 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergentBridge: Improving Zero-Shot Cross-Modal Transfer in Unified Multimodal Embedding Models
Apr 14, 2026Unified multimodal embedding spaces underpin practical applications such as cross-modal retrieval and zero-shot recognition. In many real deployments, however, supervision is available only for a small subset of modality pairs (e.g., image--text), leaving \emph{unpaired} modality pairs (e.g., audio$\leftrightarrow$depth, infrared$\leftrightarrow$audio) weakly connected and thus performing poorly on zero-shot transfer. Addressing this sparse-pairing regime is therefore essential for scaling unified embedding systems to new tasks without curating exhaustive pairwise data. We propose \textbf{EmergentBridge}, an embedding-level bridging framework that improves performance on these unpaired pairs \emph{without requiring exhaustive pairwise supervision}. Our key observation is that naively aligning a new modality to a synthesized proxy embedding can introduce \emph{gradient interference}, degrading the anchor-alignment structure that existing retrieval/classification relies on. EmergentBridge addresses this by (i) learning a mapping that produces a \emph{noisy bridge anchor} (a proxy embedding of an already-aligned modality) from an anchor embedding, and (ii) enforcing proxy alignment only in the subspace orthogonal to the anchor-alignment direction, preserving anchor alignment while strengthening non-anchor connectivity. Across nine datasets spanning multiple modalities, EmergentBridge consistently outperforms prior binding baselines on zero-shot classification and retrieval, demonstrating strong emergent alignment.
FlashBack:Efficient Retrieval-Augmented Language Modeling for Long Context Inference
May 07, 2024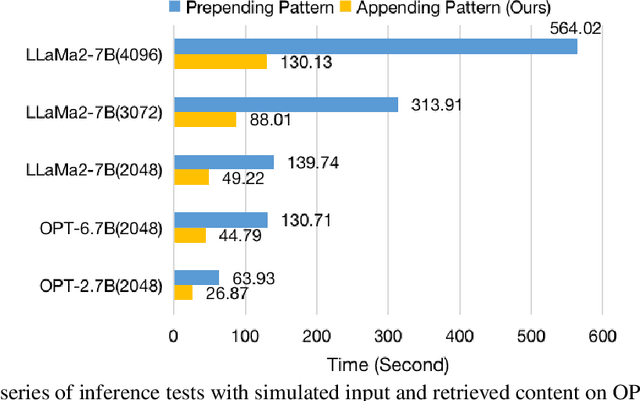
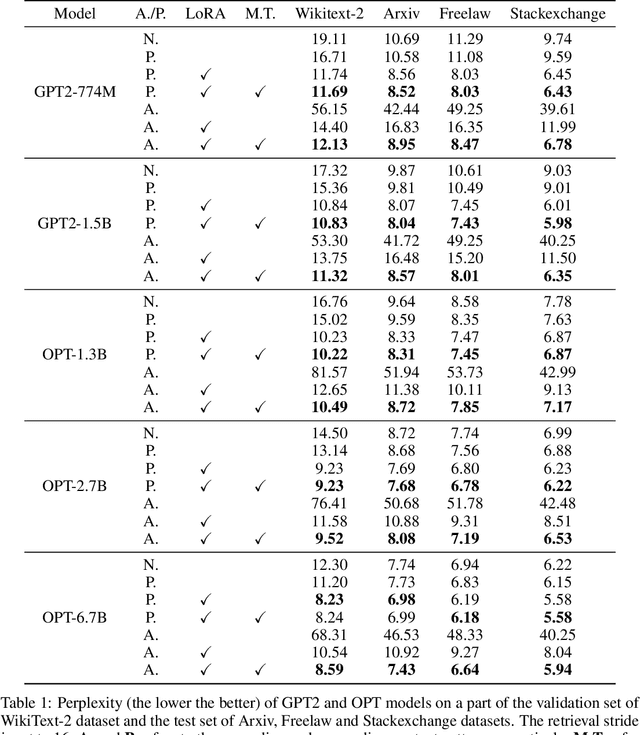
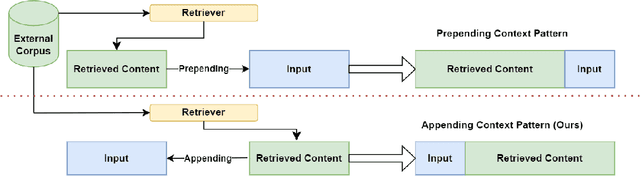
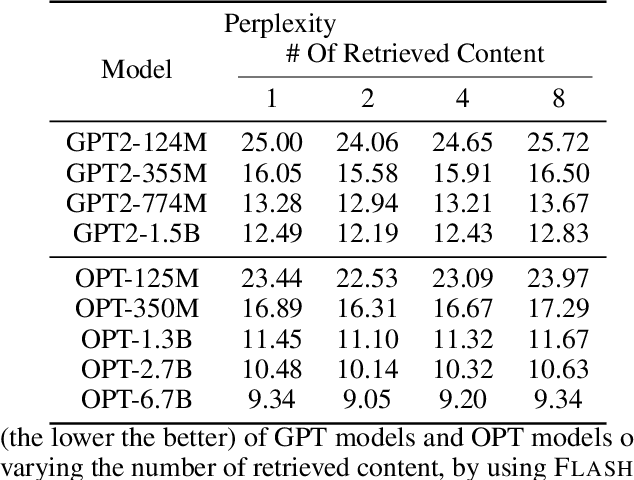
Retrieval-Augmented Language Modeling (RALM) by integrating large language models (LLM) with relevant documents from an external corpus is a proven method for enabling the LLM to generate information beyond the scope of its pre-training corpus. Previous work using utilizing retrieved content by simply prepending retrieved contents to the input poses a high runtime issue, which degrades the inference efficiency of the LLMs because they fail to use the Key-Value (KV) cache efficiently. In this paper, we propose \textsc{FlashBack}, a modular RALM designed to improve the inference efficiency of RALM with appending context pattern while maintaining decent performance after specific fine-tuning without heavily destruct the knowledge integrity of the LLM. \textsc{FlashBack} appends retrieved documents at the end of the context for efficiently utilizing the KV cache instead of prepending them. Our experiment shows that the inference speed of \textsc{FlashBack} is up to $4\times$ faster than the prepending method on a 7B LLM (Llama 2). Via bypassing unnecessary re-computation, it demonstrates an advancement by achieving significantly faster inference speed, and this heightened efficiency will substantially reduce inferential cost. Our code will be publicly available.
MindLLM: Pre-training Lightweight Large Language Model from Scratch, Evaluations and Domain Applications
Oct 29, 2023



Large Language Models (LLMs) have demonstrated remarkable performance across various natural language tasks, marking significant strides towards general artificial intelligence. While general artificial intelligence is leveraged by developing increasingly large-scale models, there could be another branch to develop lightweight custom models that better serve certain domains, taking into account the high cost of training and deploying LLMs and the scarcity of resources. In this paper, we present MindLLM, a novel series of bilingual lightweight large language models, trained from scratch, alleviating such burdens by offering models with 1.3 billion and 3 billion parameters. A thorough account of experiences accrued during large model development is given, covering every step of the process, including data construction, model architecture, evaluation, and applications. Such insights are hopefully valuable for fellow academics and developers. MindLLM consistently matches or surpasses the performance of other open-source larger models on some public benchmarks. We also introduce an innovative instruction tuning framework tailored for smaller models to enhance their capabilities efficiently. Moreover, we explore the application of MindLLM in specific vertical domains such as law and finance, underscoring the agility and adaptability of our lightweight models.