 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashBack:Efficient Retrieval-Augmented Language Modeling for Long Context Inference
May 07, 2024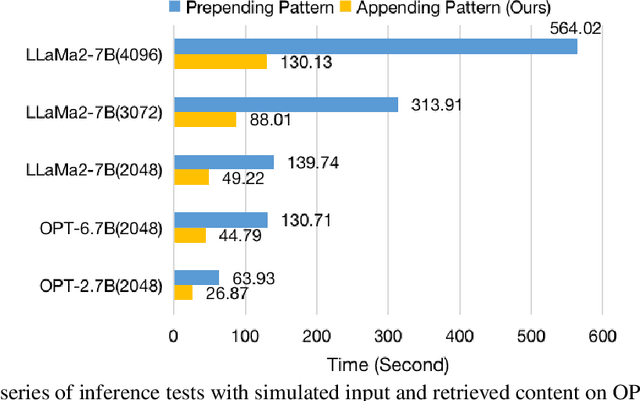
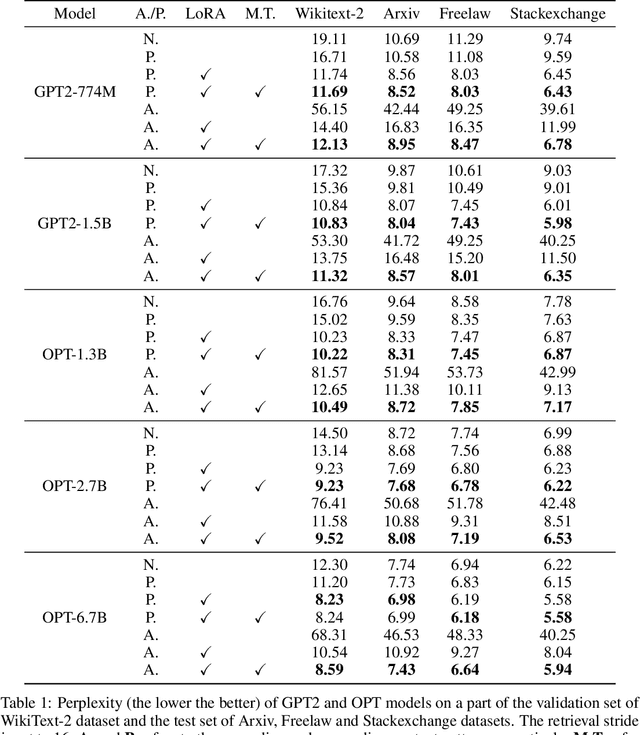
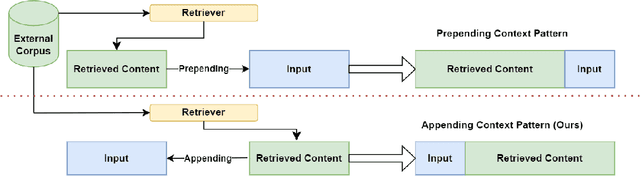
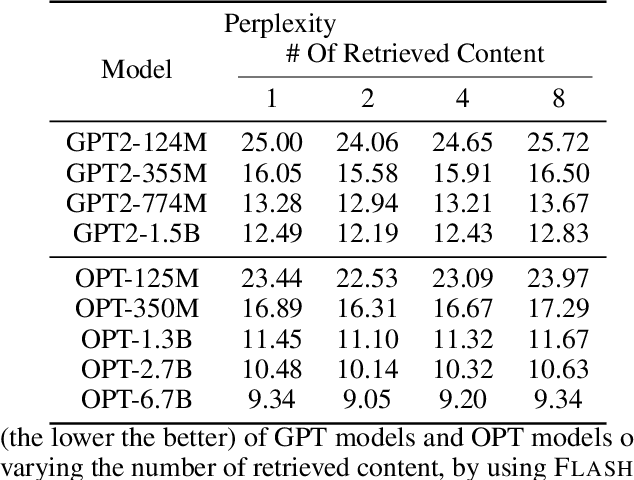
Retrieval-Augmented Language Modeling (RALM) by integrating large language models (LLM) with relevant documents from an external corpus is a proven method for enabling the LLM to generate information beyond the scope of its pre-training corpus. Previous work using utilizing retrieved content by simply prepending retrieved contents to the input poses a high runtime issue, which degrades the inference efficiency of the LLMs because they fail to use the Key-Value (KV) cache efficiently. In this paper, we propose \textsc{FlashBack}, a modular RALM designed to improve the inference efficiency of RALM with appending context pattern while maintaining decent performance after specific fine-tuning without heavily destruct the knowledge integrity of the LLM. \textsc{FlashBack} appends retrieved documents at the end of the context for efficiently utilizing the KV cache instead of prepending them. Our experiment shows that the inference speed of \textsc{FlashBack} is up to $4\times$ faster than the prepending method on a 7B LLM (Llama 2). Via bypassing unnecessary re-computation, it demonstrates an advancement by achieving significantly faster inference speed, and this heightened efficiency will substantially reduce inferential cost. Our code will be publicly available.