 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Client Simulation for Motivational Interviewing-based Counseling
Feb 05, 2025Simulating human clients in mental health counseling is crucial for training and evaluating counselors (both human or simulated) in a scalable manner. Nevertheless, past research on client simulation did not focus on complex conversation tasks such as mental health counseling. In these tasks, the challenge is to ensure that the client's actions (i.e., interactions with the counselor) are consistent with with its stipulated profiles and negative behavior settings. In this paper, we propose a novel framework that supports consistent client simulation for mental health counseling. Our framework tracks the mental state of a simulated client, controls its state transitions, and generates for each state behaviors consistent with the client's motivation, beliefs, preferred plan to change, and receptivity. By varying the client profile and receptivity, we demonstrate that consistent simulated clients for different counseling scenarios can be effectively created. Both our automatic and expert evaluations on the generated counseling sessions also show that our client simulation method achieves higher consistency than previous methods.
CAMI: A Counselor Agent Supporting Motivational Interviewing through State Inference and Topic Exploration
Feb 05, 2025Conversational counselor agents have become essential tools for addressing the rising demand for scalable and accessible mental health support. This paper introduces CAMI, a novel automated counselor agent grounded in Motivational Interviewing (MI) -- a client-centered counseling approach designed to address ambivalence and facilitate behavior change. CAMI employs a novel STAR framework, consisting of client's state inference, motivation topic exploration, and response generation modules, leveraging large language models (LLMs). These components work together to evoke change talk, aligning with MI principles and improving counseling outcomes for clients from diverse backgrounds. We evaluate CAMI's performance through both automated and manual evaluations, utilizing simulated clients to assess MI skill competency, client's state inference accuracy, topic exploration proficiency, and overall counseling success. Results show that CAMI not only outperforms several state-of-the-art methods but also shows more realistic counselor-like behavior. Additionally, our ablation study underscores the critical roles of state inference and topic exploration in achieving this performance.
Cross-Modal Food Retrieval: Learning a Joint Embedding of Food Images and Recipes with Semantic Consistency and Attention Mechanism
Mar 09, 2020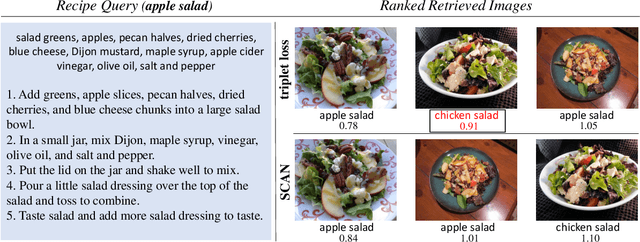
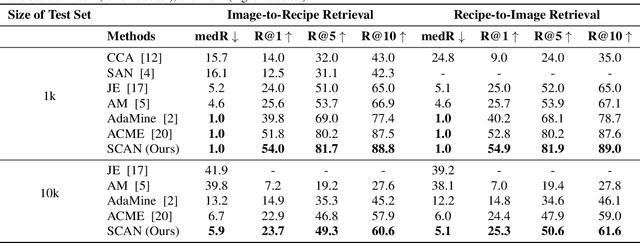
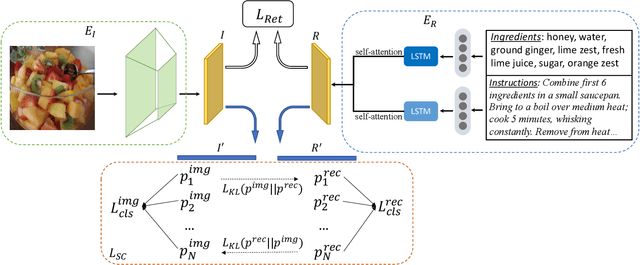
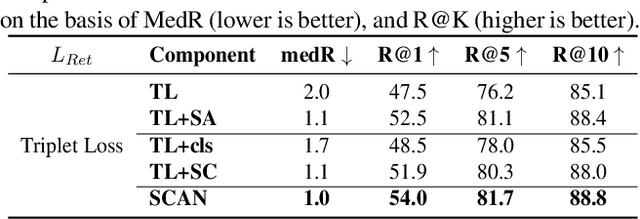
Cross-modal food retrieval is an important task to perform analysis of food-related information, such as food images and cooking recipes. The goal is to learn an embedding of images and recipes in a common feature space, so that precise matching can be realized. Compared with existing cross-modal retrieval approaches, two major challenges in this specific problem are: 1) the large intra-class variance across cross-modal food data; and 2) the difficulties in obtaining discriminative recipe representations. To address these problems, we propose Semantic-Consistent and Attention-based Networks (SCAN), which regularize the embeddings of the two modalities by aligning output semantic probabilities. In addition, we exploit self-attention mechanism to improve the embedding of recipes. We evaluate the performance of the proposed method on the large-scale Recipe1M dataset, and the result shows that it outperforms the state-of-the-art.
