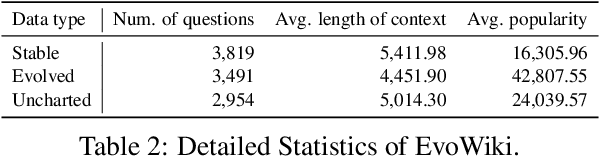
Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.
PSPO*: An Effective Process-supervised Policy Optimization for Reasoning Alignment
Nov 18, 2024



Process supervision enhances the performance of large language models in reasoning tasks by providing feedback at each step of chain-of-thought reasoning. However, due to the lack of effective process supervision methods, even advanced large language models are prone to logical errors and redundant reasoning. We claim that the effectiveness of process supervision significantly depends on both the accuracy and the length of reasoning chains. Moreover, we identify that these factors exhibit a nonlinear relationship with the overall reward score of the reasoning process. Inspired by these insights, we propose a novel process supervision paradigm, PSPO*, which systematically outlines the workflow from reward model training to policy optimization, and highlights the importance of nonlinear rewards in process supervision. Based on PSPO*, we develop the PSPO-WRS, which considers the number of reasoning steps in determining reward scores and utilizes an adjusted Weibull distribution for nonlinear reward shaping. Experimental results on six mathematical reasoning datasets demonstrate that PSPO-WRS consistently outperforms current mainstream models.
Speaker Verification in Agent-Generated Conversations
May 16, 2024
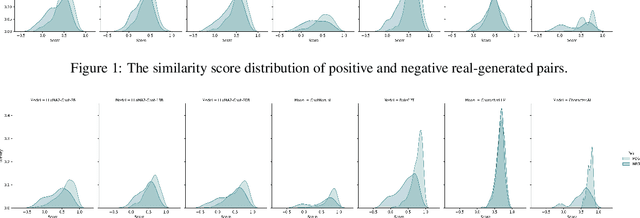


The recent success of large language models (LLMs) has attracted widespread interest to develop role-playing conversational agents personalized to the characteristics and styles of different speakers to enhance their abilities to perform both general and special purpose dialogue tasks. However, the ability to personalize the generated utterances to speakers, whether conducted by human or LLM, has not been well studied. To bridge this gap, our study introduces a novel evaluation challenge: speaker verification in agent-generated conversations, which aimed to verify whether two sets of utterances originate from the same speaker. To this end, we assemble a large dataset collection encompassing thousands of speakers and their utterances. We also develop and evaluate speaker verification models under experiment setups. We further utilize the speaker verification models to evaluate the personalization abilities of LLM-based role-playing models. Comprehensive experiments suggest that the current role-playing models fail in accurately mimicking speakers, primarily due to their inherent linguistic characteristics.
Have Seen Me Before? Automating Dataset Updates Towards Reliable and Timely Evaluation
Feb 28, 2024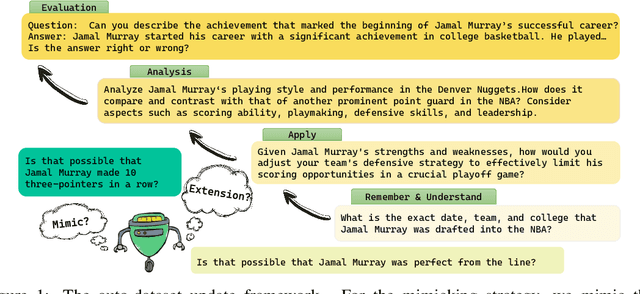


Due to the expanding capabilities and pre-training data, Large Language Models (LLMs) are facing increasingly serious evaluation challenges. On one hand, the data leakage issue cause over-estimation on existing benchmarks. On the other hand, periodically curating datasets manually is costly. In this paper, we propose to automate dataset updates for reliable and timely evaluation. The basic idea is to generate unseen and high-quality testing samples based on existing ones to mitigate leakage issues. In specific, we propose two strategies with systematically verification. First, the mimicking strategy employs LLMs to create new samples resembling existing ones, to the maximum extent preserving the stylistic of the original dataset. Our experiments demonstrate its evaluation stability across multiple instantiations and its effectiveness in dealing with data leakage issues in most cases. Second, for the cases that mimicking dataset works poorly, we design an extending strategy that adjusts the difficulty of the generated samples according to varying cognitive levels. This not only makes our evaluation more systematic, but also, with a balanced difficulty, even discern model capabilities better at fine-grained levels.
Graph vs. Sequence: An Empirical Study on Knowledge Forms for Knowledge-Grounded Dialogue
Dec 13, 2023



Knowledge-grounded dialogue is a task of generating an informative response based on both the dialogue history and external knowledge source. In general, there are two forms of knowledge: manually annotated knowledge graphs and knowledge text from website. From various evaluation viewpoints, each type of knowledge has advantages and downsides. To further distinguish the principles and determinants from the intricate factors, we conduct a thorough experiment and study on the task to answer three essential questions. The questions involve the choice of appropriate knowledge form, the degree of mutual effects between knowledge and the model selection, and the few-shot performance of knowledge. Supported by statistical shreds of evidence, we offer conclusive solutions and sensible suggestions for directions and standards of future research.
TSST: A Benchmark and Evaluation Models for Text Speech-Style Transfer
Nov 14, 2023



Text style is highly abstract, as it encompasses various aspects of a speaker's characteristics, habits, logical thinking, and the content they express. However, previous text-style transfer tasks have primarily focused on data-driven approaches, lacking in-depth analysis and research from the perspectives of linguistics and cognitive science. In this paper, we introduce a novel task called Text Speech-Style Transfer (TSST). The main objective is to further explore topics related to human cognition, such as personality and emotion, based on the capabilities of existing LLMs. Considering the objective of our task and the distinctive characteristics of oral speech in real-life scenarios, we trained multi-dimension (i.e. filler words, vividness, interactivity, emotionality) evaluation models for the TSST and validated their correlation with human assessments. We thoroughly analyze the performance of several large language models (LLMs) and identify areas where further improvement is needed. Moreover, driven by our evaluation models, we have released a new corpus that improves the capabilities of LLMs in generating text with speech-style characteristics. In summary, we present the TSST task, a new benchmark for style transfer and emphasizing human-oriented evaluation, exploring and advancing the performance of current LLMs.
MindLLM: Pre-training Lightweight Large Language Model from Scratch, Evaluations and Domain Applications
Oct 29, 2023



Large Language Models (LLMs) have demonstrated remarkable performance across various natural language tasks, marking significant strides towards general artificial intelligence. While general artificial intelligence is leveraged by developing increasingly large-scale models, there could be another branch to develop lightweight custom models that better serve certain domains, taking into account the high cost of training and deploying LLMs and the scarcity of resources. In this paper, we present MindLLM, a novel series of bilingual lightweight large language models, trained from scratch, alleviating such burdens by offering models with 1.3 billion and 3 billion parameters. A thorough account of experiences accrued during large model development is given, covering every step of the process, including data construction, model architecture, evaluation, and applications. Such insights are hopefully valuable for fellow academics and developers. MindLLM consistently matches or surpasses the performance of other open-source larger models on some public benchmarks. We also introduce an innovative instruction tuning framework tailored for smaller models to enhance their capabilities efficiently. Moreover, we explore the application of MindLLM in specific vertical domains such as law and finance, underscoring the agility and adaptability of our lightweight models.