Learning Cross-Modal Embeddings with Adversarial Networks for Cooking Recipes and Food Images
May 03, 2019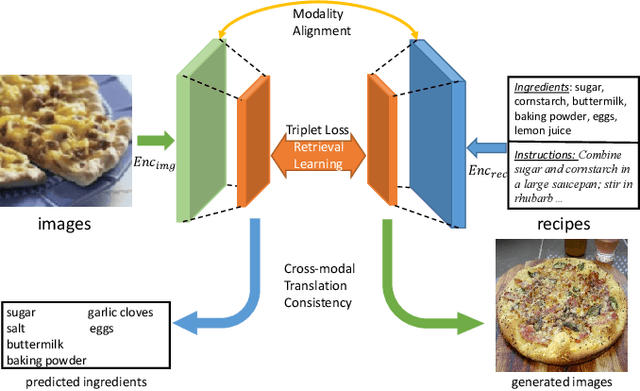
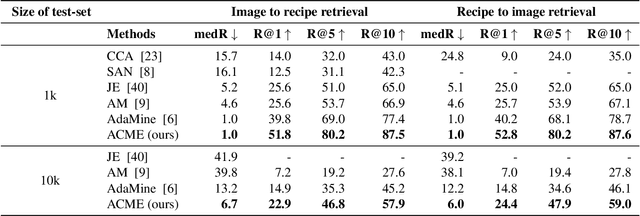
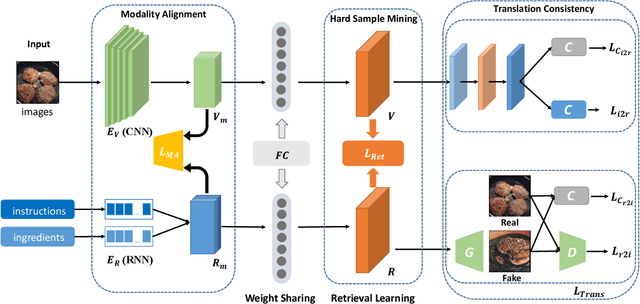
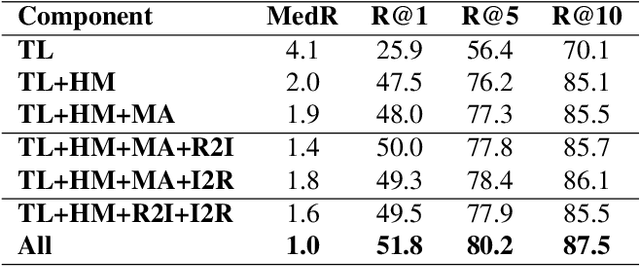
Food computing is playing an increasingly important role in human daily life, and has found tremendous applications in guiding human behavior towards smart food consumption and healthy lifestyle. An important task under the food-computing umbrella is retrieval, which is particularly helpful for health related applications, where we are interested in retrieving important information about food (e.g., ingredients, nutrition, etc.). In this paper, we investigate an open research task of cross-modal retrieval between cooking recipes and food images, and propose a novel framework Adversarial Cross-Modal Embedding (ACME) to resolve the cross-modal retrieval task in food domains. Specifically, the goal is to learn a common embedding feature space between the two modalities, in which our approach consists of several novel ideas: (i) learning by using a new triplet loss scheme together with an effective sampling strategy, (ii) imposing modality alignment using an adversarial learning strategy, and (iii) imposing cross-modal translation consistency such that the embedding of one modality is able to recover some important information of corresponding instances in the other modality. ACME achieves the state-of-the-art performance on the benchmark Recipe1M dataset, validating the efficacy of the proposed technique.